- The paper introduces a unified framework that leverages pre-trained LLMs and finite scalar quantization to generate semantic-level speech tokens with human-like quality.
- The paper simplifies the architecture by removing text encoders and integrates a chunk-aware causal flow matching model, enabling nearly lossless real-time synthesis.
- The paper validates CosyVoice 2 on diverse datasets, demonstrating superior content accuracy, speaker fidelity, and latency performance compared to state-of-the-art models.
CosyVoice 2: Advances in Streaming Speech Synthesis with LLMs
Introduction
The paper "CosyVoice 2: Scalable Streaming Speech Synthesis with LLMs" (2412.10117) presents an improved multilingual speech synthesis framework, building upon its predecessor, CosyVoice. CosyVoice achieved notable success using discrete speech tokens; CosyVoice 2 advances this by incorporating systematic optimizations facilitating streaming synthesis—critical for interactive applications. The developments include finite scalar quantization for better token utilization, simplified architecture utilizing pre-trained LLMs, and a chunk-aware flow matching model addressing diverse scenarios. These innovations elevate synthesis quality to human parity, minimizing latency, making CosyVoice 2 suitable for real-time applications.
Architecture and Key Innovations
A Unified Framework
CosyVoice 2 harmonizes streaming and non-streaming synthesis. Utilizing a unified framework, it integrates a text-speech LLM (Figure 1), which, through autoregressive processing, generates semantic-level speech tokens from text prompts.
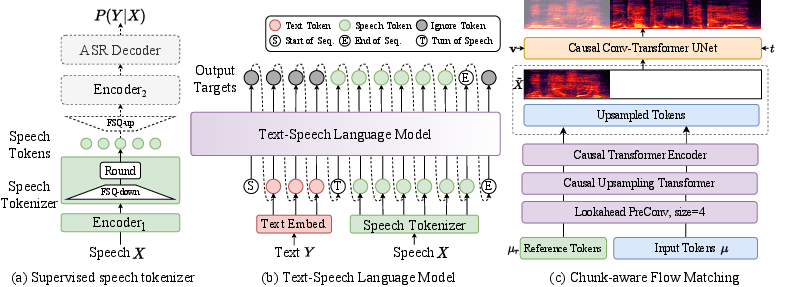
Figure 1: An overview of CosyVoice 2 architecture demonstrating the supervised speech tokenizer, unified text-speech LLM, and chunk-aware causal flow matching model.
The architecture is further simplified by removing previously essential components like text encoders and speaker embeddings. Pre-trained LLMs serve as a robust backbone, enhancing context understanding and enabling nuanced and versatile speech generation.
Finite Scalar Quantization (FSQ)
A pivotal enhancement is the transition from vector quantization (VQ) to finite scalar quantization (FSQ), which improves codebook utilization drastically. FSQ quantizes projections into low-rank spaces, resulting in maximized semantic fidelity without compromising acoustic quality.
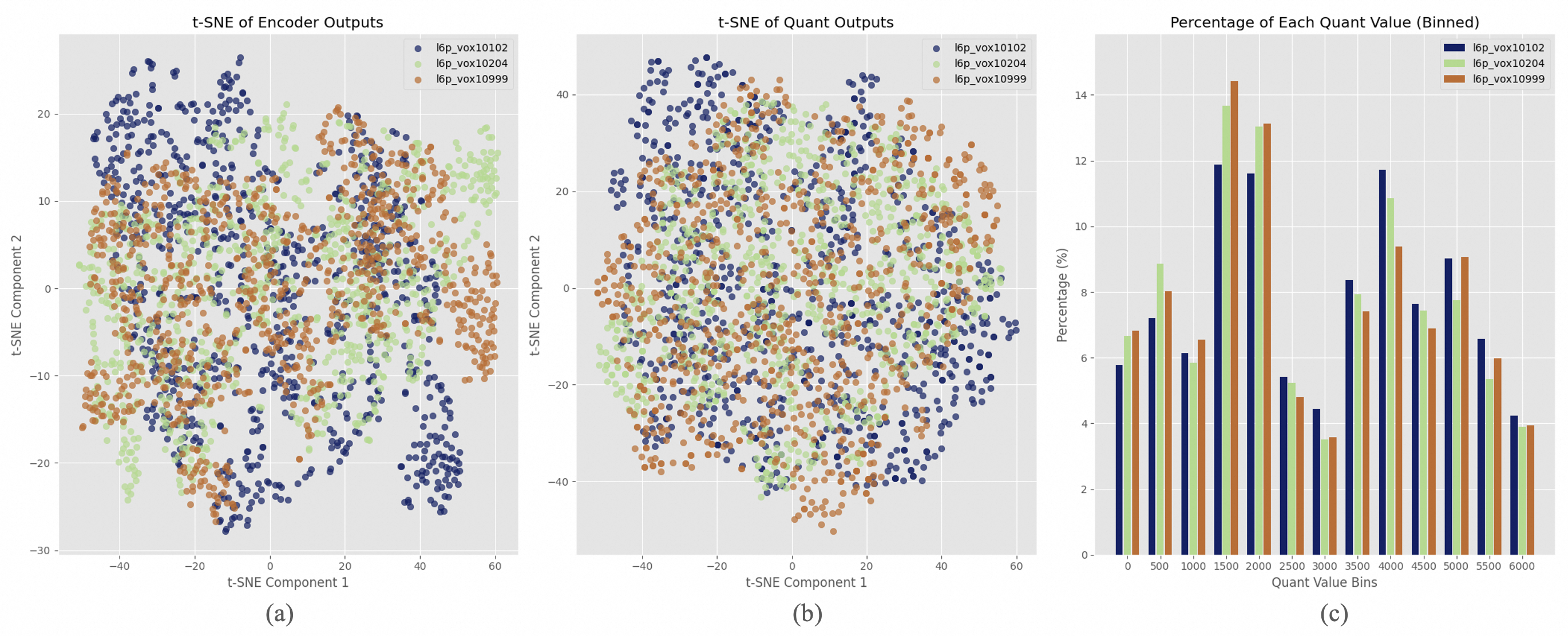
Figure 2: T-SNE visualization of speech representations before (a) and after (b) FSQ quantization.
Chunk-Aware Causal Flow Matching
The text-speech tokens are converted to acoustic features (Mel spectra) using the conditional flow matching model, accommodating real-time constraints. This involves sampling via probability density paths defined by time-dependent vector fields (Figure 3).
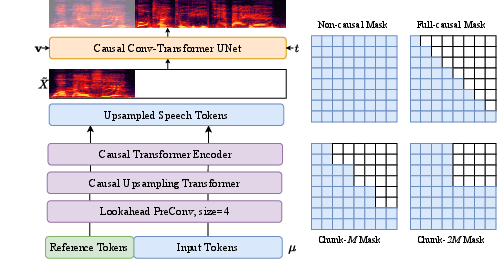
Figure 3: Unified chunk-aware flow matching model aiding in versatile synthesis scenarios.
Experimental Evaluation
Objective Results
Evaluations on various datasets, including Librispeech and SEED settings, revealed that CosyVoice 2 improves upon its predecessor with high content consistency (lower CER/WER) and speaker similarity (Table 1). Streaming synthesis mode, albeit slightly degraded in challenging scenarios, remains nearly lossless due to the unified framework.
Comparison with Baselines
Compared with state-of-the-art models, CosyVoice 2 consistently showed enhancements in speech quality (NMOS), content, and speaker fidelity. Particularly, in the SEED setting, CosyVoice 2's balance between content accuracy and speaker resemblance was unmatched.
Implications and Future Directions
CosyVoice 2 marks significant progress in real-time speech synthesis, crucial for enhancing user interactions in voice-assisted technologies and multilingual communications. Future works could focus on broadening language support and refining dialect synthesis, potentially through more extensive data incorporation and refined linguistic models.
Given its streaming capabilities, the model unlocks new interactive potentials—for instance, in conversational agents requiring immediate, contextually accurate vocal responses.
Conclusion
CosyVoice 2 exemplifies a comprehensive advancement in streaming speech synthesis, leveraging LLMs to deliver rapid, high-fidelity outputs across diverse linguistic scenarios. Key innovations—finite scalar quantization, simplified architecture, and chunk-aware flow matching—collectively enhance synthesis quality and responsiveness, positioning CosyVoice 2 as a pioneering solution in real-time voice synthesis applications.
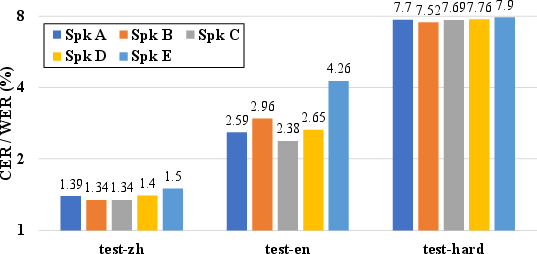
Figure 4: Performance metrics (CER/WER) across various SEED test environments.
CosyVoice 2 ushers in a new era of efficient, scalable, and contextually adept speech synthesis models, promising continued developments and applications in smart technology interfaces and beyond.