- The paper introduces StoryMaker, which integrates facial identity with clothing, hairstyle, and body attributes for holistic consistency in narrative image generation.
- It utilizes a novel Positional-aware Perceiver Resampler with attention constraints and LoRAs, achieving superior CLIP-I scores compared to existing methods.
- Experimental evaluations demonstrate its effectiveness across diverse applications, enabling multi-character storytelling and personalized digital content.
StoryMaker: Towards Holistic Consistent Characters in Text-to-image Generation
Introduction
The paper "StoryMaker: Towards Holistic Consistent Characters in Text-to-image Generation" (2409.12576) addresses a significant challenge in the personalization domain of diffusion-based image generation models: achieving holistic consistency in scenes involving multiple characters. While previous methods have focused primarily on maintaining facial identities, they often overlook other critical aspects such as clothing, hairstyles, and body consistency, which are essential for creating a cohesive narrative across a series of images. The proposed solution, StoryMaker, incorporates face identities and cropped character images to preserve these attributes while enabling narrative creation through text prompts.
Methodology
StoryMaker integrates facial identity information with character attributes such as clothing, hairstyles, and bodies using a novel module known as the Positional-aware Perceiver Resampler (PPR). By conditioning generation on these integrated features, StoryMaker aims to maintain holistic consistency in image serialization. To prevent intermingling of multiple characters with the background, StoryMaker employs constraints on the cross-attention impact region via MSE loss in conjunction with segmentation masks.
This approach ensures that character attributes remain distinct and coherent across generated images. Additionally, the model is trained to decouple pose information using a conditioning framework informed by ControlNet, allowing pose diversity when generating sequences. LoRAs are employed to enhance fidelity and quality, thereby making StoryMaker adaptable to various applications, such as clothing swapping and image variation.
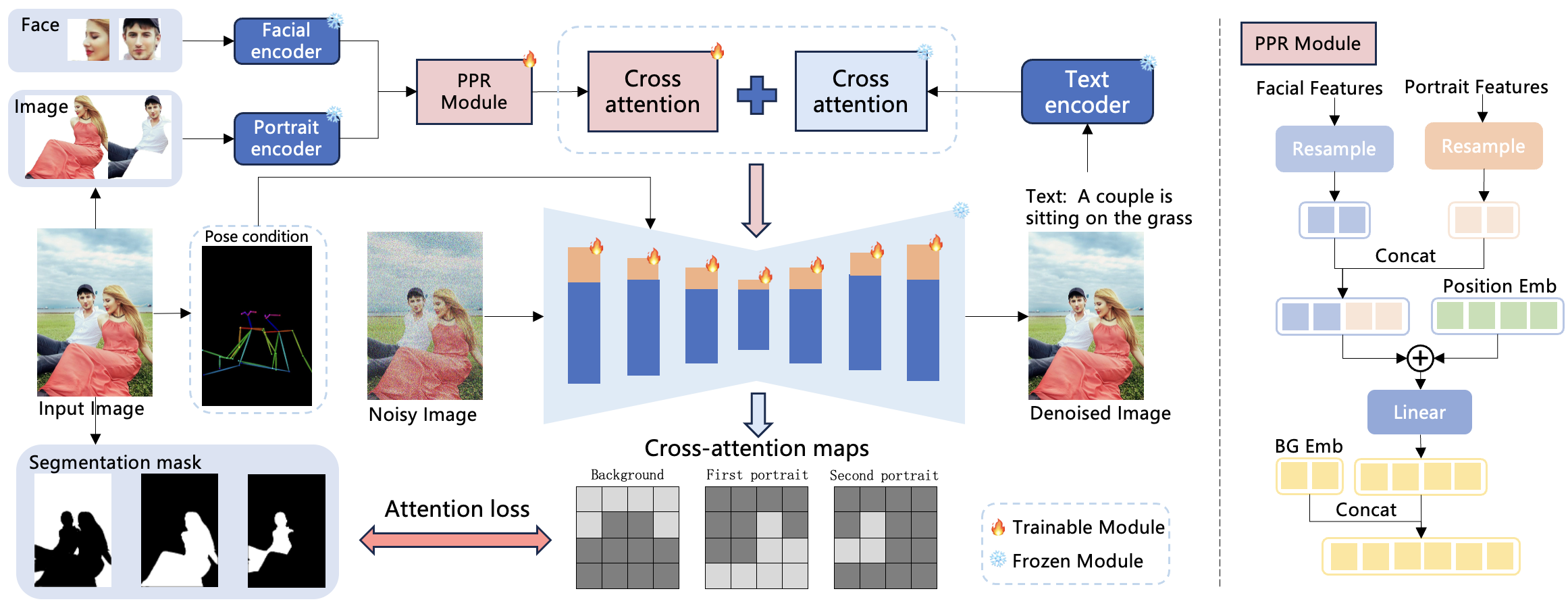
Figure 1: The model architecture of our proposed StoryMaker, highlighting the Positional-aware Perceiver Resampler and decoupled cross-attention with LoRAs.
Experimental Evaluation
Quantitative comparisons between StoryMaker and existing methods including MM-Diff, PhotoMaker-V2, InstantID, and IP-adapter-FaceID illustrate StoryMaker's superior performance in maintaining consistent character portrayal. It achieves the highest CLIP-I score, emphasizing the preservation of not just facial identities but also clothing, hairstyles, and body features. While InstantID excels in facial similarity due to its extensive training data, StoryMaker balances identity preservation across multiple characters and all associated features.
(Table 1)
Figure 2: Visual comparison on single character condition generation.
Visual analysis further corroborates these findings, demonstrating StoryMaker's capability in generating coherent narratives with multiple characters. The model's flexibility is showcased in applications ranging from single-character portrait generation to intricate multi-character stories.

Figure 3: Visualization of two-character image generation with variations in realism and stylization.
Diverse Applications
StoryMaker's robust performance allows for an array of applications beyond standard personalization tasks. These include transformations such as age changes while preserving clothing consistency, and compelling stylizations achieved by tuning parameters within the resampler modules. Additionally, StoryMaker's compatibility with generative plugins like LoRA and ControlNet amplifies its utility in creating diverse and high-quality narratives for digital storytelling.

Figure 4: Diverse applications of StoryMaker.
Conclusion
StoryMaker represents a significant advancement in text-to-image generation by achieving holistic consistency not only in facial identities but across clothing, hairstyles, and body features. By leveraging the Positional-aware Perceiver Resampler alongside strategic attention loss constraints, the model successfully creates cohesive image sequences conducive to narrative construction. Its ability to maintain consistency across varying poses and styles paves the way for numerous applications in storytelling and comic creation. These innovations position StoryMaker as a versatile tool with substantial potential in domains demanding high personalization and narrative coherence.
While this research marks a pivotal step forward, further enhancements in pose guidance without explicit inputs and scaling capabilities for multiple characters will foster even greater fidelity and applicability in complex scenarios.

