- The paper introduces a novel framework enabling independent, layer-specific control in video diffusion models to enhance animation precision.
- The paper leverages an innovative layer curation pipeline—featuring automated segmentation, motion-state hierarchical merging, and motion coherence refinement—to overcome data scarcity.
- Extensive evaluations demonstrate superior performance in preserving visual consistency and smooth transitions, validated through metrics like FID and LPIPS.
LayerAnimate: Layer-level Control for Animation
LayerAnimate introduces a novel approach focusing on fine-grained control of individual animation layers within video diffusion models. This paper presents a framework that enables independent manipulation of foreground and background elements, leveraging a layer curation pipeline to overcome scarcity in layer-specific data.
Introduction
The complexity in animation production often lies in managing various layers, such as foreground and background elements. LayerAnimate provides a solution by enhancing the control over these layers. By utilizing a video diffusion model, this framework distinguishes itself from traditional, monolithic methods by allowing animators to independently manipulate each layer, taking animation quality and usability to a new precision level. The framework's capabilities are illustrated in its ability to seamlessly control transitions and maintain visual consistency in animations.

Figure 1: Given the initial and final images with layers, LayerAnimate enables control over foreground layers and dynamic background switching with smooth transitions.
Layer Curation Pipeline
LayerAnimate's layer curation pipeline addresses the challenge of limited layer-specific data, leveraging automated element segmentation, motion-state hierarchical merging, and motion coherence refinement to produce a curated dataset suitable for training.
Automated Element Segmentation
Utilizing visual foundation models such as SAM, the framework automatically segments element masks from animation frames. These masks, propagated through the animation sequence, ensure consistent element extraction across frames.
Motion-state Hierarchical Merging
This process merges over-segmented elements based on motion scores calculated through optical flow. It cleverly balances computational efficiency and usability by limiting the number of layers to a manageable size without compromising the motion consistency inherent in animation.
Motion Coherence Refinement
LayerAnimate refines its dataset by employing a more robust measure of motion transitions using optical flow magnitudes, overcoming limitations of tools like PySceneDetect in detecting scene changes due to animation's unique visual style.
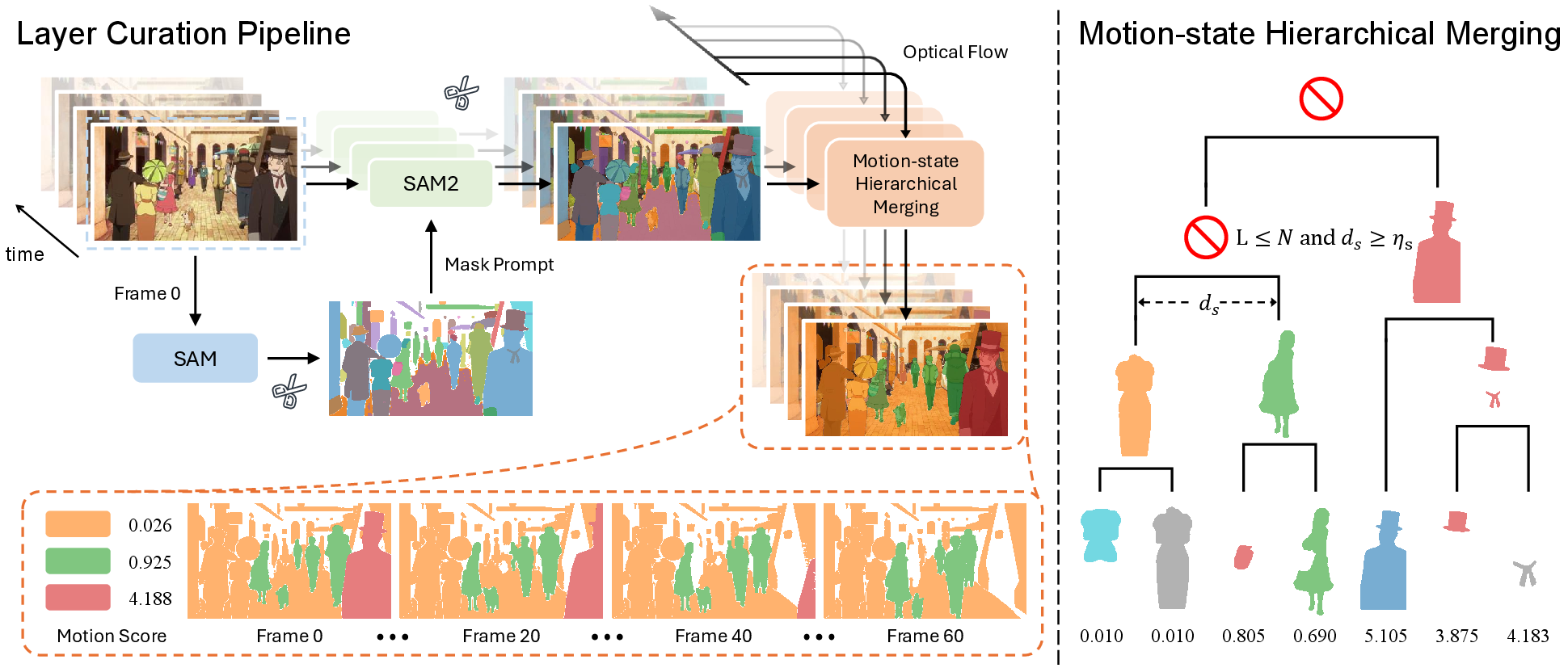
Figure 2: Left: Layer Curation Pipeline. The bottom shows the curated layer masks with their motion scores.
Architecture of LayerAnimate
LayerAnimate operates within a video diffusion model framework that supports sophisticated control over layer dynamics.
Motion-state Allocation
A pivotal feature of LayerAnimate is motion-state allocation, categorizing layers into dynamic and static. This categorization stabilizes static layers while guiding dynamic ones based on provided motion scores or sketch inputs, thereby allowing nuanced control over animation sequences.
Integration through Layer ControlNet
The framework encodes layer-specific latents and combines them through masked layer fusion attention within a UNet, integrating multiple layers' features to guide the animation process effectively.
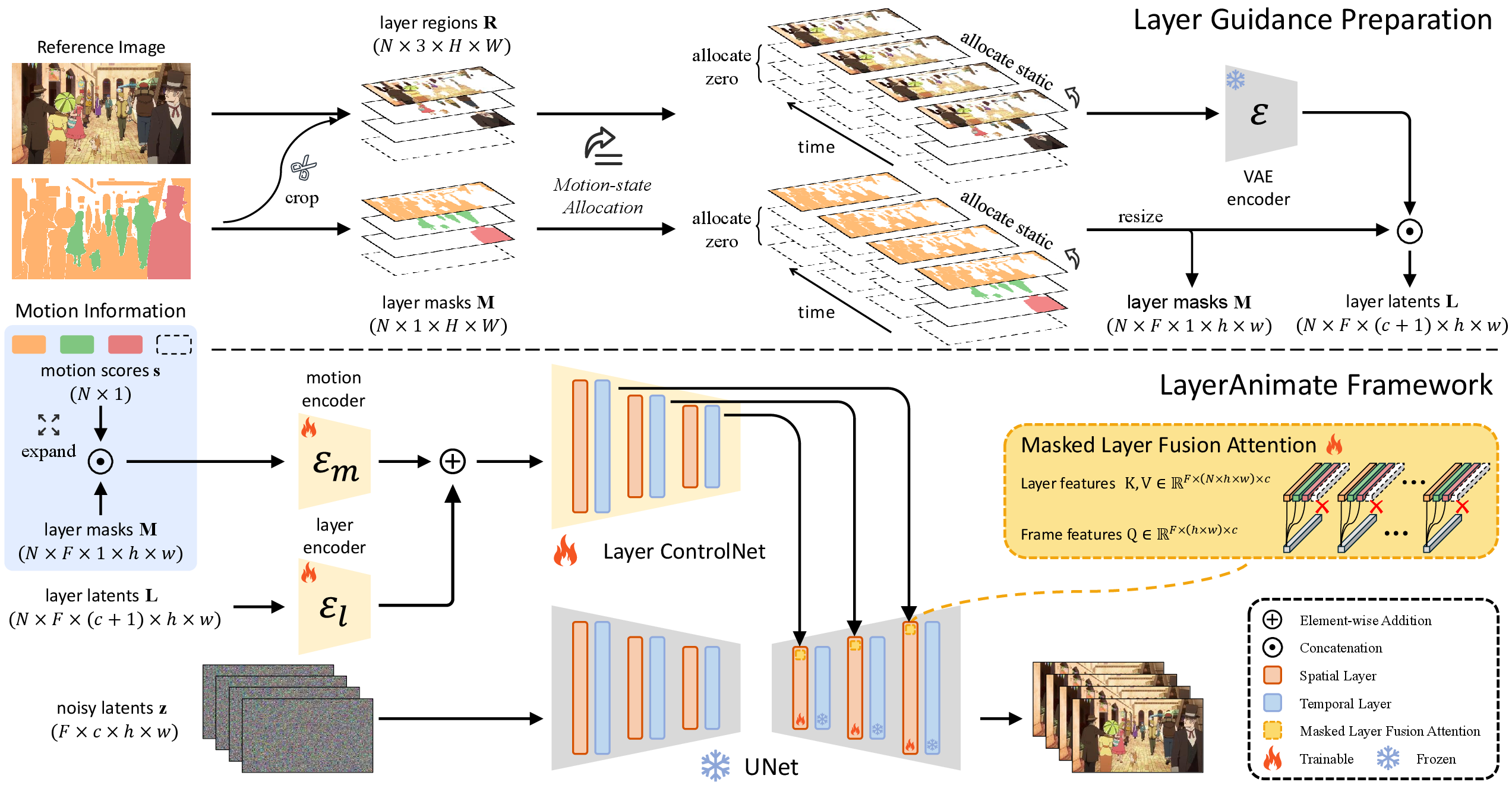
Figure 3: Overview of LayerAnimate. Given reference images, layer masks, and their motion information, LayerAnimate enables animation generation with precise layer-specific control.
Evaluation and Results
Extensive testing reveals LayerAnimate's superior performance across various video generation tasks, from frame interpolation to sketch-guided animations, outperforming contemporary models like SEINE and DynamiCrafter in maintaining visual quality and precision.
Quantitative Analysis
Metrics such as FVD, FID, and LPIPS indicate LayerAnimate's proficiency in producing temporally coherent and visually accurate animations, with layer control playing a significant role in Error Reduction.

Figure 4: Qualitative comparison with other competitors, demonstrating LayerAnimate's superior capabilities in handling complex animation scenarios.
User Study
In a user study, LayerAnimate was favored for its ease of use and the quality of generated animations, matching or surpassing expectations set by other sophisticated models like LVCD, which uses more detailed sketches.
Innovative Applications
Layer-specific control enables several novel applications, such as dynamically switching backgrounds or stabilizing specific elements within animations. These capabilities offer animators unprecedented creative flexibility.

Figure 5: Layer-specific Application. LayerAnimate enables innovative control options like freezing specific elements and animating layers with partial sketches.
Conclusion
LayerAnimate extends the boundaries of animation production by enabling detailed layer control in video generation models. Its robust layer curation and manipulation framework provides new creative possibilities and improves both the usability and precision of animation tasks, offering valuable insights for future developments in animation technology.

