- The paper's main contribution is the introduction of budget forcing, a simple test-time intervention that controls compute allocation to enhance reasoning performance.
- It details the creation of the s1K dataset, curated based on quality, difficulty, and diversity, to maximize sample efficiency with minimal data.
- Experimental results on the s1-32B model demonstrate that sequential scaling with budget forcing outperforms traditional parallel methods in achieving competitive performance.
s1: Simple Test-Time Scaling
The paper "s1: Simple test-time scaling" (2501.19393) introduces a straightforward methodology for test-time scaling in LLMs, achieving strong reasoning performance with minimal training data and a novel technique called budget forcing. The key contributions revolve around curating a high-quality dataset and implementing a simple yet effective method to control test-time compute.
s1K Dataset Curation
The authors address the challenge of sample efficiency by creating s1K, a dataset of 1,000 question-reasoning trace pairs. This dataset is meticulously curated from an initial pool of 59K samples, emphasizing three key criteria:

Figure 1: Illustration of the s1K dataset and the sample-efficiency of the s1-32B model.
The selection process involves a three-stage filtering approach, prioritizing quality, difficulty, and diversity. This contrasts with other approaches that rely on large-scale reinforcement learning or SFT with tens of thousands of examples. The focus on data curation aligns with findings from instruction tuning, where the quality of data is paramount.
Test-Time Scaling with Budget Forcing
The paper introduces budget forcing, a simple test-time intervention to control the amount of compute a model expends on a given problem. This technique involves:
This method allows for direct manipulation of the model's thinking duration at test time, enabling the exploration of performance scaling with compute. Budget forcing is classified as a sequential scaling method, where later computations depend on earlier ones.
Experimental Results and Analysis
The effectiveness of s1K and budget forcing is demonstrated through the development of s1-32B, a 32B parameter model finetuned on s1K. The model's performance is benchmarked against various state-of-the-art LMs, including OpenAI's o1-preview, DeepSeek r1, and Qwen's QwQ-32B-preview, using AIME24, MATH500, and GPQA Diamond datasets. The results show that s1-32B achieves competitive performance, particularly on AIME24, surpassing o1-preview by a significant margin with budget forcing. Ablation studies further validate the importance of difficulty, diversity, and quality in the s1K dataset.
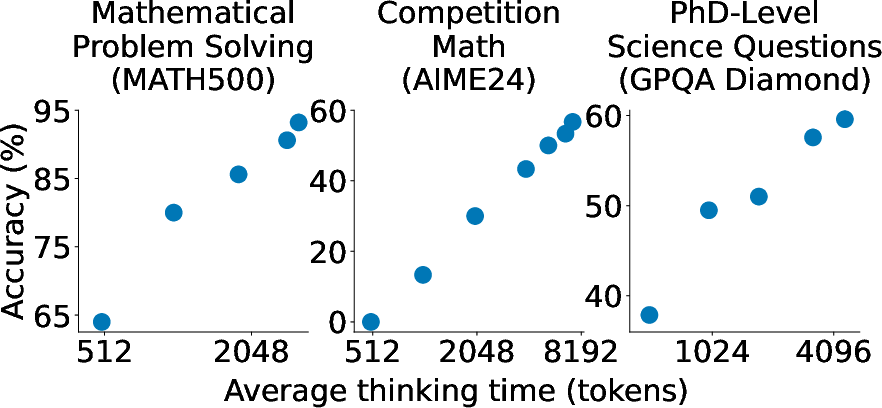
Figure 3: Performance of s1-32B with budget forcing on various reasoning tasks as test-time compute is varied.
The paper defines key metrics for evaluating test-time scaling methods: Control, Scaling, and Performance. Budget forcing excels in providing perfect control and positive scaling, leading to strong overall performance. The results indicate that sequential scaling, exemplified by budget forcing, is more effective than parallel scaling methods like majority voting for Qwen2.5-32B-Instruct.
The budget forcing technique shows promising scaling trends and some extrapolation capabilities, as seen in (Figure 4a). Moreover, (Figure 5) illustrates how sequential and parallel scaling methods affect performance, highlighting the benefits of budget forcing over other techniques like REBASE and majority voting.
Ablation Experiments
Comprehensive ablation experiments are conducted to assess the impact of data curation and test-time scaling methods.
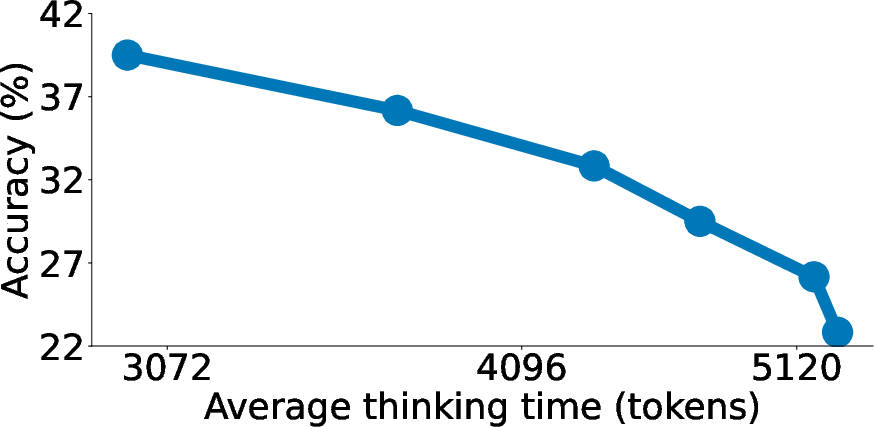
Rejection sampling, surprisingly, exhibits an inverse scaling trend, potentially due to a correlation between shorter generations and the model being on the right track from the start.
Implications and Future Directions
The research demonstrates the feasibility of achieving strong reasoning performance and test-time scaling with limited data and a simple, interpretable method. The success of s1-32B suggests that pretrained models already possess substantial reasoning capabilities that can be activated through targeted finetuning and test-time interventions. The paper highlights the limitations of budget forcing, including context window constraints and the eventual flattening of performance gains. Future research directions include exploring improvements to budget forcing, such as dynamic string selection and combinations with frequency penalties, as well as investigating the application of budget forcing to models trained with reinforcement learning.
Conclusion
The paper "s1: Simple test-time scaling" (2501.19393) makes a compelling case for simple, data-efficient approaches to reasoning in LMs. By introducing s1K and budget forcing, the authors provide a recipe for achieving strong performance and test-time scaling with limited resources. The work's emphasis on transparency and open-source availability fosters further research and development in the field.