- The paper develops an adaptive reward shaping mechanism using LTL and DFA to deliver intermediate rewards and address sparse reward challenges.
- It leverages co-safe LTL specifications, dynamically adjusting reward functions to improve convergence rates and policy robustness.
- Experimental results show faster convergence and superior performance across diverse discrete and continuous robotic environments.
Adaptive Reward Design for Reinforcement Learning in Complex Robotic Tasks
Minjae Kwon, Ingy ElSayed-Aly, and Lu Feng have presented a paper detailing the development of reward functions tailored for reinforcement learning (RL) agents tasked with complex robotic applications. This paper addresses the prevalent issue of sparse rewards in existing methodologies, which mandate exhaustive exploration for policy optimization. Their novel approach incorporates the use of Linear Temporal Logic (LTL) specifications to incentivize RL agents in a manner that accelerates task convergence while enhancing policy quality and task success rates.
Introduction to Reward Function Design
The paper introduces a reward design framework for RL in the context of robotic tasks, emphasizing the complexity inherent in such tasks. Traditional RL paradigms rely on sparse rewards directly tied to task completion, limiting their applicability due to inefficient exploration phases. The integration of formal languages such as LTL allows for a more structured specification of tasks, with the potential to derive intermediate rewards. However, existing solutions often exhibit constraints related to algorithm specificity and reward sparsity.
Reward shaping has shown promise in expediting convergence by delivering intermediate rewards as agents approach their goals. Inspired by this concept, the authors propose an adaptive reward shaping mechanism, leveraging LTL specifications to continuously update reward functions during training phases. This approach facilitates the consistent attainment of improved policies applicable across diverse RL algorithms and robotic scenarios.
Methodology
Co-Safe LTL Specifications
The authors leverage the syntactically co-safe LTL fragment, focusing on task specifications defined by logical formulas that are progressively satisfied in finite traces. These specifications are translated into deterministic finite automata (DFA), allowing task progression to be efficiently tracked via distance-to-acceptance metrics.
Adaptive Reward Function Design
Adaptive progression and hybrid reward functions are introduced, crafted from updated DFA distance values. This dynamic computation aims to reflect the actual difficulty experienced in activating DFA transitions across varying environments.
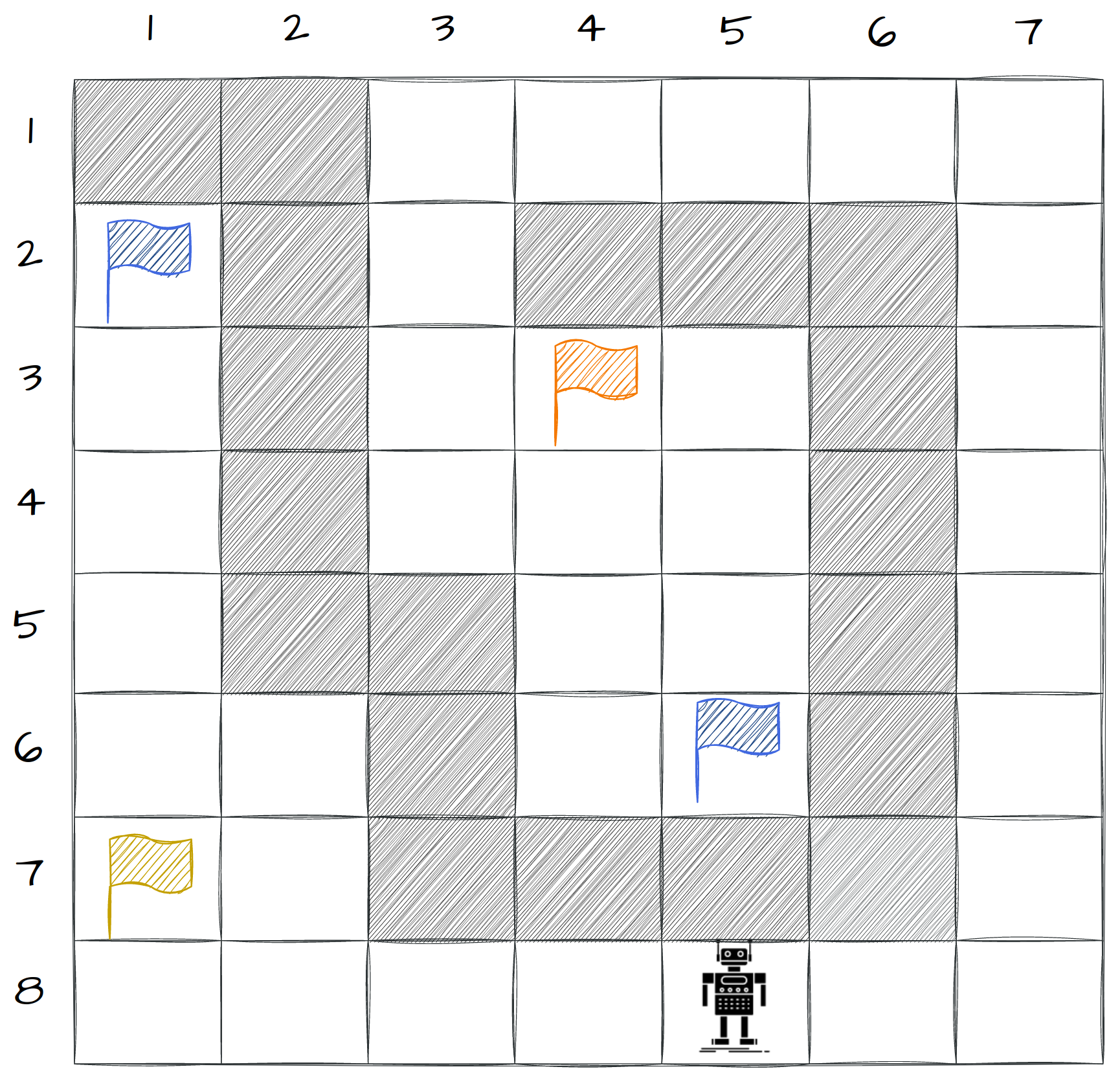
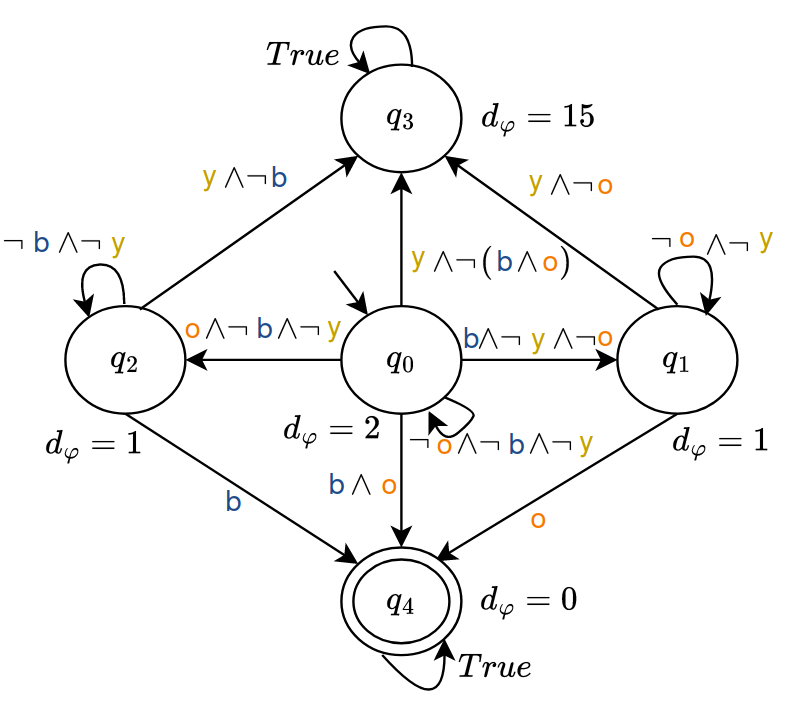
Figure 1: Gridworld environment utilized to demonstrate task specifications and reward function dynamics.
Updating Mechanisms
Upon evaluating task success rates over episodes, the model dynamically adjusts distance values within the DFA. These adjustments are driven by an average success rate threshold λ, influencing the progressive updating process.
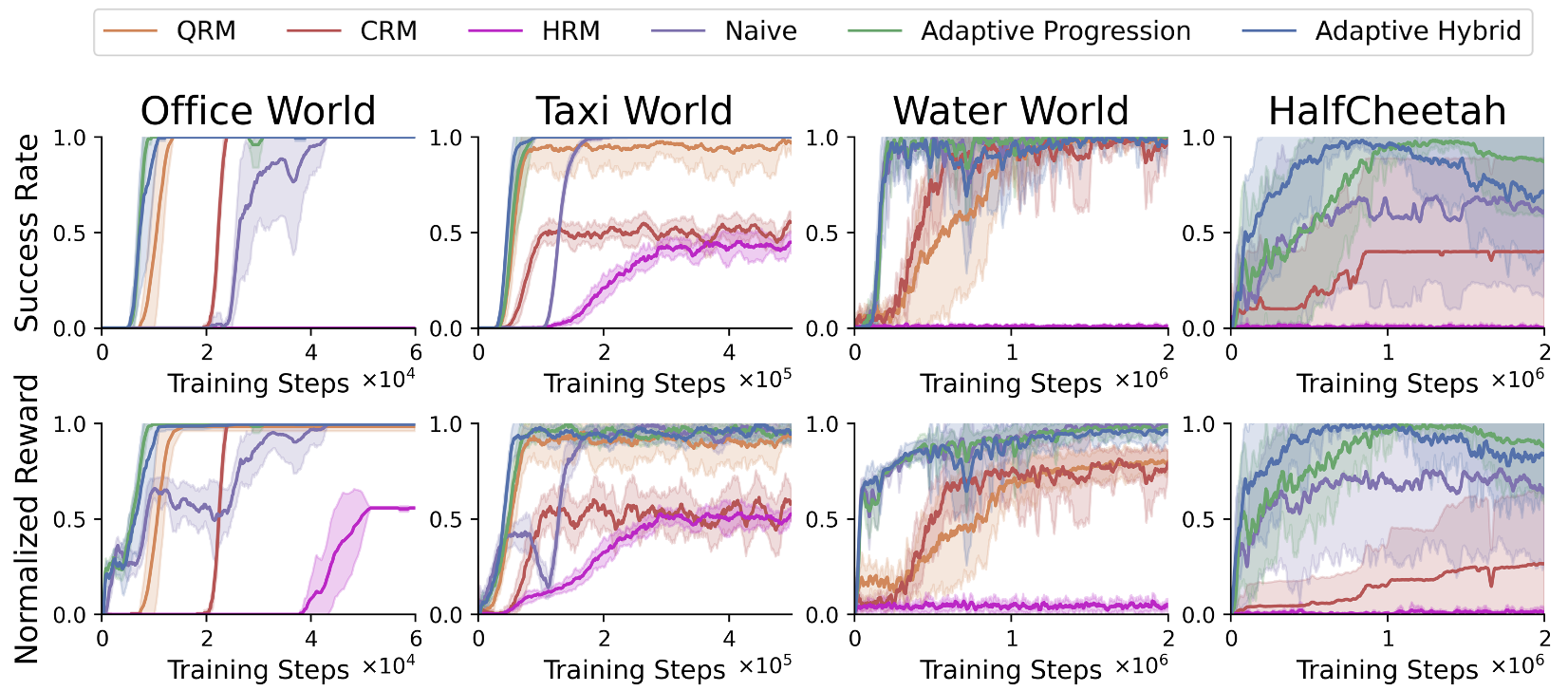
Figure 2: Results demonstrating the efficacy of adaptive reward design in deterministic environments.
Experimental Evaluation
The authors conducted extensive experiments across a suite of RL domains encompassing both discrete and continuous environments. These domains range from grid-based tasks such as office world and taxi world to continuous challenges like water world and HalfCheetah.
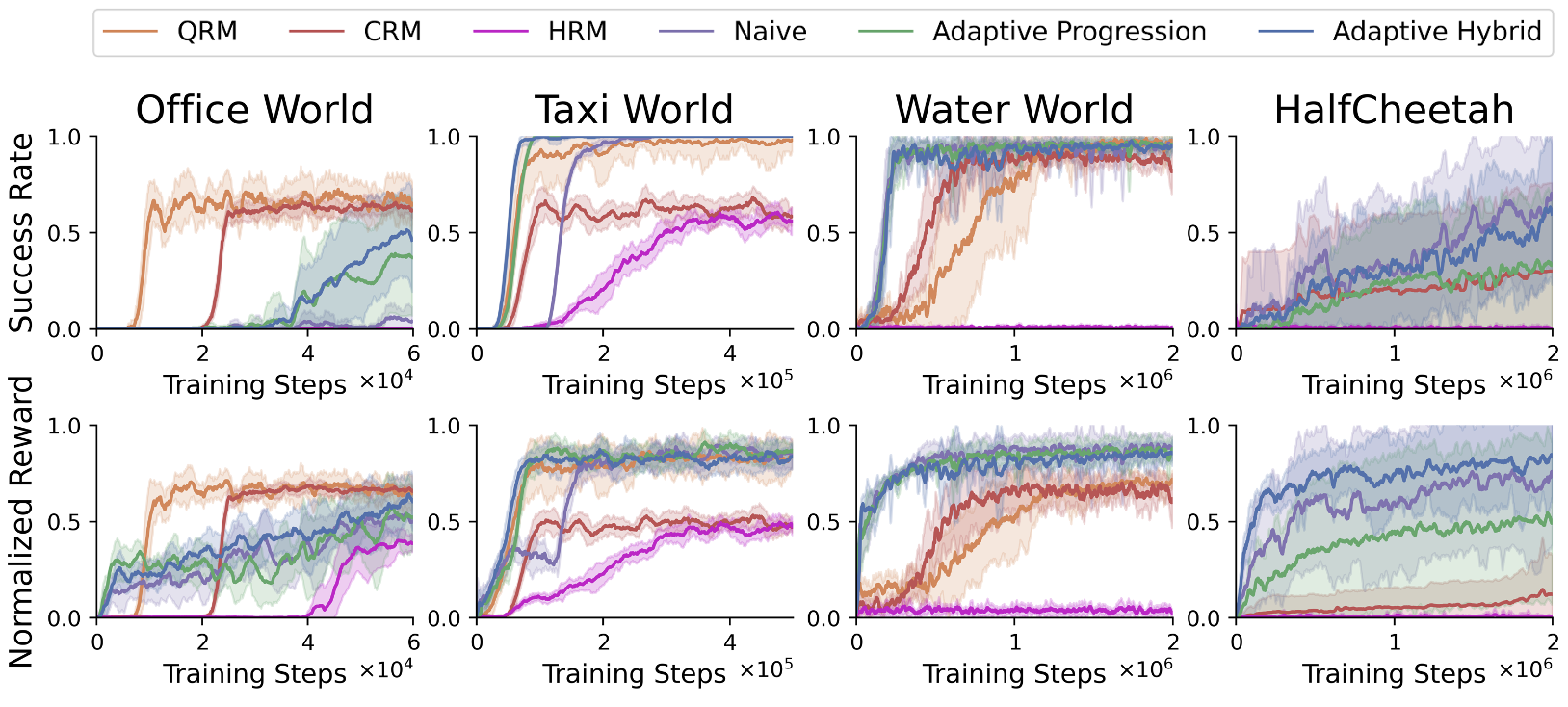
Figure 3: Results depicting the robust performance in noisy environments, showcasing the adaptability and resilience of the reward functions.
Observations and Implications
The adaptive reward shaping methodology consistently outperformed various baselines, securing faster convergence rates and equipping RL agents with strong policies capable of handling intricate tasks. Notably, the adaptive hybrid reward function exhibited superior performance in most circumstances.
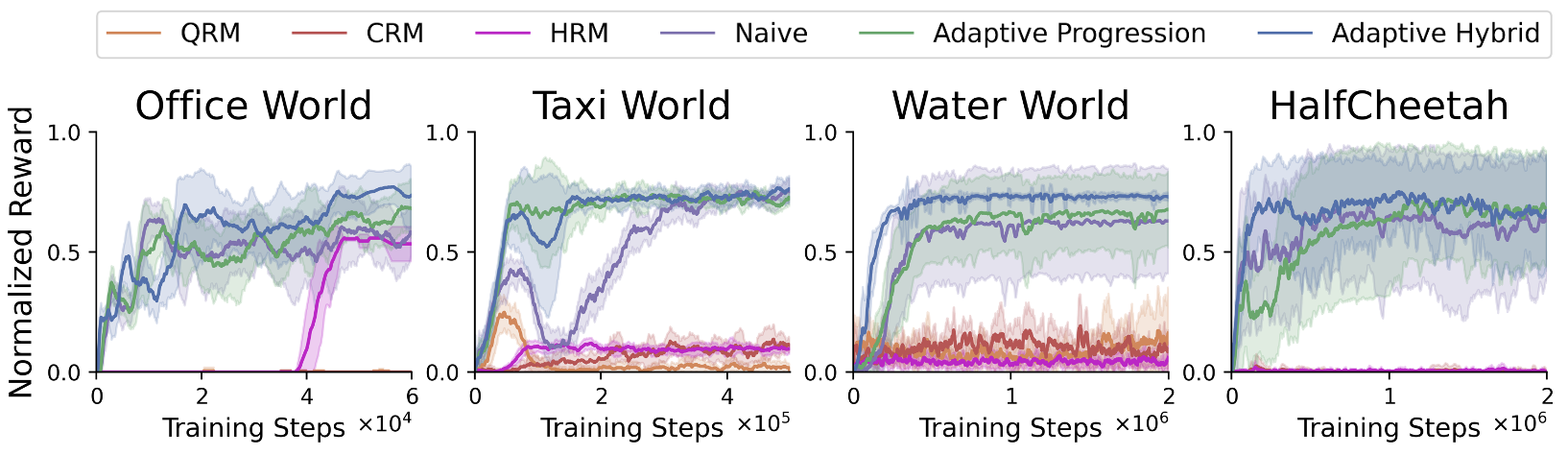
Figure 4: Performance metrics highlighting the adaptability of reward design in infeasible environmental contexts.
The implications of this work extend beyond theoretical enhancements. The approach can significantly advance practical RL applications, particularly those demanding high-level task comprehension and efficiency in exploration. The potential for deployment in real-world robotics, autonomous navigation, and complex system control underscores the transformative capability of these methodologies.
Conclusion
The paper delivers a compelling case for the adoption of adaptive reward design frameworks in RL scenarios governed by complex robotic tasks. The proposed method demonstrates compatibility with various RL algorithms and adaptability across discrete and continuous domains. Anticipated future work will expand these methodologies across broader robotic tasks and explore implementations in real-world settings.
This work positions itself as a pivotal contribution to the RL research field, providing a robust foundation for developing efficient, scalable robotic systems capable of navigating intricate task landscapes with precision and efficacy.