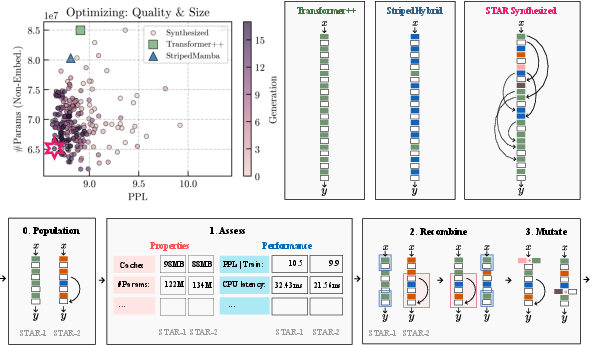
- The paper introduces STAR, a framework that automatically synthesizes optimized model architectures using a hierarchical search space and evolutionary algorithms.
- It details a multi-level genome representation that encodes featurization, operator, and backbone configurations for tailored deep learning models.
- Experimental results show significant improvements in quality, parameter reduction up to 13%, and cache utilization, outperforming baseline models.
STAR: Synthesis of Tailored Architectures
Introduction
The paper introduces STAR, a new method for optimizing model architectures specifically tailored to improve both quality and efficiency in deep learning applications. By leveraging a distinct hierarchical search space and evolutionary algorithms, the STAR framework facilitates the automated synthesis of architecture genomes, incorporating multiple optimization metrics.
Hierarchical Search Spaces
STAR uses a novel design space grounded in the theory of Linear Input-Varying Systems (LIVs), which generalize computational units such as attention variants, linear recurrences, and convolutions. The design space is characterized at three hierarchical levels: featurization, operator structure, and backbone composition.
STAR Genomes Representation
Genomes within STAR encapsulate numeric representations of model architectures, facilitating manipulation and optimization. The genome layers include:
Optimization with Evolutionary Algorithms
The STAR framework employs evolutionary algorithms to optimize architecture genomes. Processes such as assessment, pairing, recombination, and mutation are applied iteratively:
Experimental Results
Experiments in autoregressive language modeling demonstrate STAR's efficacy in synthesizing architectures that balance quality, size, and cache efficiency. Metrics reveal substantial improvements over Transformer and hybrid models:
- Quality optimization outperforms baselines in downstream benchmark averages.
- Quality and size optimizations reduce parameter counts by up to 13% while achieving superior performance.
- Quality and cache optimizations achieve up to 90% cache size reduction compared to prevailing models.
Conclusions and Future Work
STAR constitutes a significant advance in automated architecture optimization, presenting a powerful tool for AI system design across domains. Future extensions may focus on enabling variable depth and width optimizations, refining multi-stage approaches, and integrating with existing scaling protocols.
The implications of STAR's hierarchical design and synthesis approach suggest enhanced versatility and efficiency in constructing complex AI models tailored to diverse application requirements.
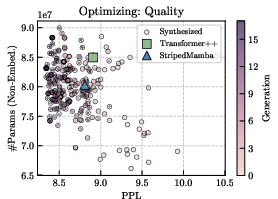
Figure 4: Genome scores during {\tt STAR} evolution for quality optimization, demonstrating progressive improvement across generations.