- The paper introduces TALE, a novel framework that dynamically estimates token budgets to optimize Chain-of-Thought reasoning in LLMs.
- It employs a zero-shot estimator and binary search to balance token costs and accuracy, achieving a 68.64% reduction in token usage.
- TALE demonstrates versatility across various LLM architectures, ensuring efficient and cost-effective performance in real-world applications.
Token-Budget-Aware LLM Reasoning
This paper introduces a framework called TALE that addresses token redundancy in Chain-of-Thought (CoT) reasoning for LLMs. The key contribution of this research is the dynamic estimation of token budgets that guide the reasoning process in LLMs, thereby balancing efficiency and accuracy.
Introduction to Token-Budget-Aware Framework
The TALE framework leverages token budget estimation to optimize the CoT reasoning process in LLMs. The central premise is that the reasoning processes of current LLMs are unnecessarily lengthy, leading to substantial overhead in token usage. By incorporating token budget constraints into the prompts, TALE aims to reduce token costs while maintaining high performance. This is achieved through dynamic estimation of token budgets based on the complexity of reasoning tasks.
Methodology
Workflow of TALE
TALE consists of two main components: budget estimation and prompt construction. The process begins by estimating a token budget for a given question, after which a token-budget-aware prompt is crafted. This prompt combines the question with the estimated budget, guiding the LLM to generate a concise yet accurate answer.

Figure 1: The workflow of TALE. Given a question, TALE first estimates the token budget using a budget estimator. It then crafts a token-budget-aware prompt by combining the question with the estimated budget. Finally, the prompt is input to the LLM to generate the answer as the final output.
Budget Estimation Techniques
TALE utilizes a zero-shot estimator mechanism, where the reasoning LLM itself estimates the number of tokens required for an answer. This approach mirrors human reasoning, where the effort required to solve a problem can be estimated at a glance. For precise budget estimation, regression models and internalizing budget constraints during LLM fine-tuning are also explored.
Optimal Token Budget Search
To achieve optimal budget estimation, a binary search method identifies the minimal budget needed to maintain accuracy while minimizing token costs. This process reveals a phenomenon termed "Token Elasticity," where exceedingly small token budgets result in higher token consumption due to the LLM's inability to follow the specified budget constraints.
Evaluation
Effectiveness of TALE
TALE was evaluated across several datasets, demonstrating a notable reduction in token costs. On average, TALE achieved a 68.64% reduction in token usage with less than a 5% decrease in accuracy compared to vanilla CoT. This efficiency in token usage translates directly to lower computational costs, making TALE a compelling choice for scenarios requiring budget-conscious reasoning.
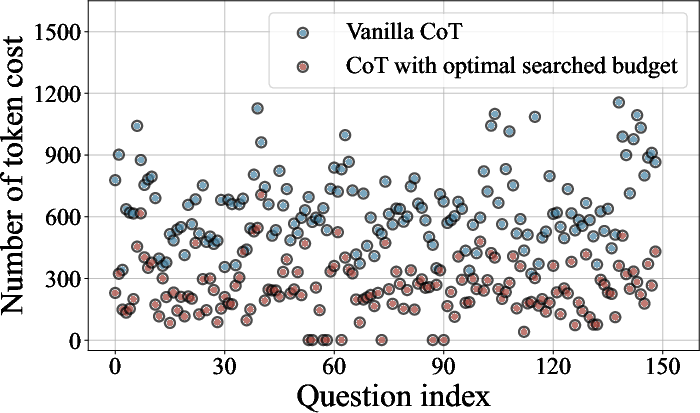
Figure 2: The effects of optimal searched budget. CoT with our optimal searched budget reduces the token costs significantly without influencing the accuracy.
Generalization Across LLMs
TALE's ability to generalize across different LLM architectures was also analyzed. The framework maintained its cost-efficiency while delivering high performance across models like Yi-lightning and GPT-4 variants. This adaptability showcases TALE's potential for diverse applications in real-world LLM deployments.
Conclusion
In conclusion, TALE introduces a novel approach to managing token costs in CoT reasoning by incorporating budget awareness into the prompting process. This method not only preserves accuracy but also significantly reduces computational expenses. Future developments may involve refining budget estimation techniques and exploring broader applications of budget-aware reasoning in LLMs.