- The paper introduces CaPo, a framework that uses meta-plan generation and adaptive execution to improve multi-agent cooperation efficiency.
- It leverages LLM-prompting and multi-turn discussions to strategically decompose tasks and continuously refine plans during execution.
- Experimental results on TDW-MAT and C-WAH tasks demonstrate significant improvements in task completion rates and collaboration efficiency.
CaPo: Cooperative Plan Optimization for Efficient Embodied Multi-Agent Cooperation
Introduction
The paper introduces Cooperative Plan Optimization (CaPo), a framework designed to enhance the cooperation efficiency of LLM-based embodied agents by solving the shortcomings of extemporaneous action execution in previous methods. It focuses on creating strategic and coherent cooperative plans among agents to reduce redundant steps and improve collaboration efficiency in complex tasks.
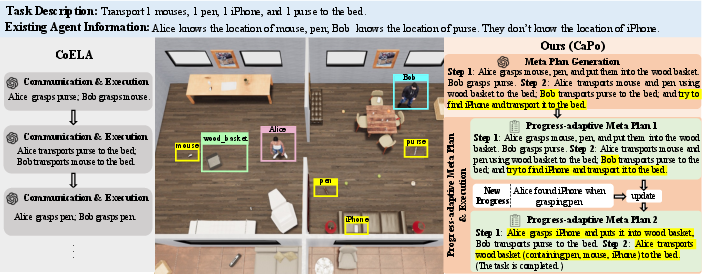
Figure 1: Procedure example of task accomplishment of CoELA and our CaPo framework.
Framework Overview
CaPo consists of two main phases: meta-plan Generation and Progress-Adaptive meta-plan and Execution. The meta-plan generation phase involves agents collaboratively formulating a meta-plan before taking any actions. This initial plan guides task decomposition into subtasks with detailed steps. It employs a meta-plan designer, responsible for creating the meta-plan, and meta-plan evaluators, who provide feedback. The progress-adaptive meta-plan and execution phase ensures the plan remains effective as agents make new progress, enabling adaptive planning to align with the latest task achievements.
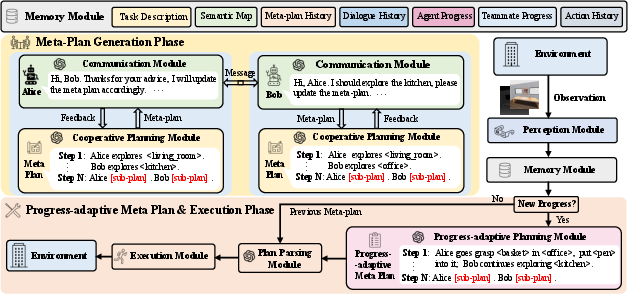
Figure 2: Overview of the CaPo framework for embodied multi-agent cooperation.
The meta-plan generation phase involves initializing a meta-plan using LLM-prompting techniques to structure task decomposition into subtasks. This approach ensures strategic long-term cooperation among agents. A multi-turn discussion among agents follows, using their partial observations to refine the meta-plan, leading to a consensus on cooperation strategy.

Figure 3: Examples of the evaluation and optimization process via multi-turn discussion among agents.
Progress-Adaptive Planning and Execution
This phase dynamically adapts the meta-plan based on latest task progress, which could include discovering new objects or completing subtasks. Agents leverage multi-turn discussions to refine the meta-plan, ensuring its alignment with current task status and maintaining effective cooperation throughout the task execution.
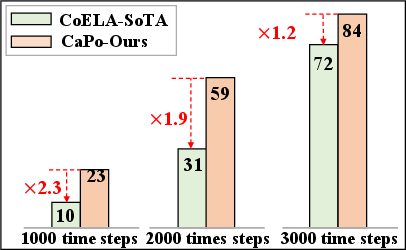

Figure 4: Comparison of Transport Rate (\%) between CoELA and CaPo using GPT-3.5 under different time steps.
Experimental Results
The paper presents experimental comparisons on the ThreeDWorld Multi-Agent Transport (TDW-MAT) and Communicative Watch-And-Help (C-WAH) tasks. CaPo demonstrates higher task completion rates and improved cooperative efficiency compared to predecessors. Results show notable improvements in completion rates with an optimized meta-plan approach using various LLM configurations like GPT-3.5, LLAMA-2, and GPT-4.

Figure 5: Examples of cooperative behaviors guided by meta-plan, improving task allocation and efficiency.
Conclusion
CaPo effectively addresses the challenges of embodied multi-agent cooperation by utilizing LLMs for strategic and adaptive planning. This leads to enhanced cooperation efficiency, particularly in complex task environments. While demonstrating significant improvements, the reliance on LLM capabilities may vary based on model strength. Future work could explore mitigating these dependencies.
In summary, CaPo paves the way for more efficient and strategic cooperation among embodied agents in complex task environments, leveraging LLM strengths to optimize collaborative strategies.

