- The paper introduces a crucial safety case template that uses a CAE framework to decompose high-level cyber risks into actionable sub-claims.
- It employs proxy tasks as measurable indicators to evaluate an AI system’s incapability in enabling offensive cyber actions.
- The methodology fosters transparent safety arguments that enhance regulatory and public confidence in frontier AI deployments.
Safety Case Template for Frontier AI: A Cyber Inability Argument
The paper "Safety case template for frontier AI: A cyber inability argument" (2411.08088) introduces a structured methodology for assessing the safety of frontier AI systems concerning cyber risks. The proposal centers around a safety case template designed to demonstrate that an AI system does not possess capabilities that pose unacceptable cyber risks. Using a Claims Arguments Evidence (CAE) framework, the paper outlines how developers can break down high-level risks into specific sub-claims supported by evidence, fostering explicit and coherent safety arguments.
Introduction to Safety Case Methodology
Safety cases offer a systematic, evidence-based approach to assure stakeholders about the safety of critical systems. For frontier AI, whose risks include contributing to cyber threats or autonomous misbehavior, safety cases can be instrumental in evaluating risk before deployment (Figure 1).
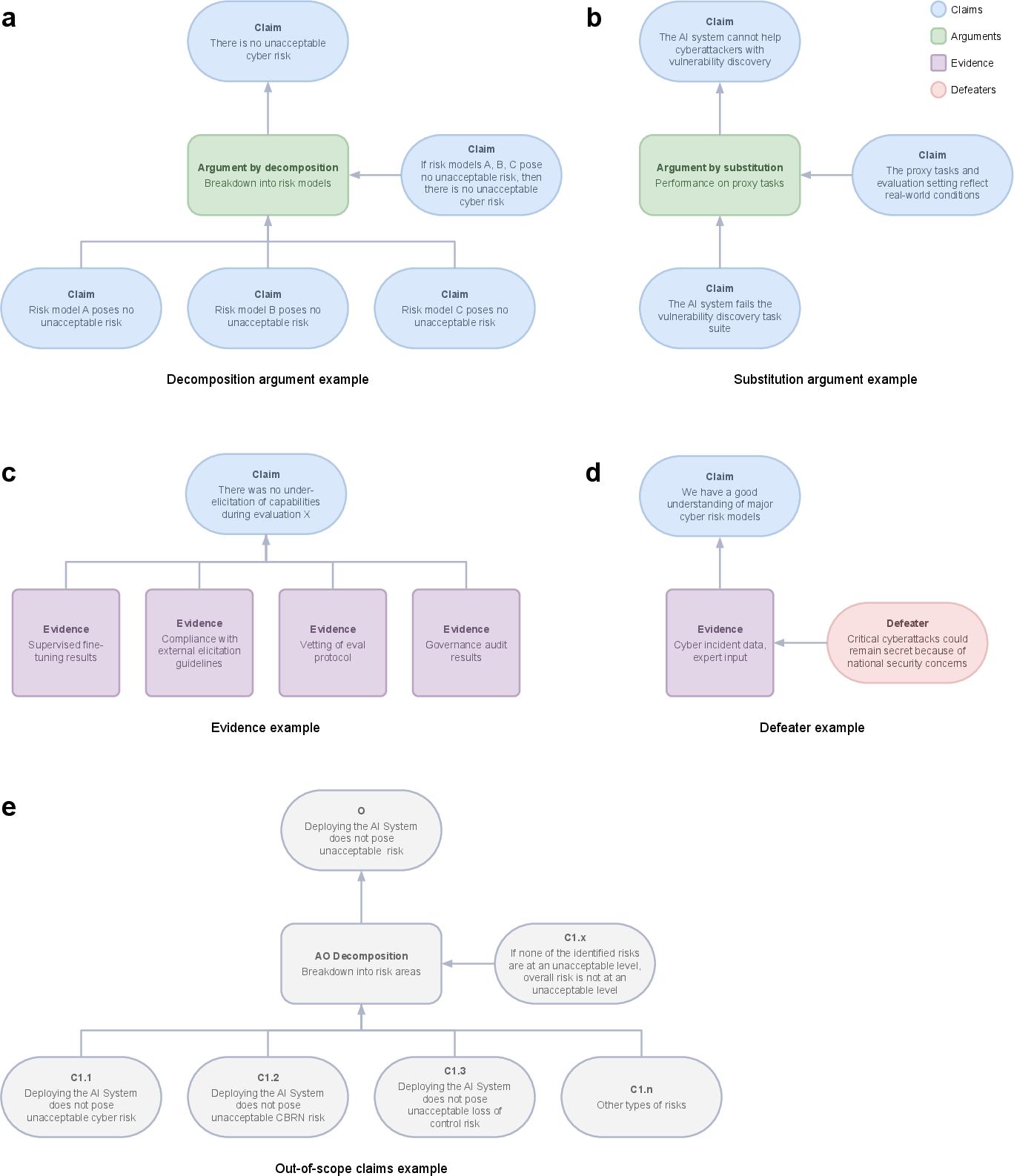
Figure 1: Examples of different safety case components.
The paper proposes a template focused on cyber incapability as part of an assurance strategy, complementing the broader, ongoing discussions on AI safety cases [buhl2024]. Given the speculative nature of novel AI-enabled cyberattacks [nevo2024], the template aims to ensure rigorous evaluation processes even amid uncertainties.
Structure of the Proposed Template
The template breaks down claims of AI safety into progressively specific sub-claims, underpinned by appropriate evidence. It focuses explicitly on evaluating whether an AI system can uplift a threat actor's capabilities beyond acceptable thresholds, using the concept of proxy tasks tailored for specific risk models (Figure 2).
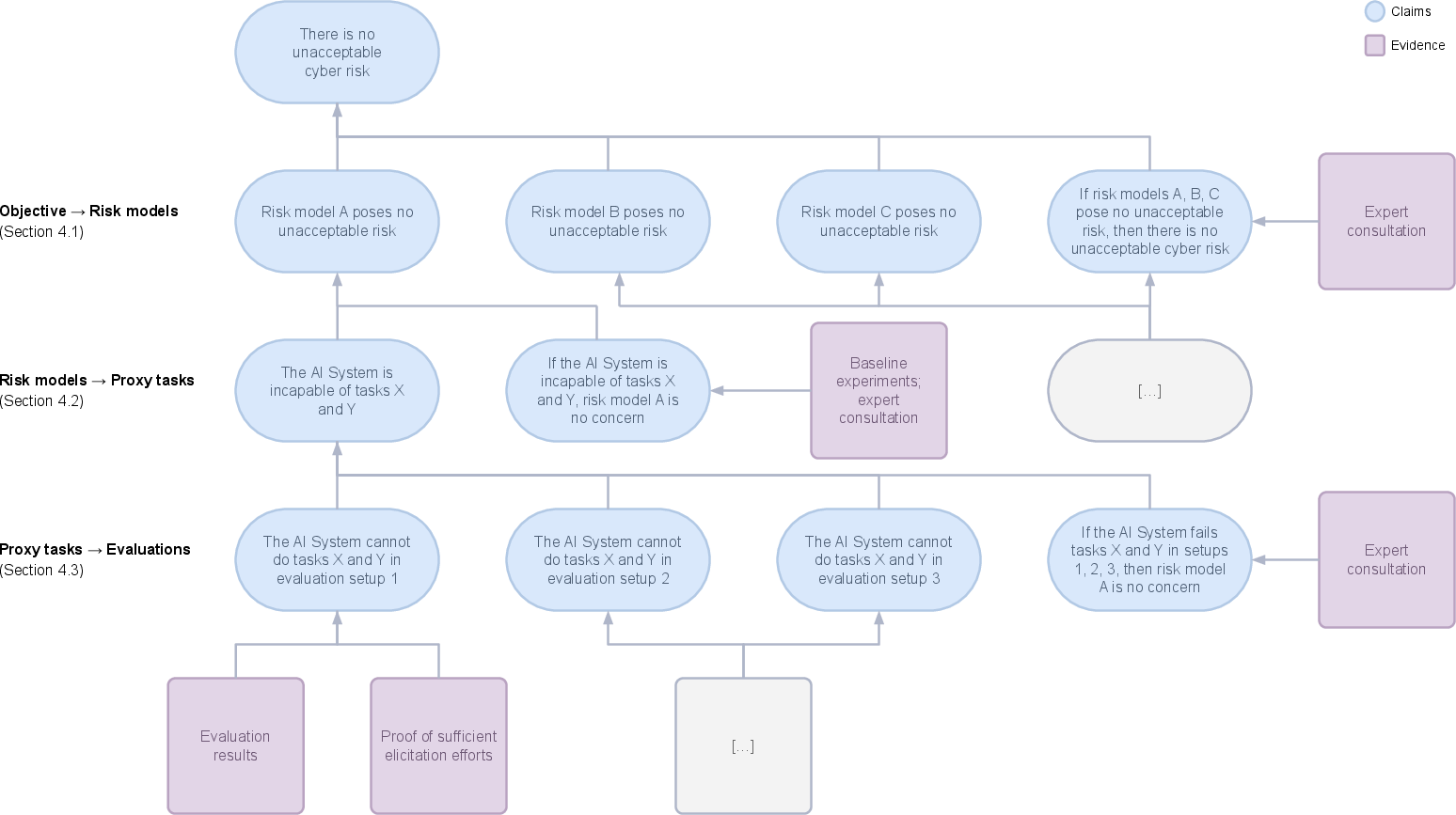
Figure 2: Simplified safety case template for offensive cyber capabilities.
Identifying Risk Models
The approach begins by categorizing risk models based on combinations of threat actors, harm vectors, and targets. For instance, a risk model might describe an AI system enabling non-experts to exploit vulnerabilities within critical national infrastructure (CNI). Risk models guide the selection of proxy tasks that assess the system's incapabilities concerning these scenarios (Figure 3).
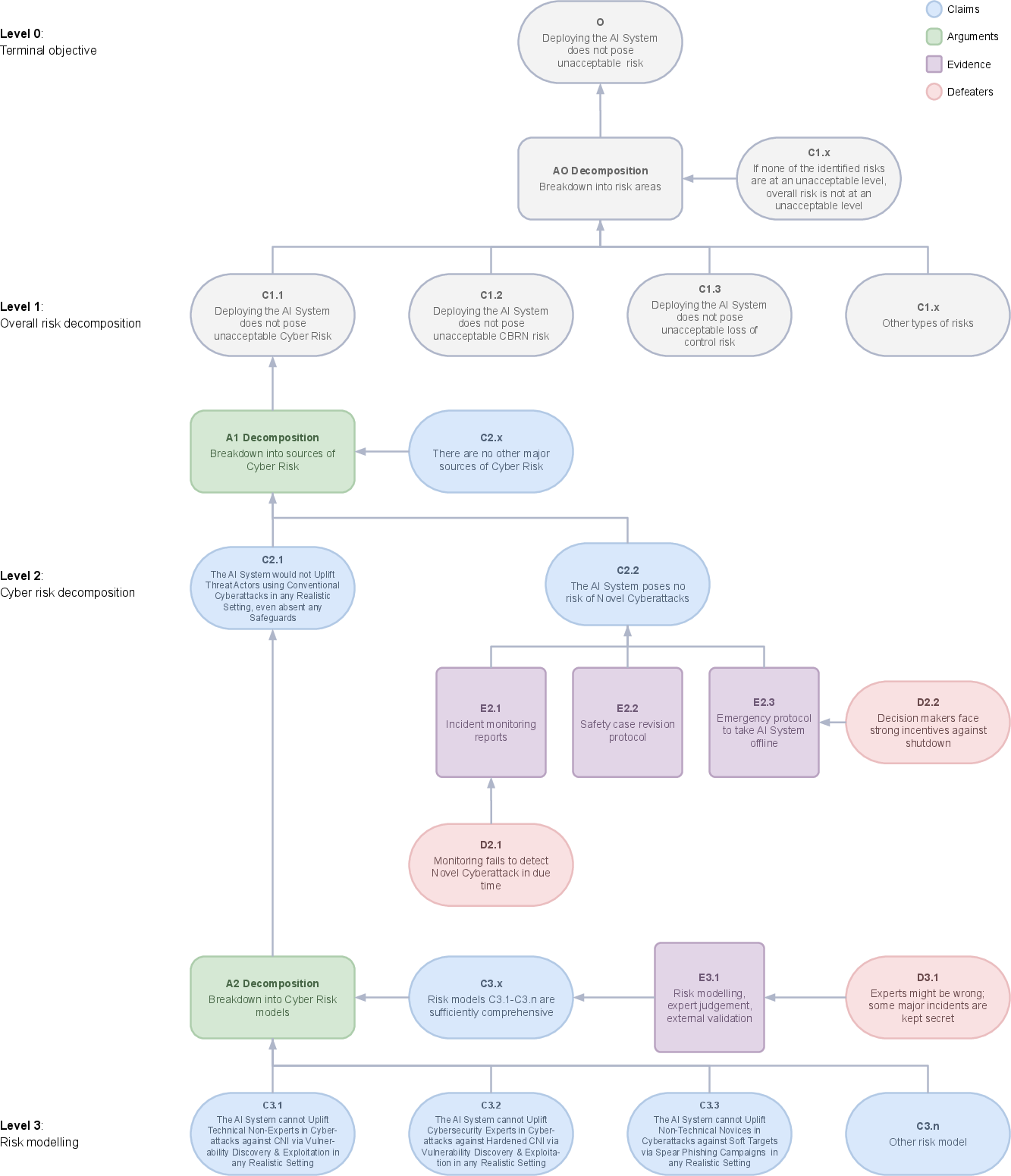
Figure 3: Part 1 of the safety case template.
Designing Proxy Tasks
Proxy tasks translate high-level capabilities into concrete, testable metrics. They need to accurately simulate real-world conditions and challenges, such as those represented by vulnerability discovery task suites. The adequacy of these tasks in predicting real-world outcomes is validated through expert inputs or baselined experiments (Figure 4).
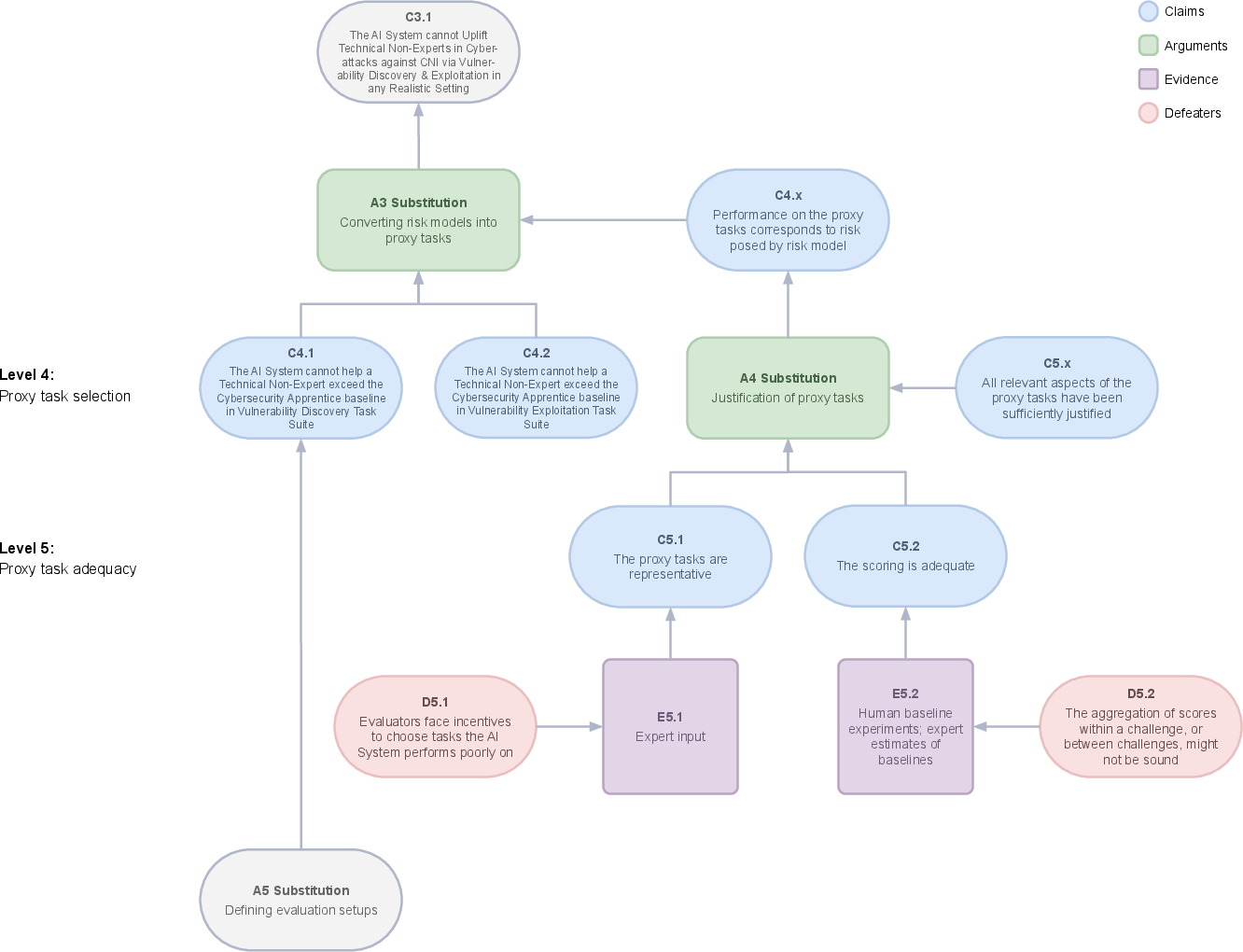
Figure 4: Part 2 of the safety case template.
Evaluation and Evidence Collection
Performance on proxy tasks is evaluated via diverse setups, including automated evaluations and human uplift experiments. It's critical to establish credible benchmarks and ensure the rigor of elicitation procedures for accurate capability measurement. Attention to human evaluation biases and evidence of adequate elicitation methods bolster confidence in the evaluation process (Figure 5).
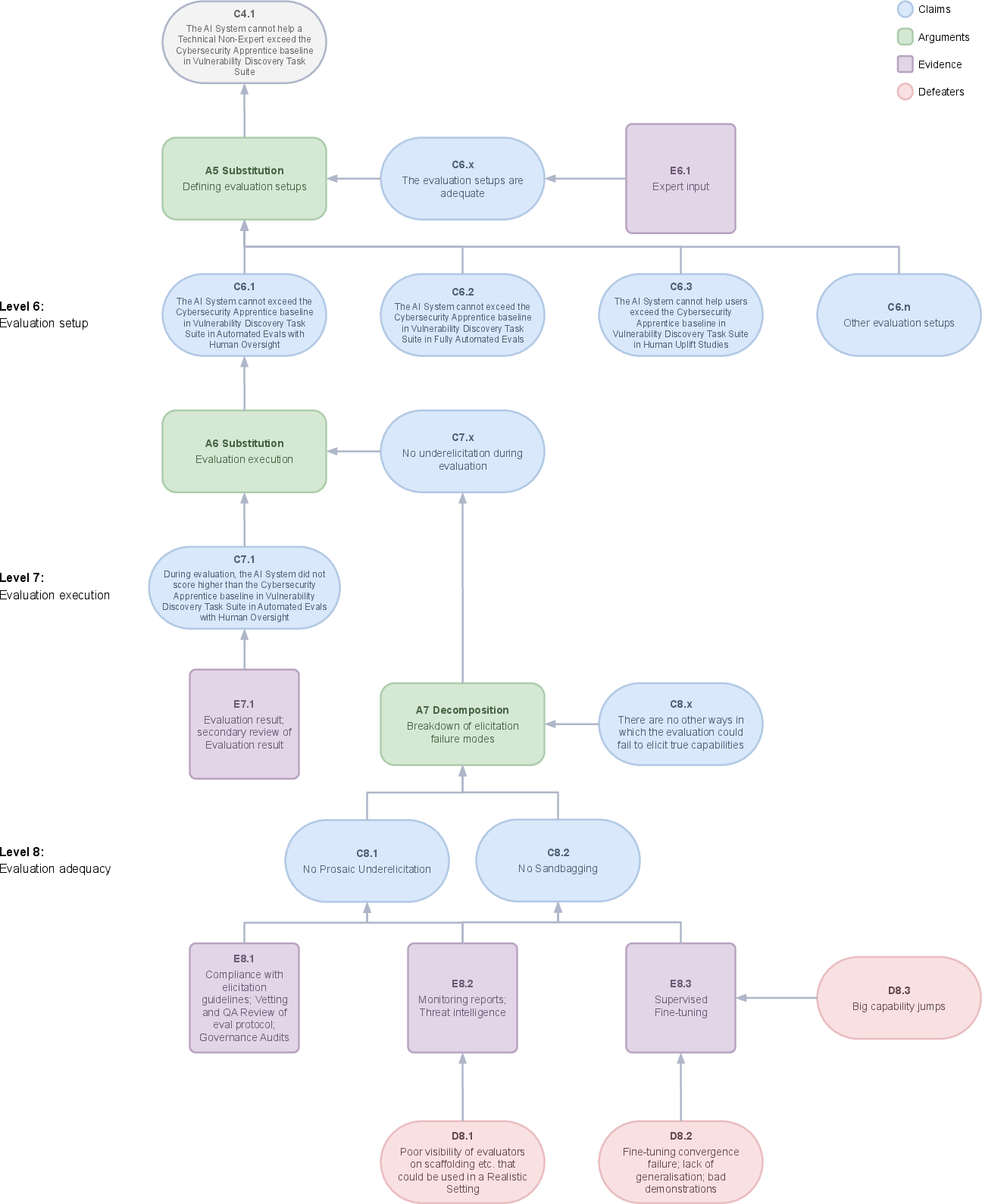
Figure 5: Part 3 of the safety case template.
Implications and Future Directions
This safety case template offers a foundational methodology that aids developers in clarifying their AI systems' capabilities and limitations concerning cyber risks. By making safety reasoning explicit, developers can better communicate with regulators and the public, addressing critical concerns around AI misuse.
The paper prompts further exploration into more granular evaluation techniques and systematic approaches to addressing safety case defeaters. Future work could enhance uplift dynamics understanding, factor in AI autonomy, and incorporate probabilistic claims for more nuanced risk assessments.
Conclusion
The proposed safety case template intends to guide discussions on structuring safety arguments in frontier AI, particularly concerning cyber inability. By explicitly integrating risk models, proxy tasks, and evaluation results, this methodology bridges theoretical risks with practical assessments, aiming to bolster AI assurance frameworks in advancing public and regulatory confidence.