- The paper introduces a novel approach that leverages compositional generalization to enable MLLMs to interpret unseen medical image combinations.
- The study employs the Med-MAT dataset to assess model performance with limited labeled data, evidencing improvements through structured evaluation.
- The findings indicate enhanced data efficiency and versatile integration across various MLLM architectures, suggesting promising future implications.
Exploring Compositional Generalization of Multimodal LLMs for Medical Imaging
The advancement of Multimodal LLMs (MLLMs) has paved the way for significant applications in the medical field, where their integration with medical imaging data stands as a promising frontier. The paper "Exploring Compositional Generalization of Multimodal LLMs for Medical Imaging" (2412.20070) introduces an innovative approach to overcome a typical limitation in medical imaging: the scarcity of labeled data for rare medical conditions. This research leverages compositional generalization (CG) – a model's ability to interpret new combinations by recombining learned elements – to enhance the application of MLLMs in medical imaging.
Understanding Compositional Generalization
Compositional Generalization (CG) refers to a model's capacity to understand and generate novel combinations of known components. In the context of medical imaging, images are characterized by a triplet consisting of Modality, Anatomical area, and Task (referred to as MAT-Triplet). CG exploits the interdependencies within these elements, allowing MLLMs to extrapolate from existing images to those with unseen combinations.
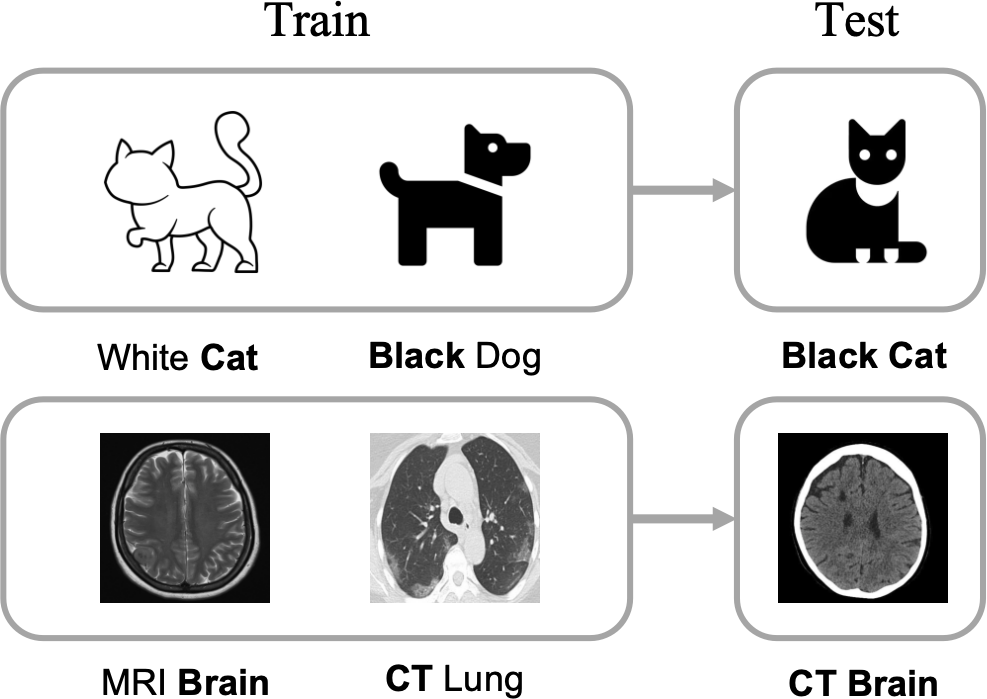
Figure 1: Examples of Compositional Generalization: The model is required to understand unseen images by recombining the fundamental elements it has learned.
The Med-MAT Dataset
To investigate CG in medical imaging, a large dataset named Med-MAT was created, comprising 106 medical datasets, each annotated with the MAT-Triplet. This dataset forms 53 subsets corresponding to different combinations of modalities, anatomical regions, and tasks, and is publicly available for research use.
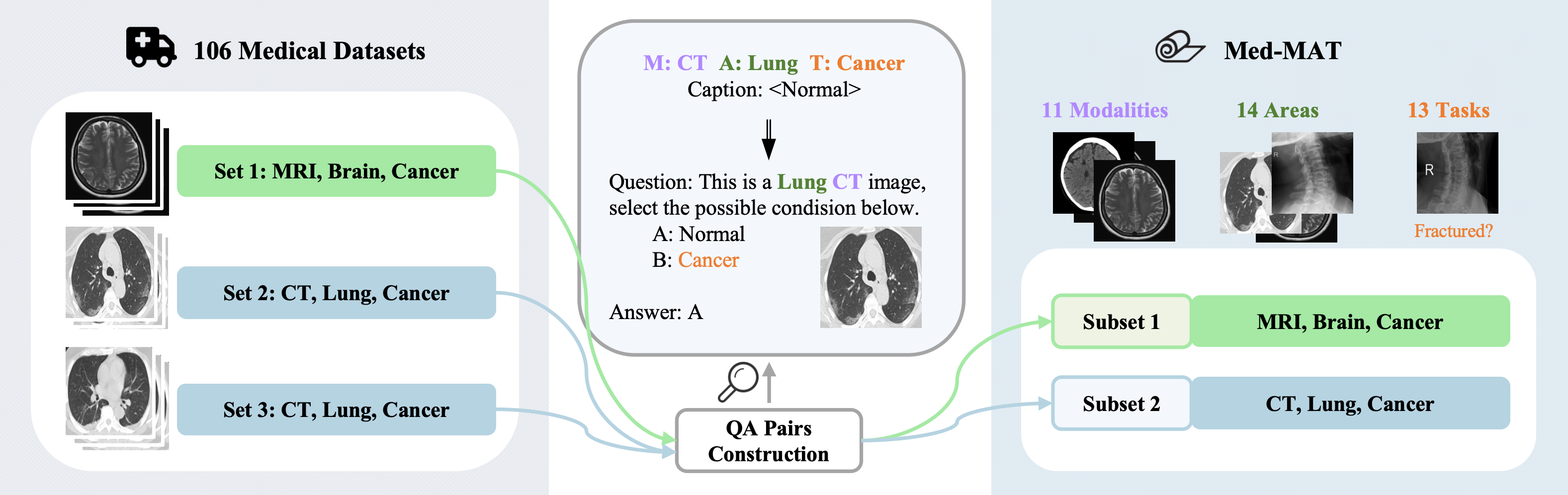
Figure 2: The process of integrating a vast amount of labeled medical image data to create Med-MAT.
Methodology and Experimentation
The research involved analyzing how MLLMs perform when tasked with interpreting target data through training on related datasets within the Med-MAT. By designating certain datasets as target data, the study observed how related and unrelated dataset compositions affect the model's performance. A particular focus was placed on the understanding of unseen medical images by disrupting CG intentionally to assess its impact on generalization.
The experiments highlighted that MLLMs could effectively leverage CG to understand new image combinations beyond the data they were explicitly trained on. The use of CG significantly improved performance, especially when ample combination data was available, underscoring its potential for enhancing generalization in multi-task training scenarios.
Results and Observations
The study demonstrated several key findings:
- Enhanced Generalization through CG: The introduction and expansion of CG combinations led to improved model performance in classifying target data, signifying the efficacy of CG in enhancing generalization abilities.
- Data-Efficient Training: CG facilitated data-efficient training, enabling models to learn effectively with limited data availability, particularly beneficial in scenarios lacking vast quantities of labeled images.
- Versatility Across Different MLLM Backbones: The research found that CG benefits persist across various MLLM architectures, confirming its broad applicability and potential integration into diverse AI systems in medical imaging.
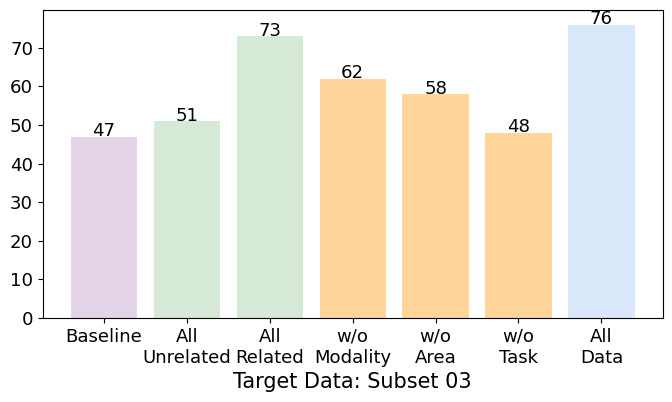
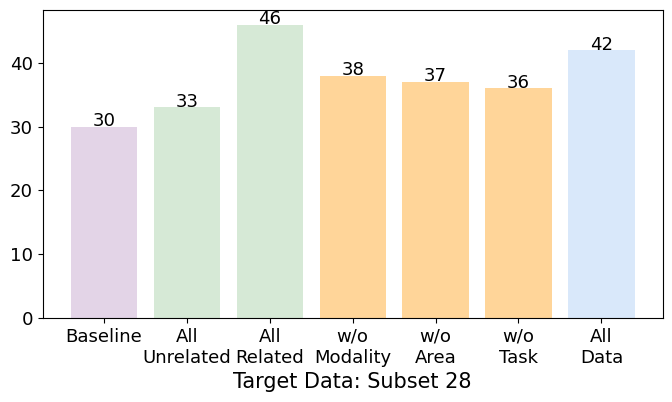
Figure 3: Accuracy results on the Target dataset for various models. 'All Related/Unrelated' models are trained on all the related or unrelated datasets of the Target Data. 'w/o Modality/Area/Task' are trained on All Related datasets but omit those sharing the same element as the Target Data, to intentionally disrupt CG. 'All Data' uses all available training sets. (Note: The Target Data is excluded from training to observe generalization.)
Future Implications
This research fuels the potential for more refined, efficient medical image analysis, especially in detecting and diagnosing conditions with scarce data availability. The findings suggest pathways for enhancing MLLM applicability in various multimodal domains beyond medical imaging, potentially impacting other fields requiring complex data interpretation.
Conclusion
The study provides compelling evidence of the benefits of employing compositional generalization within MLLMs for medical imaging, leading to improved model versatility and generalization. The Med-MAT dataset offers a valuable resource for future investigations into MLLM capabilities. As research progresses, refining CG approaches could markedly improve AI applications in not only medical diagnostics but also broader contexts requiring nuanced data synthesis and interpretation.

