- The paper introduces a novel method that leverages video super-resolution models to improve spatial consistency in 3D reconstructions from low-resolution multi-view images.
- It details a greedy algorithm for sequencing image frames, refined with adaptive-length subsequence generation to mitigate abrupt transitions and rendering artifacts.
- Experimental evaluations on NeRF-synthetic and Mip-NeRF 360 datasets demonstrate superior performance in PSNR, SSIM, and LPIPS compared to traditional methods.
Sequence Matters: Harnessing Video Models in 3D Super-Resolution
Introduction and Background
This paper discusses a novel approach to 3D super-resolution by leveraging Video Super-Resolution (VSR) models to enhance the consistency and quality of 3D reconstructions from low-resolution (LR) multi-view images. Traditional 3D reconstruction methods, such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS), require high-resolution images to generate high-fidelity 3D models. However, acquiring such images is often impractical in real-world scenarios due to equipment and environmental limitations.
The paper identifies the potential of VSR models, originally designed for temporal consistency in video enhancement, to address spatial consistency across multi-view images by referencing adjacent frames. Recent works have demonstrated that VSR alongside 3DGS can overcome the limitations of Single-Image Super-Resolution (SISR) models that process images independently, thereby enhancing multi-view coherence.
Proposed Methodology
Rendering Artifacts and Initial Observations
The paper identifies a critical issue when using rendered LR videos for VSR: the occurrence of stripy or blob-like artifacts. These artifacts, depicted in (Figure 1), arise from the mismatch between the rendered LR video frames (e.g., from 3DGS) and the VSR models' training data (natural LR videos). Addressing this challenge without the computational overhead of fine-tuning VSR models on rendered datasets presents a novel operational methodology.

Figure 1: Illustration of stripy or blob-like artifacts generated in VSR outputs of LR videos rendered from 3DGS.
Greedy Algorithm for Image Sequence Ordering
To mitigate the rendering artifact issue without intensive training or fine-tuning, a simple greedy algorithm is introduced for ordering images into a video-like sequence. This algorithm orders frames by feature or positional similarity, although it suffers from abrupt transitions due to its greedy nature. Abrupt transitions (as demonstrated in Figure 2) are primarily addressed through an adaptive-length subsequence approach.
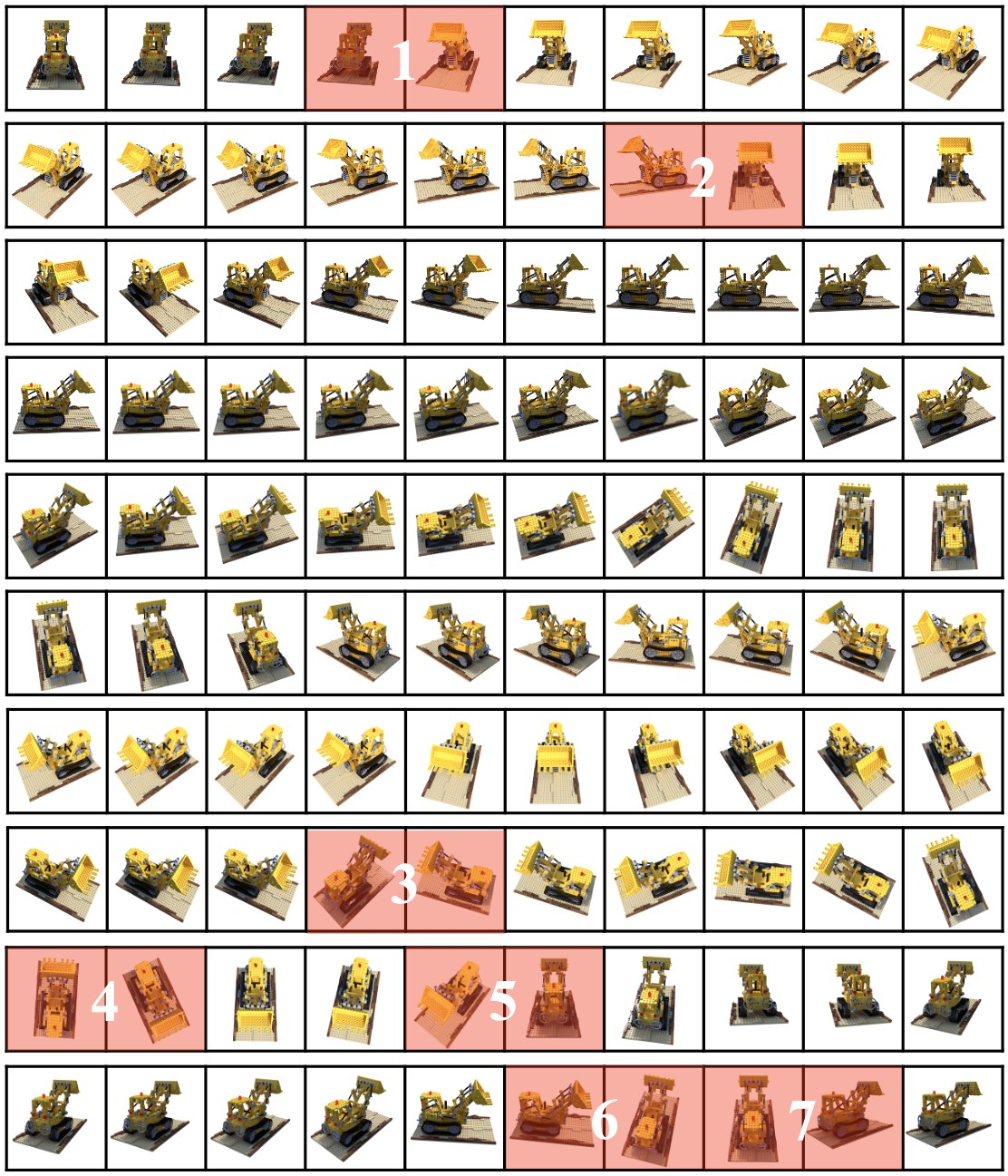
Figure 2: An example result from the simple greedy algorithm applied to the NeRF-synthetic dataset. Two neighboring images highlighted in red demonstrate abrupt transitions caused by misalignments.
Adaptive-Length and Multi-Threshold Subsequence Generation
Addressing the shortcomings of the greedy algorithm, the paper proposes an adaptive-length subsequence generation strategy. This strategy uses pose and feature-based similarity metrics to produce smoother transitions, complemented by multi-threshold criteria to maintain a balance between sequence smoothness and completeness. Figure 3 shows the improved subsequence generation, effectively handling the artifacts from abrupt transitions.
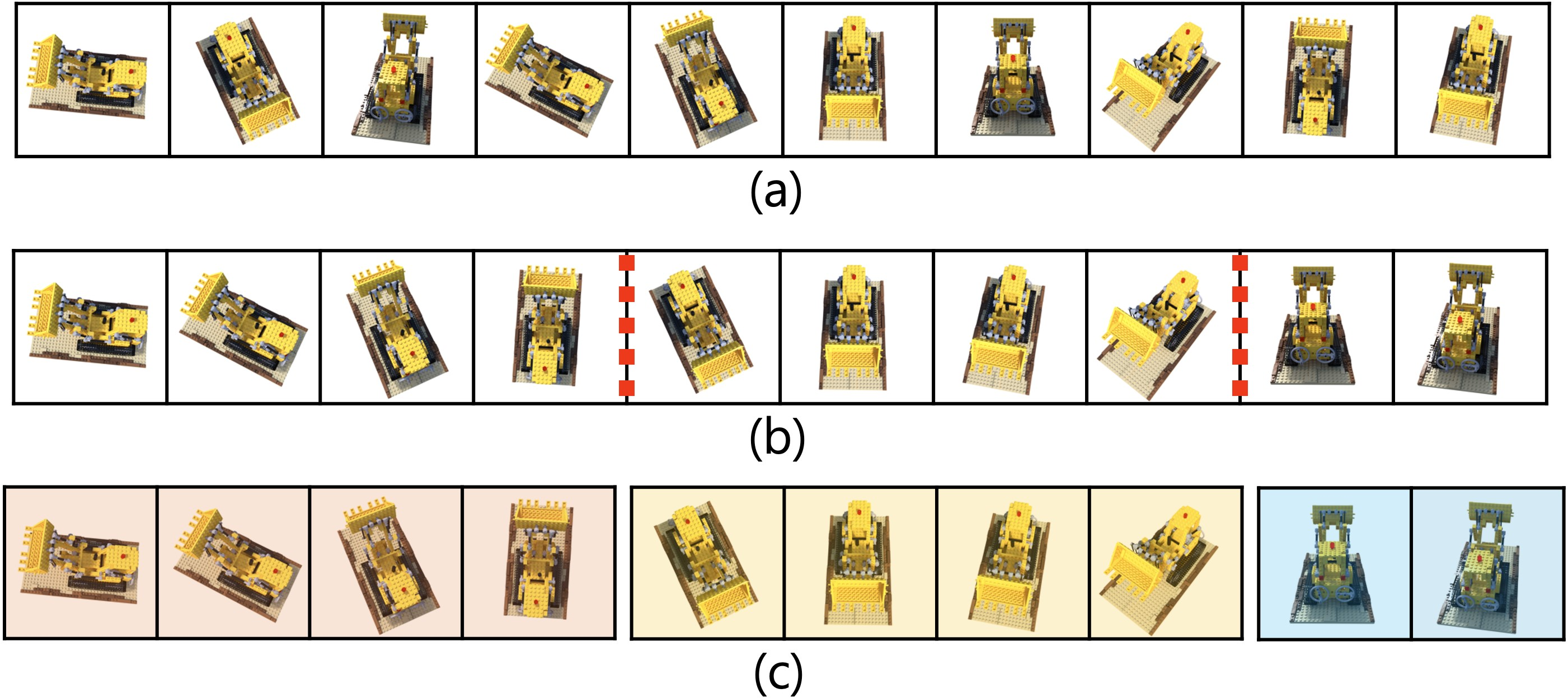
Figure 3: Illustration of subsequence generation showing a more coherent transition compared to the simple greedy algorithm.
Experimental Validation
Datasets and Baselines
The experiments utilize the NeRF-synthetic and Mip-NeRF 360 datasets, with evaluation metrics including PSNR, SSIM, and LPIPS. The proposed method demonstrates superior performance in spatial and temporal consistency metrics, as visualized in Figure 4 and Figure 5, indicating high-resolution image generation quality.

Figure 4: Qualitative results on the NeRF-synthetic dataset showing superior PSNR values against ground truth (GT).

Figure 5: Qualitative results on Mip-NeRF 360 dataset emphasizing superior performance for high-frequency details.
Comparisons with Baseline Models
The results reveal that the proposed method significantly outperforms current baselines, especially regarding high-frequency details crucial for accurate 3D model reconstructions. The adaptive approach effectively prevents the artifact propagation seen in conventional methods like SuperGaussian and NeRF-SR.
Conclusion
In conclusion, the paper presents a computationally efficient method for enhancing 3D super-resolution leveraging VSR models. The introduced algorithms circumvent the challenges of artifact-prone LR sequences by producing structured sequences that do not necessitate VSR model fine-tuning. Experimental results underscore the method's efficacy across multiple high-fidelity datasets, providing a promising direction for future advancements in 3D reconstruction applications. The implications of deploying such methods extend to various fields requiring spatially consistent high-resolution 3D representations from limited data sources.