- The paper demonstrates that transformer models face intrinsic struggles executing search tasks on large graph structures despite extensive high-coverage data.
- Training on balanced graph distributions improves performance on complex structures but does not overcome scalability limitations when larger graphs are involved.
- Mechanistic interpretability reveals that while transformers learn a path-merging strategy, their convergence rates decline as graph size increases.
Abstract
The research explores the limitations of transformer-based models in learning robust search strategies, particularly in the context of the graph connectivity problem. Despite the generation of extensive high-coverage data for training smaller transformers, the intrinsic challenges related to graph size are not alleviated by increasing model parameters. The inability to perform search tasks effectively on larger graphs remains a bottleneck, unaffected by training transformers with even more comprehensive data sets or employing chain-of-thought methodologies.
Introduction
The ability to execute search operations is pivotal across reasoning, planning, and navigation tasks. Nonetheless, transformer-based LLMs face significant challenges in proof search. Through a focused study on a directed acyclic graph (DAG) search task, this paper delineates the bounds of transformer capabilities. Training models on balanced data distributions unveiled conditions under which transformers can learn search mechanisms, yet also highlighted limitations on scalability.
Methodology
Data Generation and Model Training
The study used DAGs to produce structured datasets, simplifying the representation of search tasks. Examples included varying complexities to test model robustness against graph size increases. Three main graph distributions were employed: naïve, balanced, and star configurations. Transformers were trained using the GPT-2 architecture with a focus on mechanistic interpretability, leveraging 1-hot embeddings and employing Sophia optimization.

Figure 1: Accuracy of model with input size 128 trained on 883M examples from the naïve distribution vs star vs balanced with lookaheads L≤20.
Sensitivity to Training Distribution
Models trained on balanced distributions outperformed those limited to naïve or star distributions, particularly in grasping complex graph structures with larger lookaheads. The balanced distribution provided a more diverse dataset, aiding the understanding and execution of search tasks.
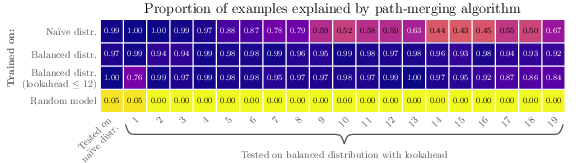

Figure 2: Proportion of examples where the path-merging algorithm was identified, evaluated on the trained models.
Mechanistic Interpretability and Algorithm Extraction
The research introduced a novel approach to mechanistically interpret model behavior by reconstructing computation graphs. This involved detailed examination of attention operations across numerous inputs, facilitating a deeper understanding of the learned algorithms. The path-merging algorithm, crucial for search tasks, was identified as the primary strategy learned by the model.
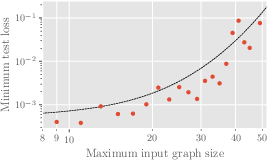
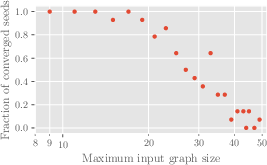
Figure 3: Minimum test loss after training on 236M examples vs maximum input graph size.
Scaling Challenges
Experiments revealed increased difficulty in model learning with larger graph sizes, even when model dimensions were scaled. The convergence probability diminished with size increases, and test loss escalated, indicating inherent limitations in scalability with current transformer architectures.
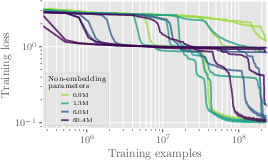
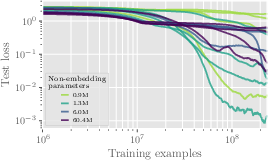
Figure 4: Training and test loss vs the number of training samples for models with varying non-embedding parameters.
Despite strategies such as depth-first search and selection-inference to permit intermediate steps akin to chain-of-thought prompting, transformers struggled with larger graph sizes. These methods, though potentially easing some tasks, were insufficient to overcome the limitations imposed by model architecture and graph size complexity.
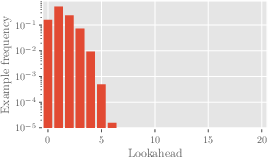
Figure 5: Histogram of lookaheads of 10M graphs from the naïve distribution, highlighting the distribution skew.
Conclusion
Transformers, with their current architectural constraints, face significant challenges in mastering search tasks with extensive graph sizes. This calls for alternative approaches, potentially involving innovative architectural modifications or novel training strategies, to advance search capabilities within these models. Future research should explore diversified methods, including alternative architectures or focused training techniques, to equip transformers with more robust search and reasoning skills.
The study underscores the pressing need for such advancements to harness the full potential of transformer models in complex, search-oriented tasks within AI systems.