- The paper introduces Cottention, which reformulates the attention mechanism using cosine similarity to achieve linear memory and time complexity.
- It implements a custom CUDA kernel and an RNN-inspired design to ensure efficient computation and constant memory usage during inference.
- Performance evaluations demonstrate that cosine attention preserves comparable accuracy to softmax in models like BERT and GPT-J while processing longer sequences efficiently.
Introduction
The paper "Cottention: Linear Transformers With Cosine Attention" presents a novel approach to attention mechanisms, addressing the limitations of softmax attention in terms of memory complexity. Softmax attention's quadratic memory and time complexity restrict the efficient processing of long sequences. This research introduces "Cottention," which replaces the softmax operation with cosine similarity, achieving linear complexity relative to sequence length. The reformulation allows Cottention to be expressed as a recurrent neural network (RNN), enabling constant memory usage during inference for both bidirectional and causal tasks. This paper explores the implementation and evaluates its performance in comparison to traditional attention mechanisms.
Cosine Attention Mechanism
Cosine attention leverages the properties of cosine similarity to sidestep the quadratic complexity typically associated with softmax attention. By normalizing the query and key vectors and utilizing an optimized linear algebraic formulation, Cottention achieves a linear memory footprint. The core of cosine attention is the computation of a similarity matrix through L2 normalization of the queries and keys, conducting the following operation:
CosAttention(Q,K,V)=N(Q)⋅N(K)T⋅V
where N(X)=∥X∥2X denotes L2 normalization. The use of a custom CUDA kernel ensures the efficient computation of this operation.
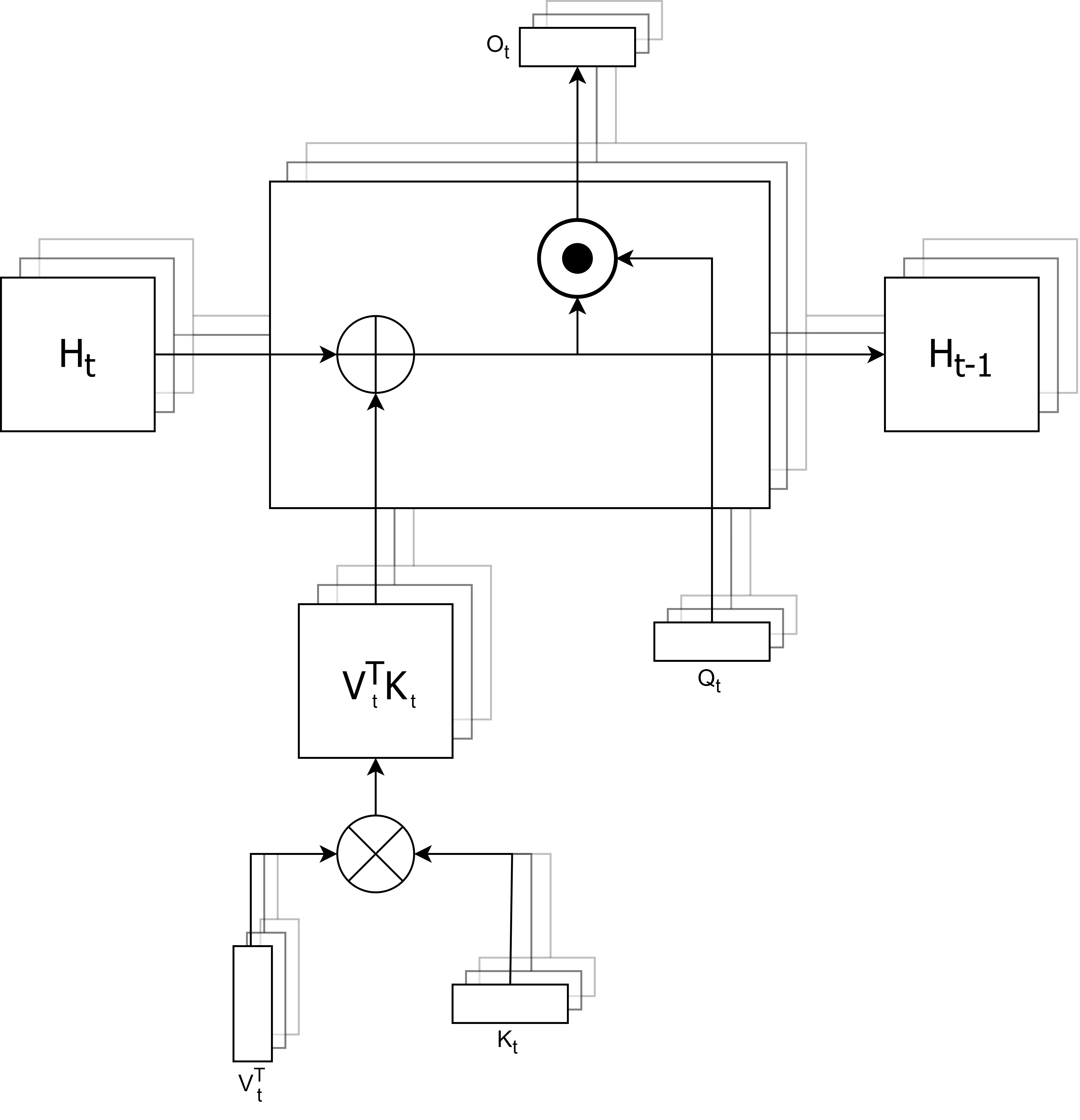
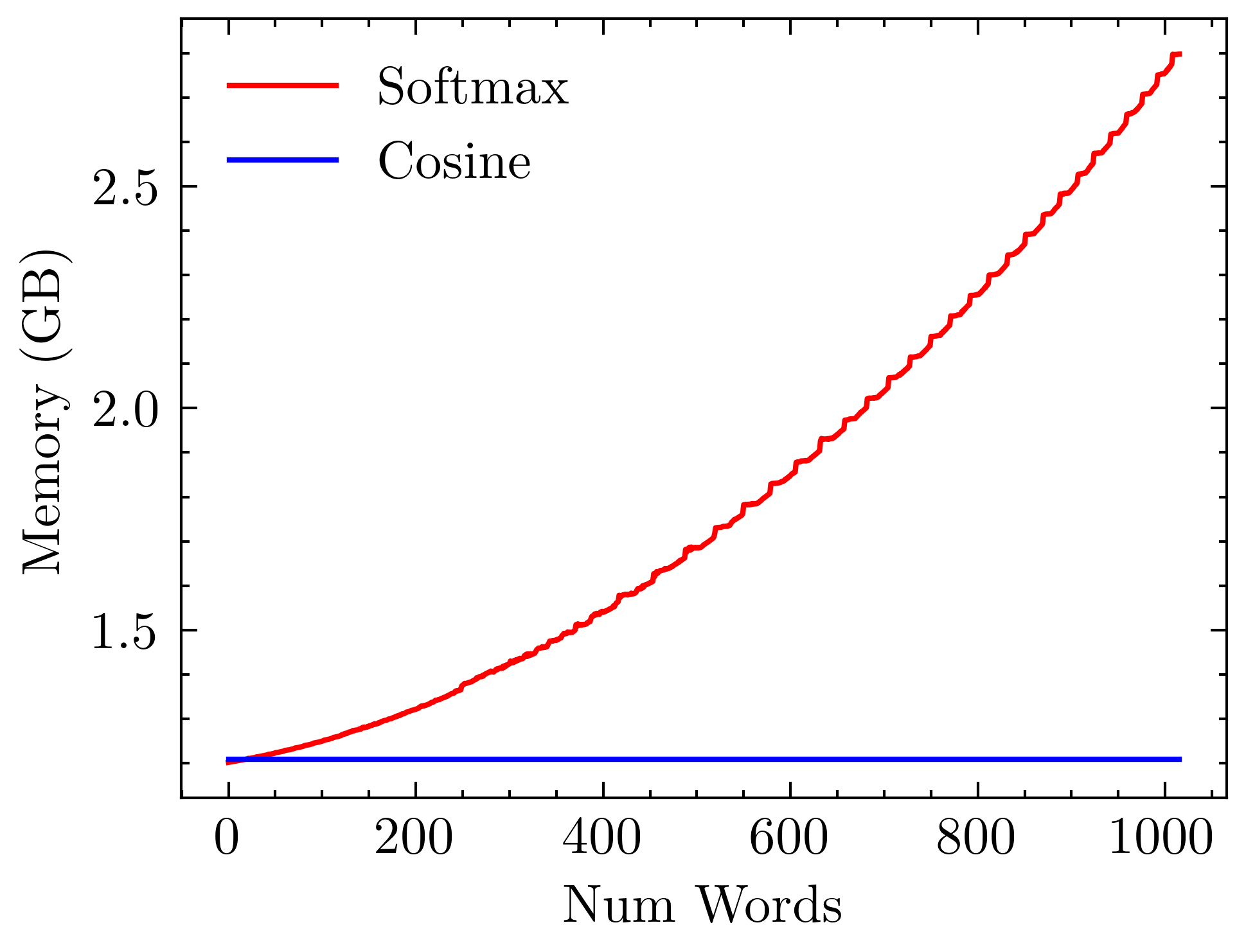
Figure 1: Recurrent neural network representation of cosine attention where the queries, keys, and values are of shape (N,H,(dH_key/H_key/H_value)
Cosine attention also addresses potential instability during training by introducing a learnable scalar parameter for normalization. This parameter is initialized and then optimized during training, allowing the model to adapt its attention scaling appropriately.
Cosine attention demonstrates compelling performance metrics when evaluated against traditional softmax mechanisms. Testing on both bidirectional (BERT) and causal (GPT-J) models reveals that Cottention achieves comparable accuracy while maintaining a significantly reduced memory footprint. This efficiency is particularly valuable when processing sequences longer than what is feasible with standard softmax attention.
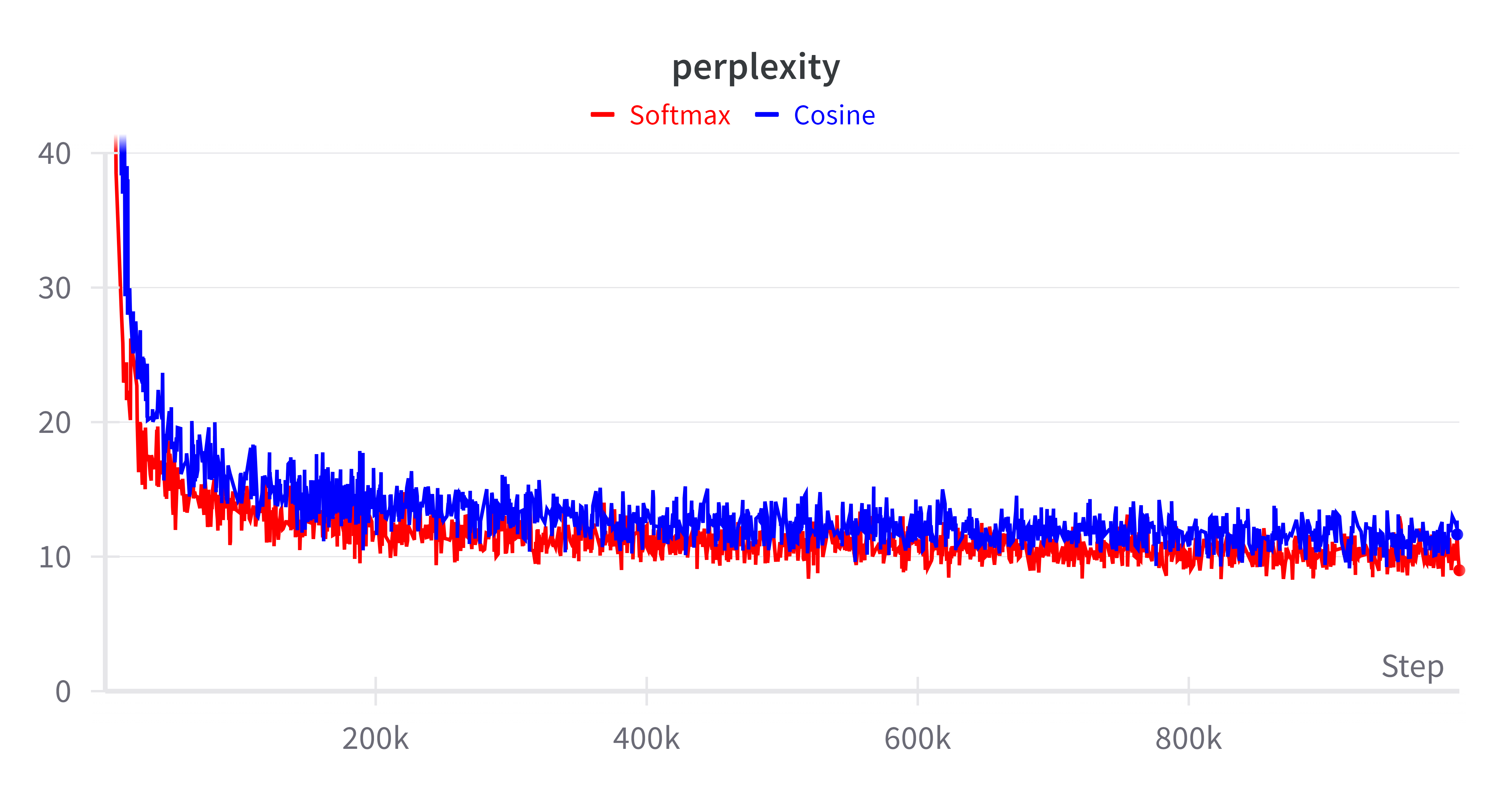
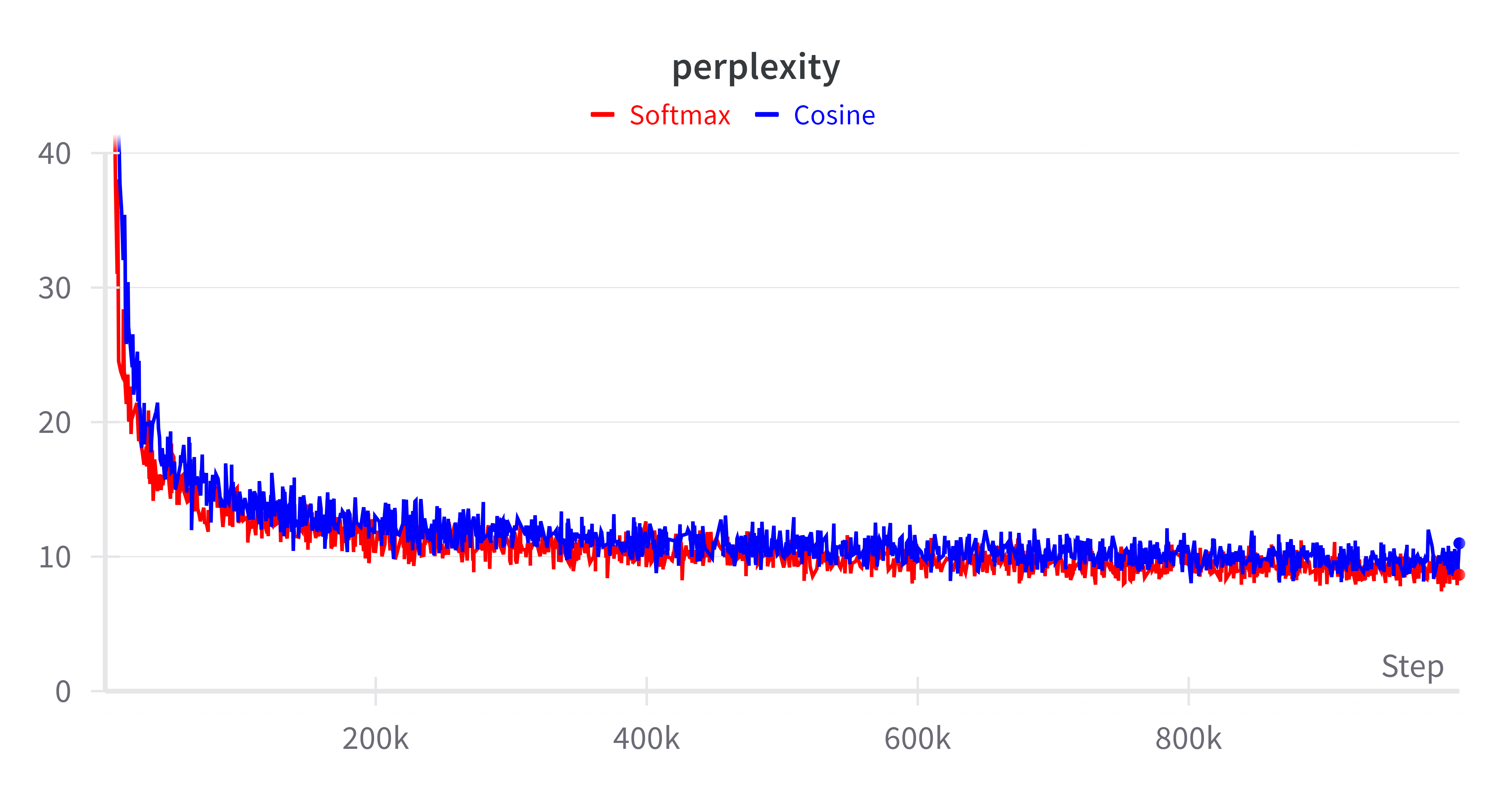
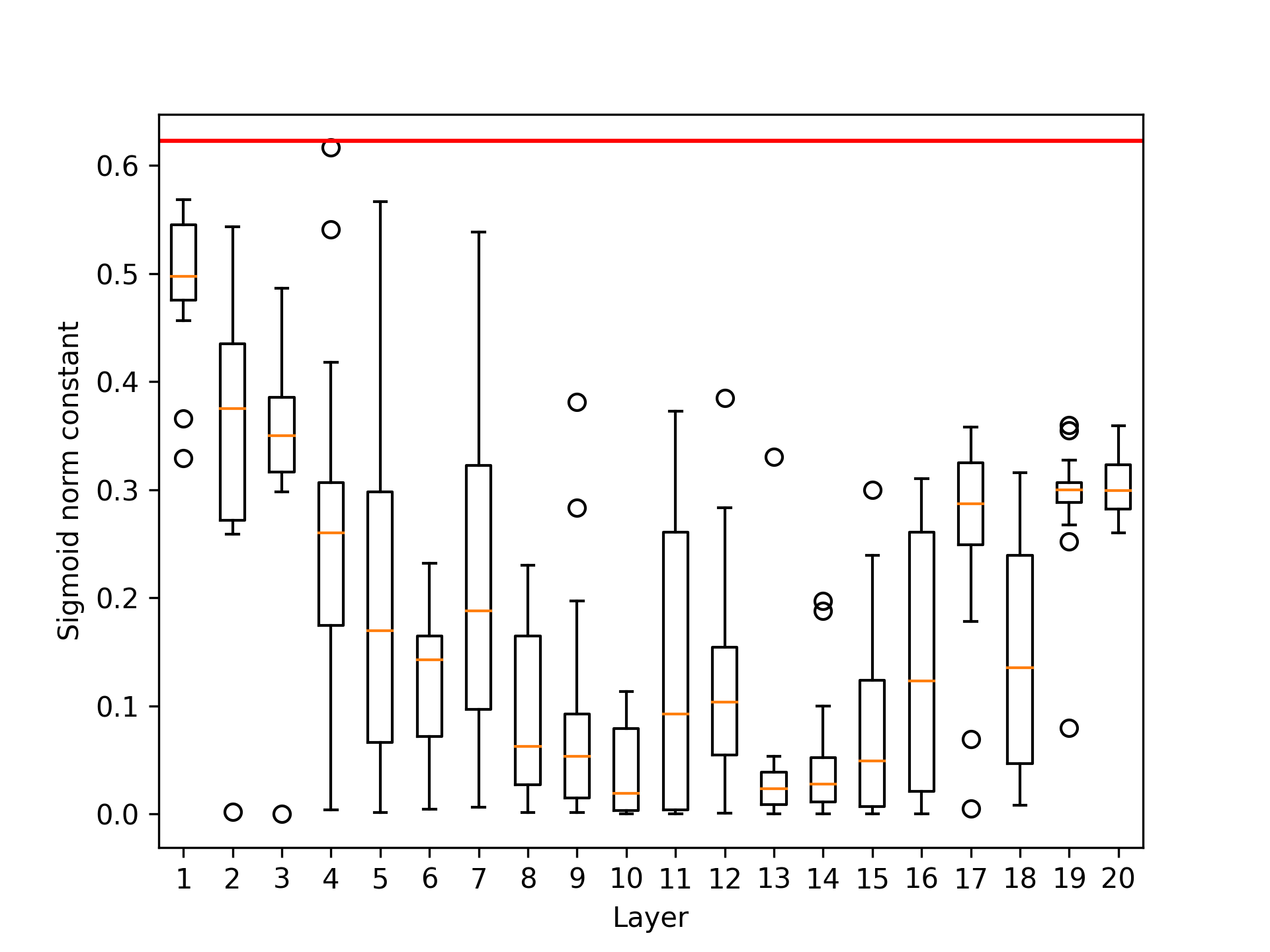
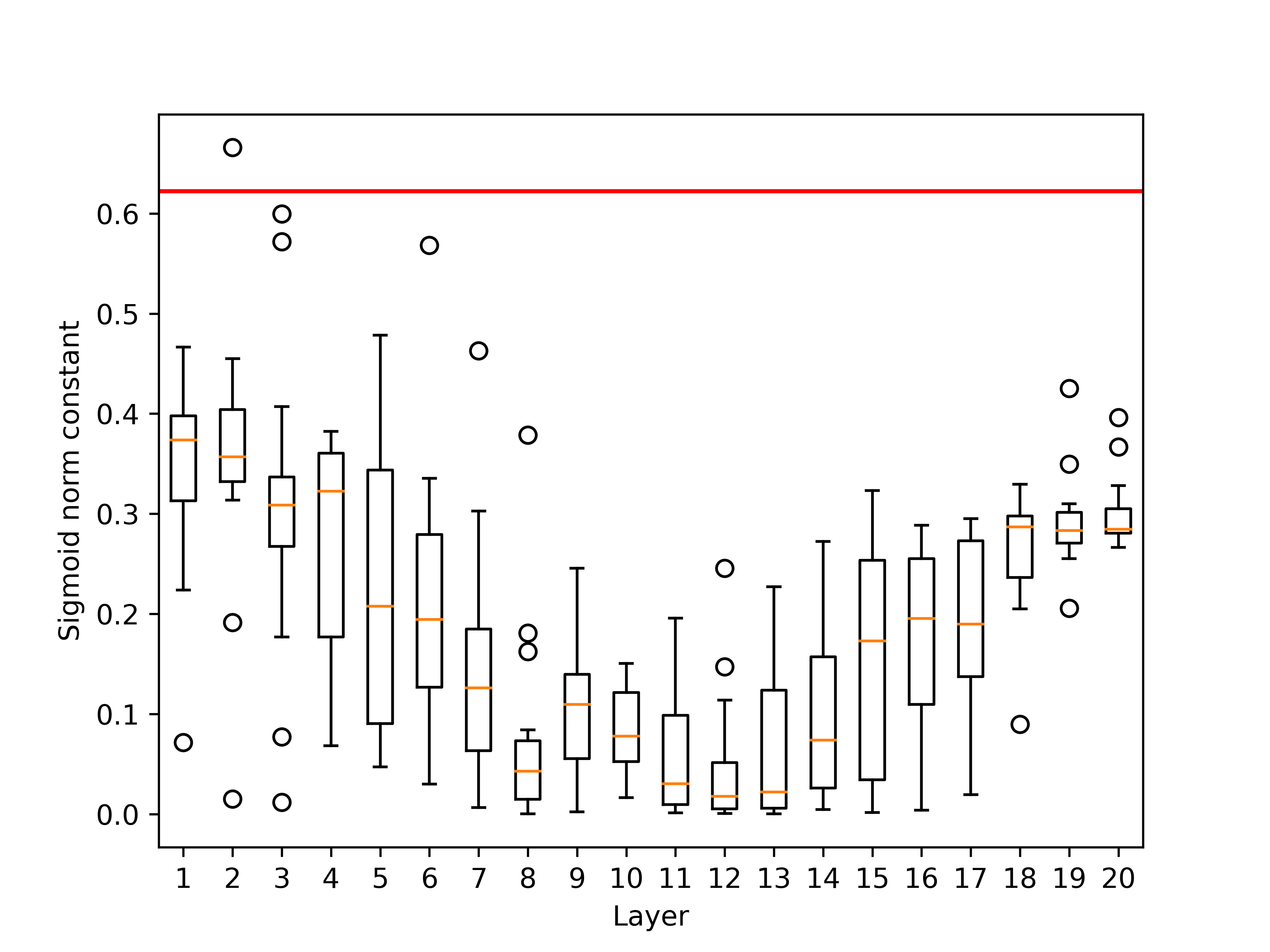
Figure 2: Perplexity comparison for models with 300M (left) and 1.2B (right) parameters.
In terms of computational resource usage, cosine attention exhibits linear complexity in memory as a function of sequence length. Figure 3 highlights these attributes, contrasting the exponential scaling of softmax attention and the linear growth observed with cosine similarity-based models.
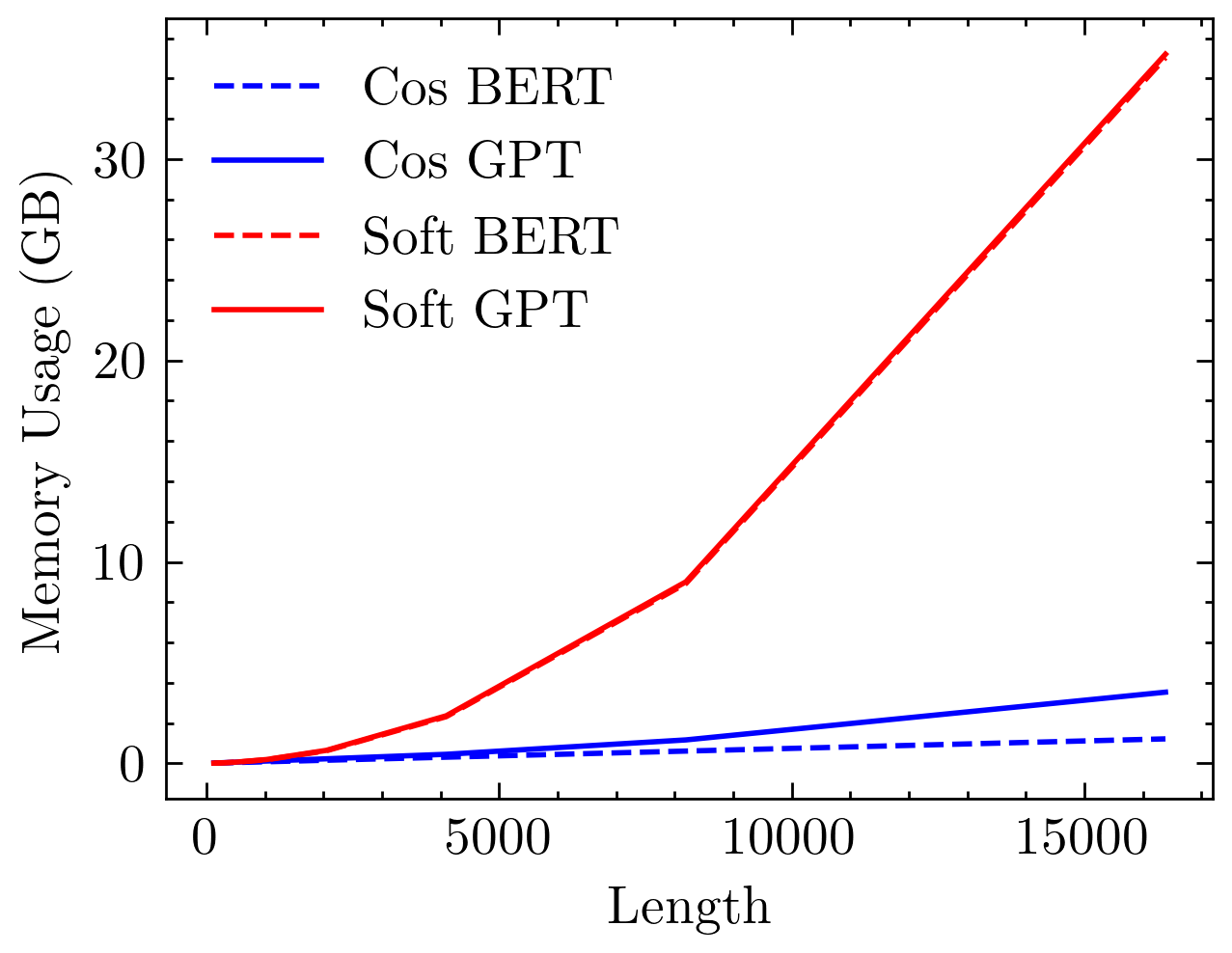
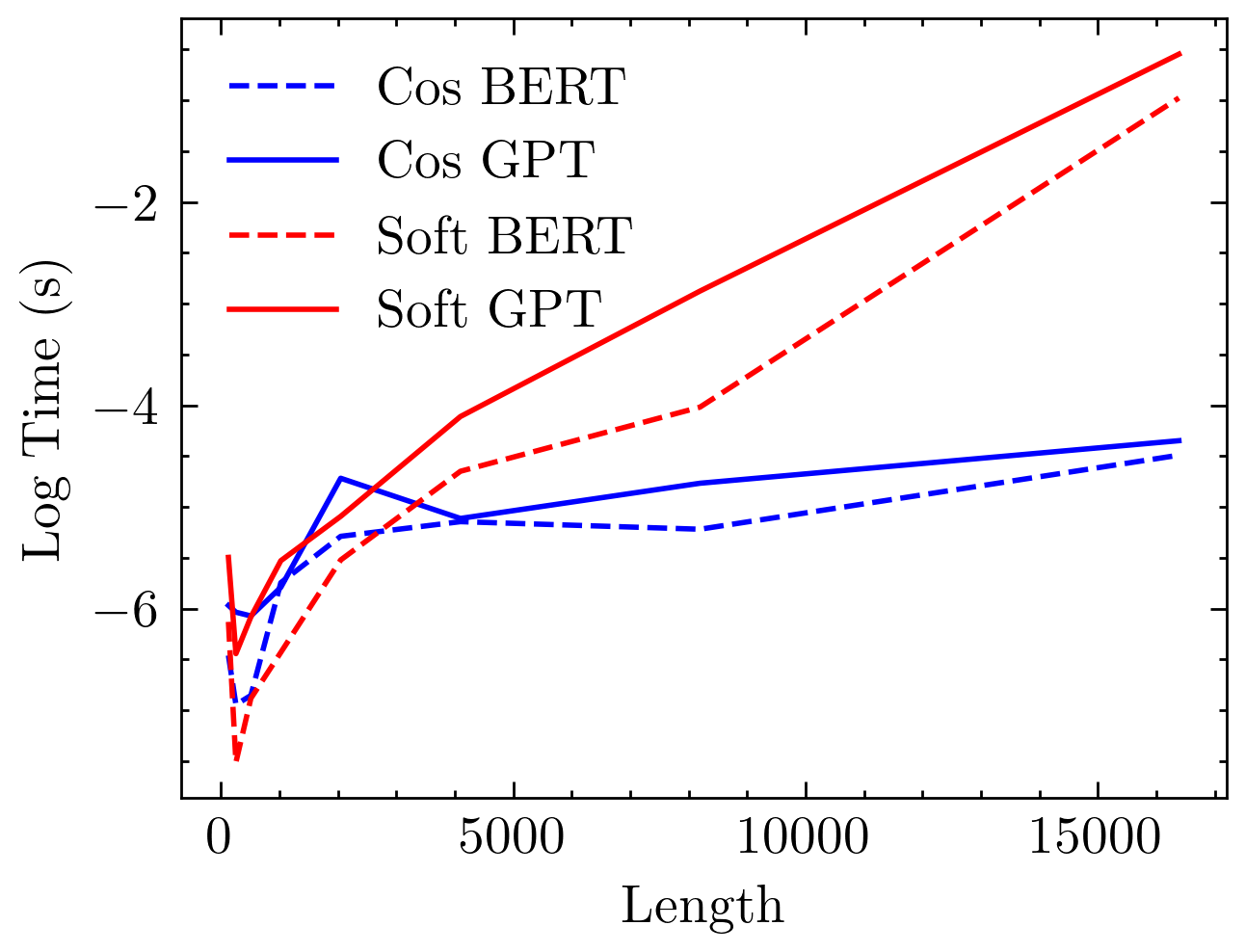
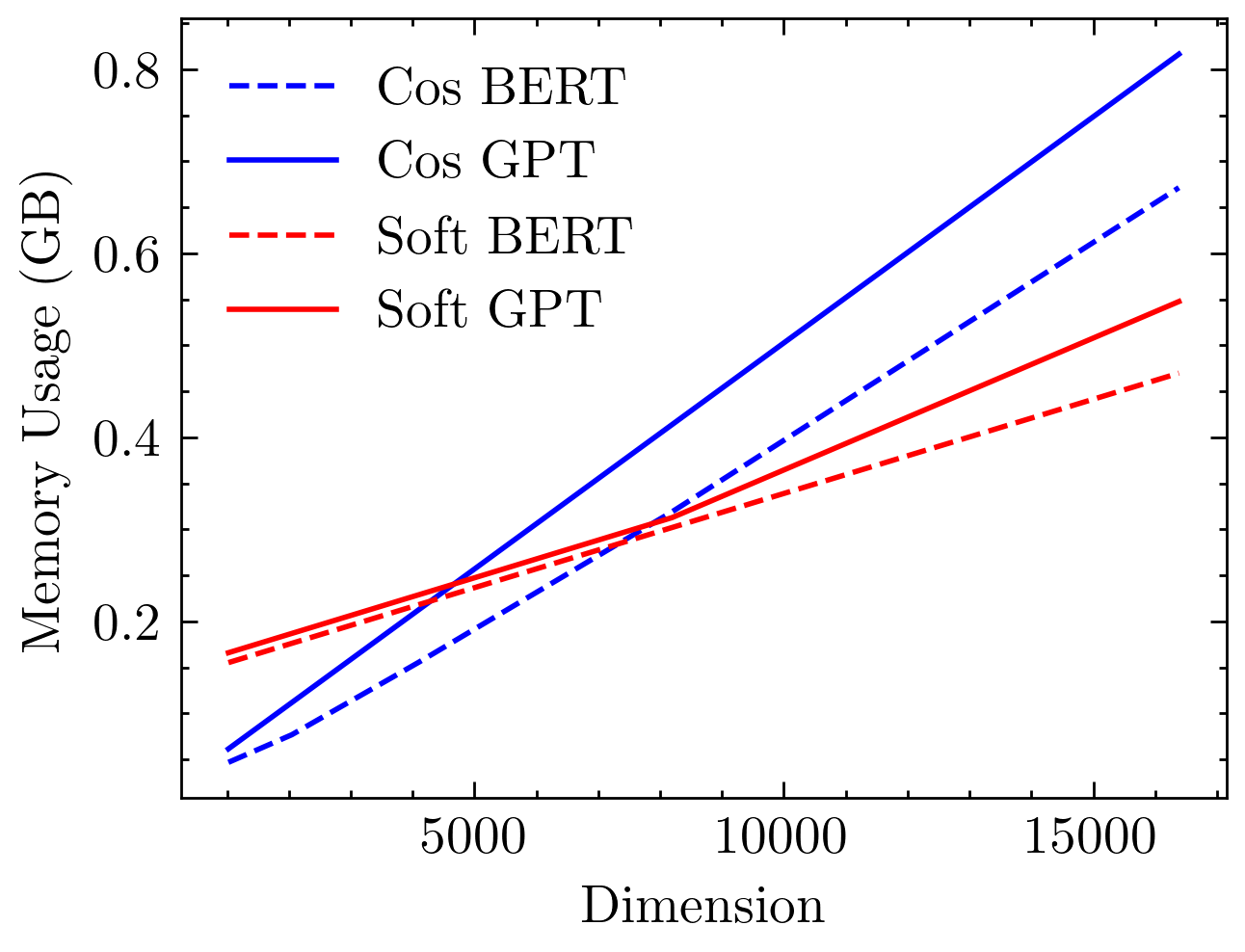
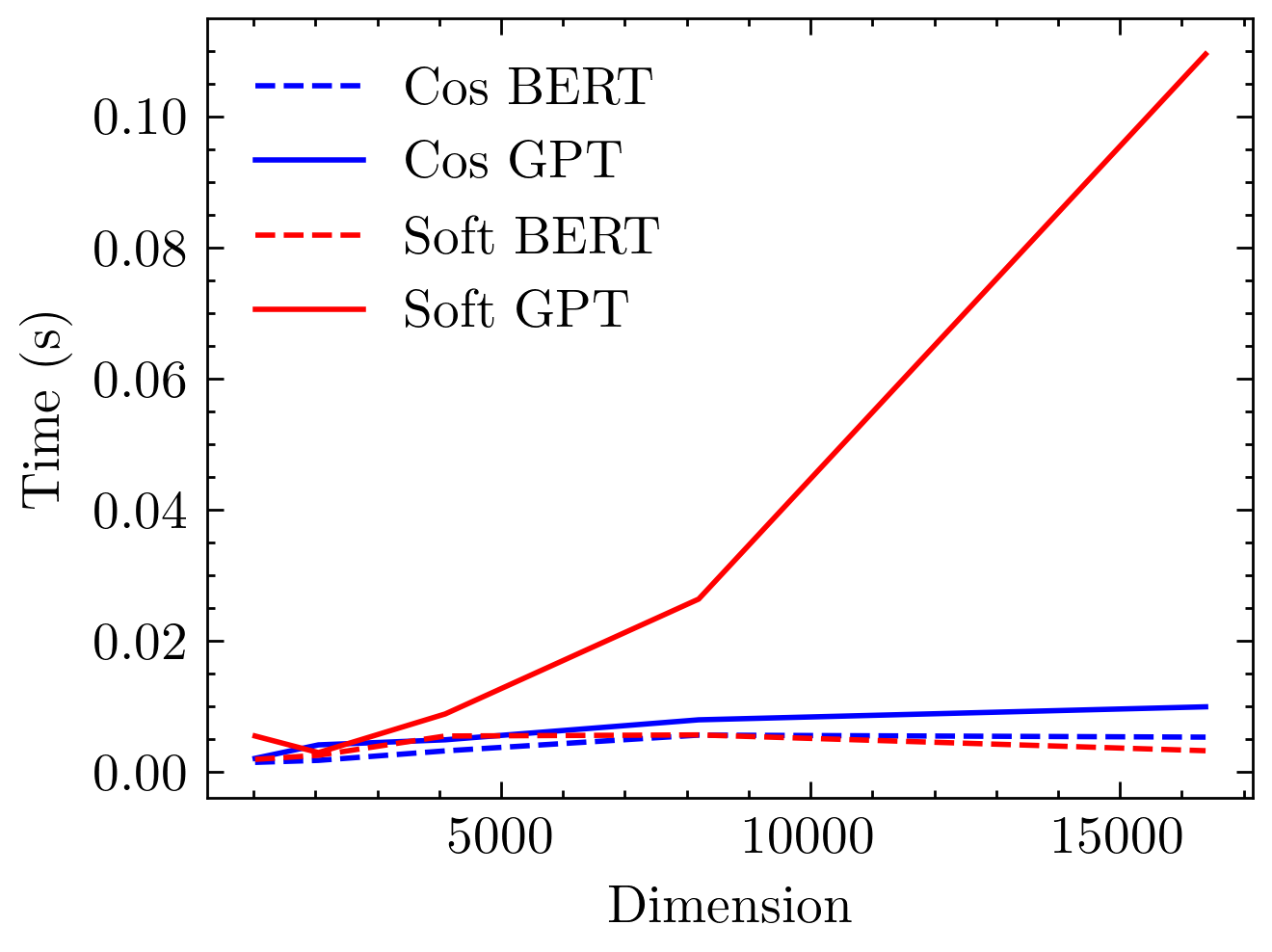
Figure 3: Time and memory usage comparison between softmax and cosine attention models. Softmax models exhibit quadratic complexity, while cosine models demonstrate linear complexity with respect to sequence length.
Algorithmic Insights
The architectural underpinnings of cosine attention allow it to be framed in terms of an RNN. This conceptual shift facilitates constant memory usage during inference—an attractive feature in scenarios where computational resources are constrained. The hidden state design mimics RNN dynamics and proves beneficial in modeling long-range dependencies without substantial resource allocation typically required for softmax-based attention.
Conclusion and Future Directions
The introduction of cosine attention provides a notable step forward in reducing the computational burden associated with traditional attention mechanisms. By maintaining comparable performance levels and facilitating longer sequence processing, Cottention positions itself as a powerful alternative for large-scale language processing tasks. Further work will involve optimizing custom CUDA implementations, exploring enhanced normalization strategies, and scaling this approach to larger model architectures. The potential of matrix factorization techniques could further unleash new efficiencies, leveraging the distinct properties of cosine-based formulations. Overall, this work lays promising groundwork for the future of efficient and scalable attention mechanisms in AI.

