- The paper presents THEA-Code as a novel IDS correction method that integrates disturbance-based discretization, a differentiable channel, and entropy control.
- It demonstrates that optimizing encoding rates and hyperparameters can drastically improve error correction performance, achieving nucleobase error rates as low as 0.77%.
- Its autoencoder framework with auxiliary reconstruction tasks enables end-to-end training, paving the way for robust and scalable DNA data storage solutions.
Disturbance-based Discretization, Differentiable IDS Channel, and an IDS-Correcting Code for DNA Storage
Introduction
The evolving field of DNA data storage has witnessed various innovations aimed at improving data storage capacity and robustness. One persistent challenge is mitigating errors intrinsic to DNA synthesis, sequencing, and amplification processes, notably insertions, deletions, and substitutions (IDS). This research introduces an innovative approach—THEA-Code, a neural network-based solution that integrates an autoencoder architecture to devise IDS-correcting codes specifically tailored for DNA storage systems. This paper outlines the development of THEA-Code through three key innovations: disturbance-based discretization, a differentiable IDS channel, and an IDS-correcting code strategy.
Conceptual Framework of THEA-Code
THEA-Code employs a deep learning-based autoencoder to accomplish both encoding and decoding tasks. Encoding involves transforming a source DNA sequence into a longer codeword sequence, while decoding reverses this transformation into the source sequence. The development of THEA-Code necessitated addressing three significant challenges:
- Non-Differentiability: Insertion and deletion operations are inherently non-differentiable, complicating gradient propagation within the neural network.
- Quantization of Feature Representation: Autoencoders typically generate soft (continuous) feature representations, as opposed to the discrete representations needed for coding.
- Complex Training Dynamics: The autoencoder combines an encoder, a differentiable channel, and a decoder, each with distinct logical operations, amplifying training complexity.
(Figure 1)
Figure 1: An illustration of the THEA-Code framework detailing the autoencoder architecture and integrated IDS correction.
Differentiable IDS Channel
A central facet of THEA-Code is the incorporation of a differentiable IDS channel, implemented using a transformer-based model to simulate IDS operations, thereby facilitating error introduction in a way that allows for gradient descent optimization. This approach permits training the autoencoder end-to-end by allowing the propagation of gradients through the IDS simulation, ensuring effective learning of the coding scheme.
Entropy Constraints and Auxiliary Reconstruction
To resolve the challenge of quantizing the encoder's soft outputs into robust, correctable codewords, an entropy constraint was introduced to coerce these outputs towards a one-hot vector format. This ensures compatibility with traditional discrete decoding processes. Additionally, an auxiliary reconstruction task is embedded within the encoder to pre-train the model to reproduce the input, aiding in stabilizing the training process and enhancing the preservation of information throughout the encoding phase.
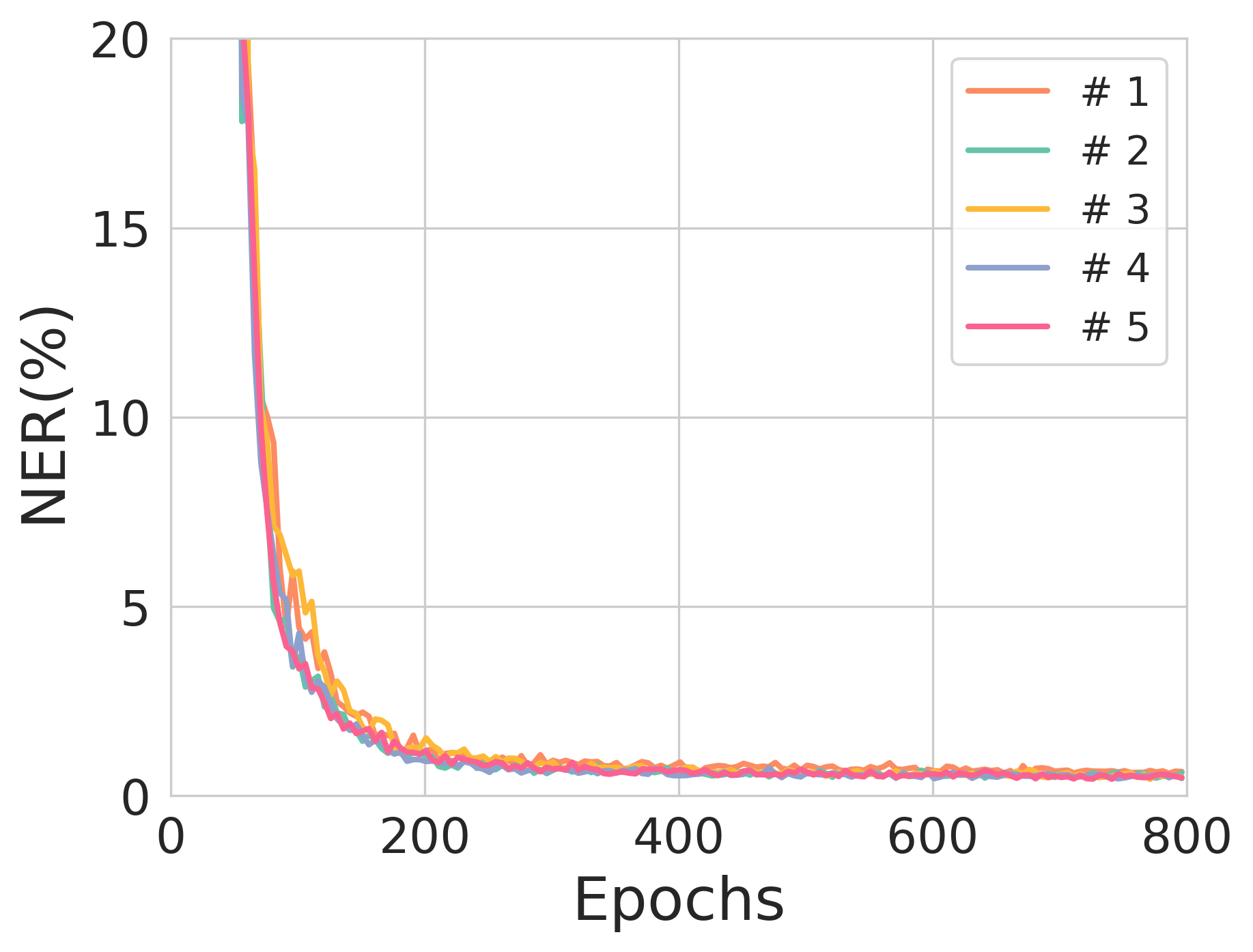
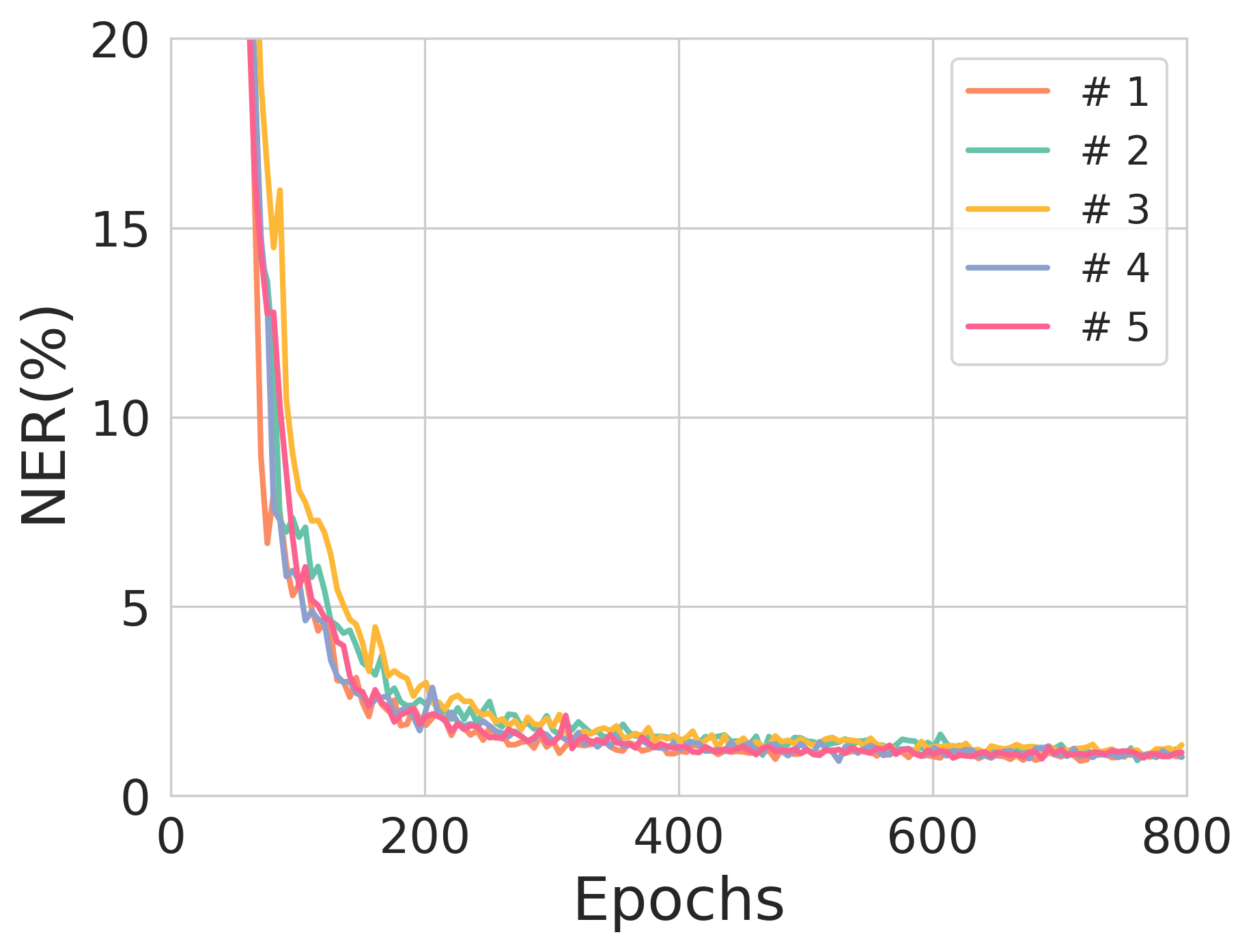
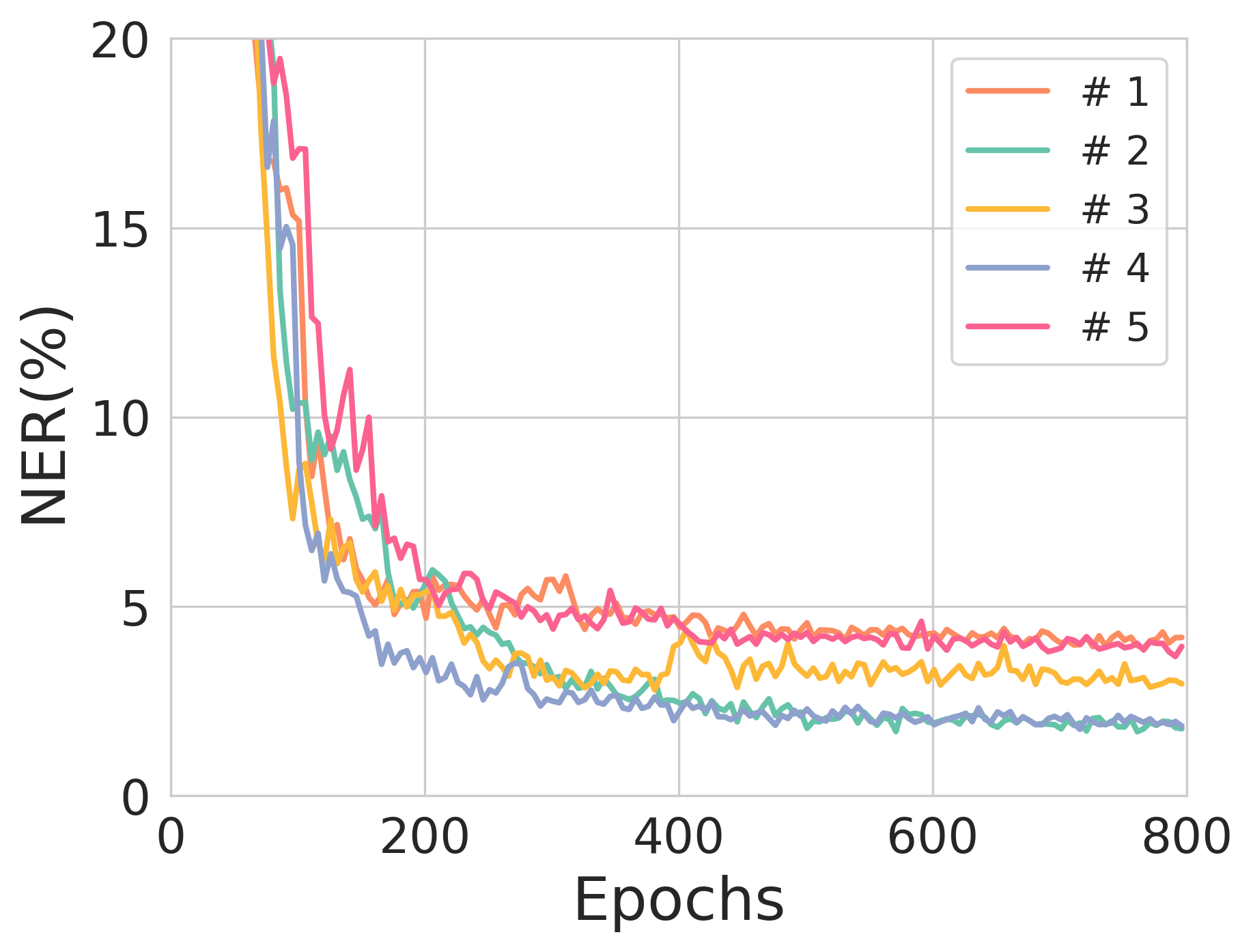
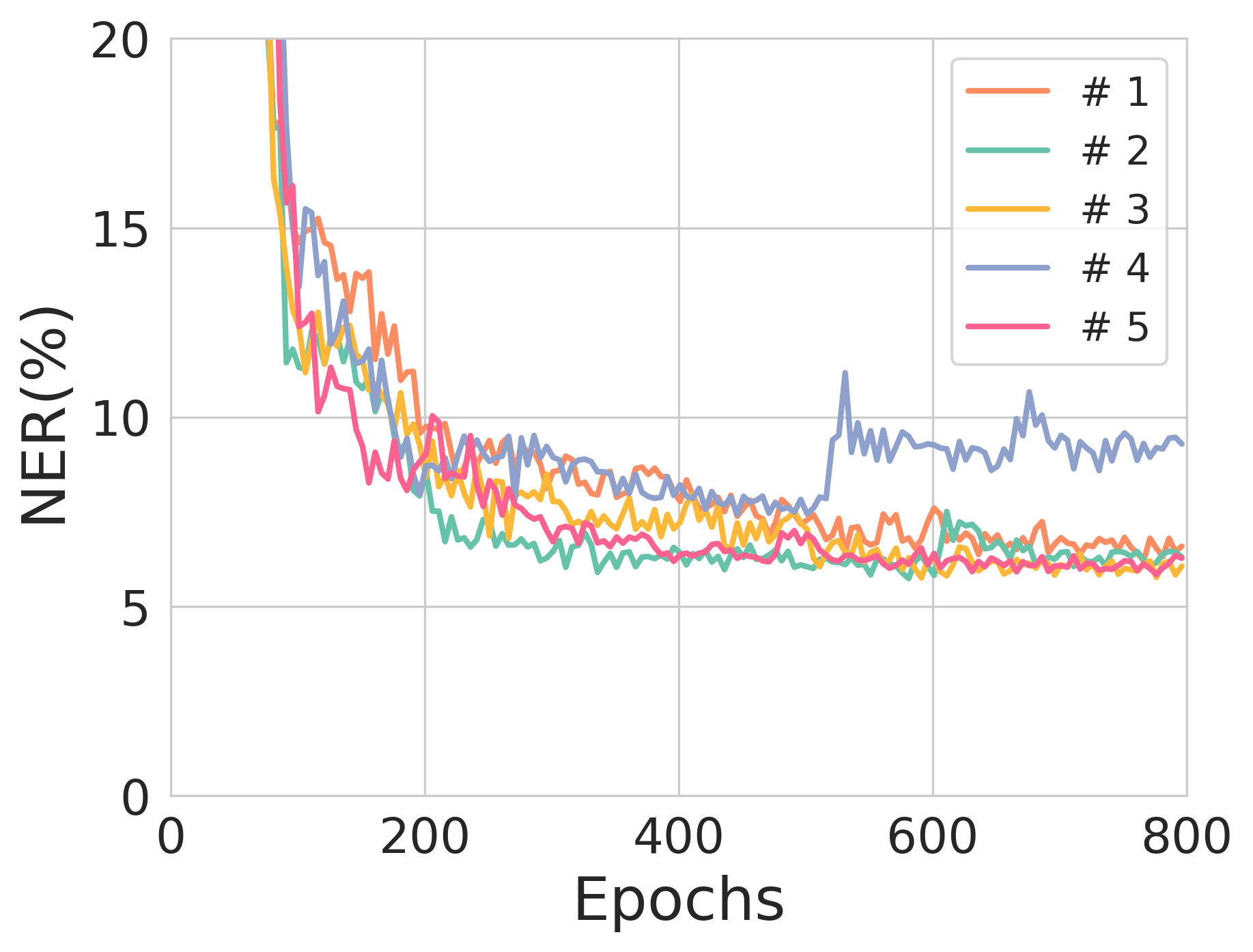
Figure 2: The validation NER across training epochs for different source sequence lengths, illustrating model stability and training robustness.
Experiments and Results
Extensive experimentation underscores THEA-Code's capability to effectively correct IDS errors in a variety of scenarios, achieving a notable reduction in nucleobase error rate (NER). Performance analyses demonstrate that THEA-Code’s performance is sensitive to encoding rate and model hyperparameters like entropy constraints. For instance, decreasing coding rates generally enhance error correction performance at the expense of reduced storage efficiency, highlighting a fundamental trade-off in system design.
Notably, during experimentation, source sequences with lengths of 90 and 100 nucleotides exhibited commendable performance with each achieving NERs of 0.77% and 1.03%, respectively, showcasing the potential for scalable deployment where error correction is necessary for substantial data integrity maintenance.
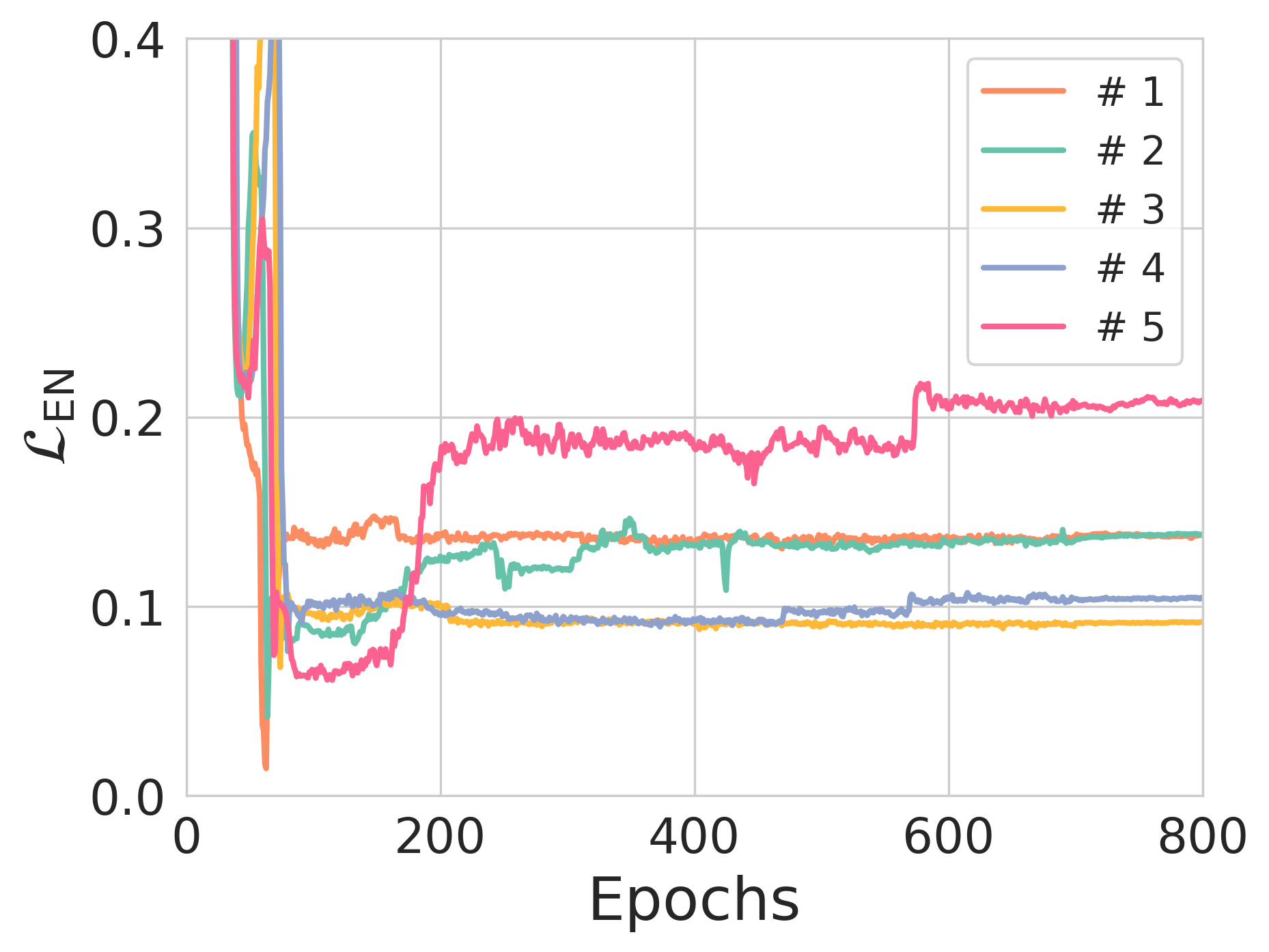
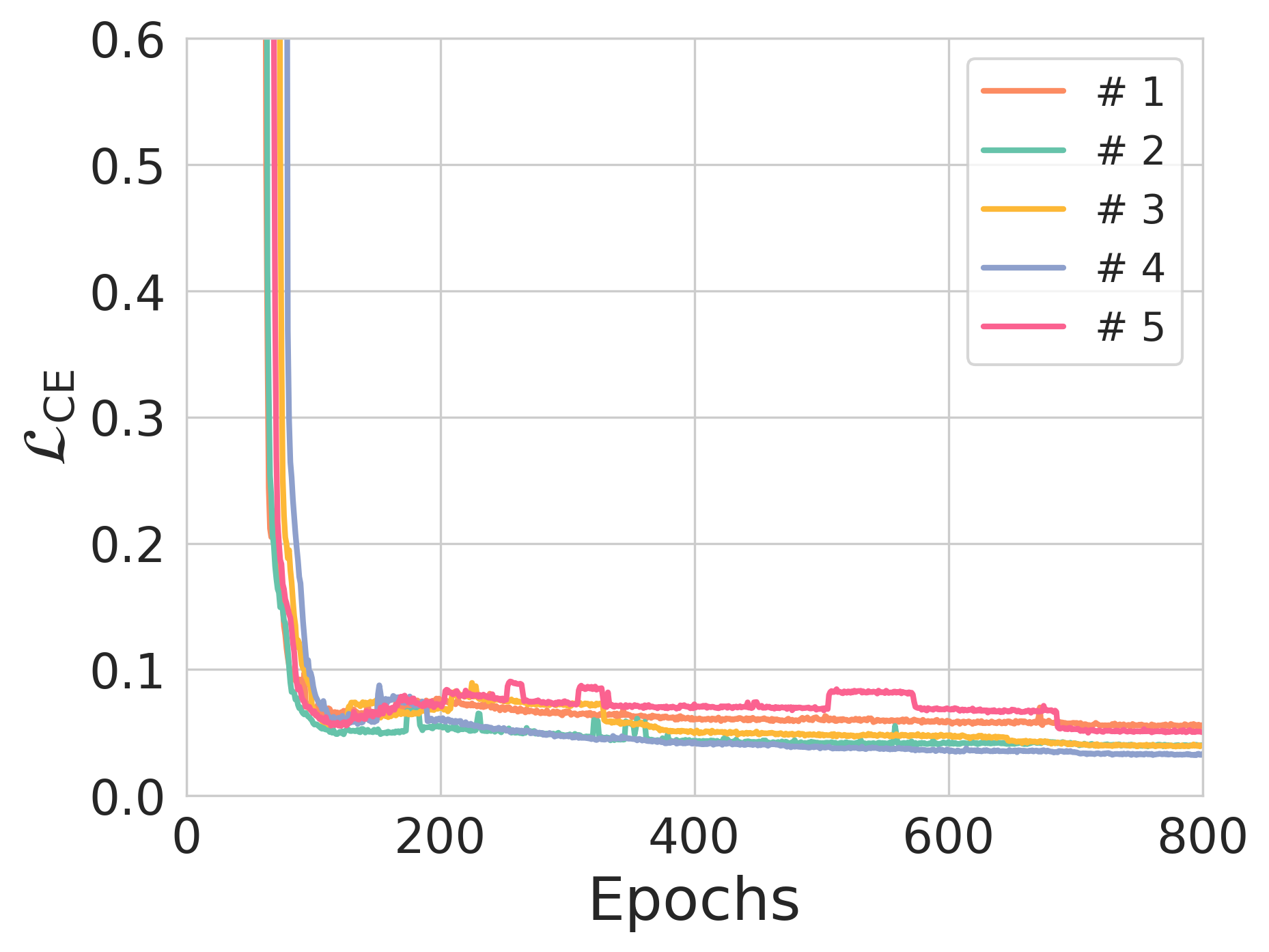
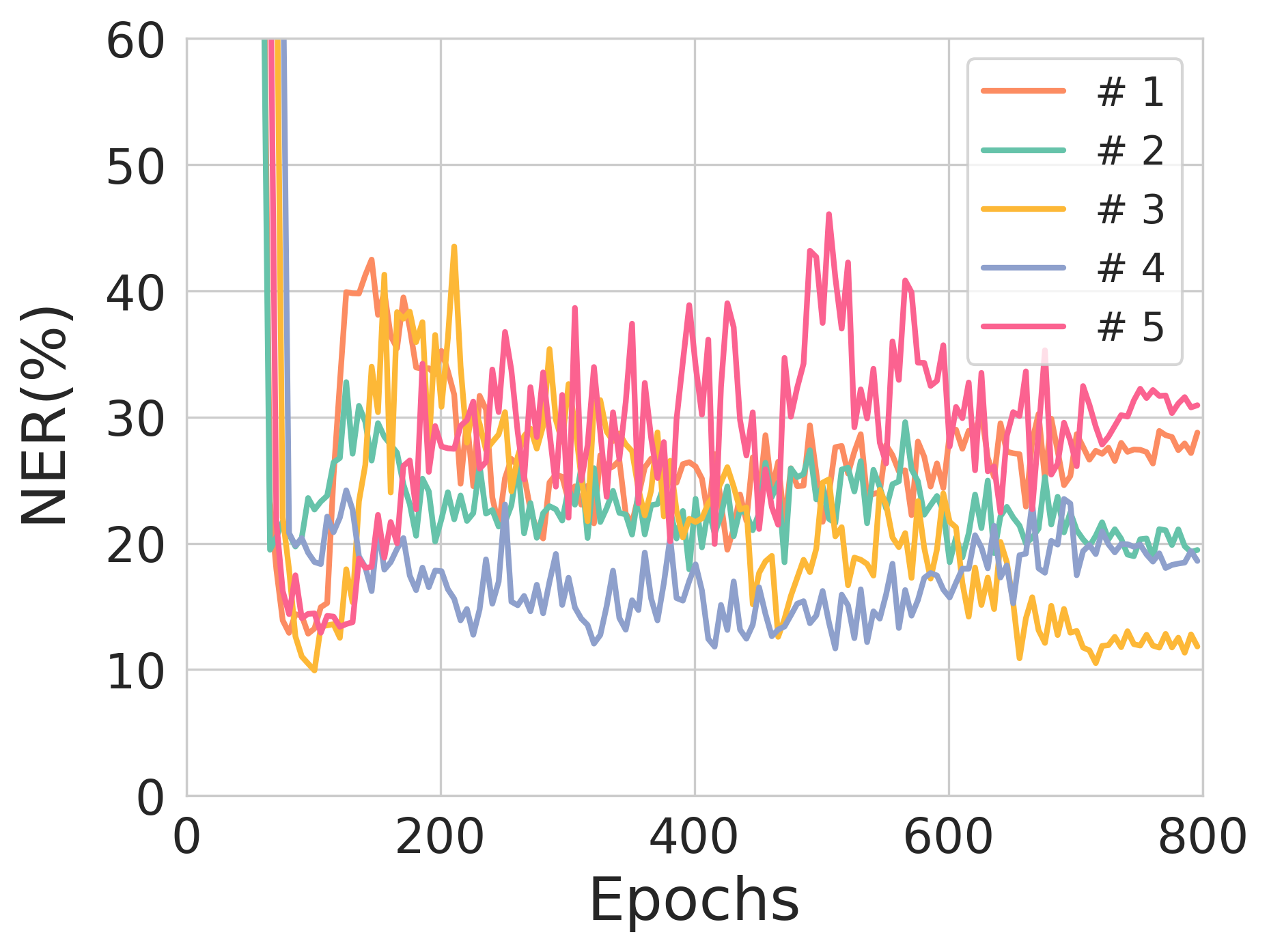
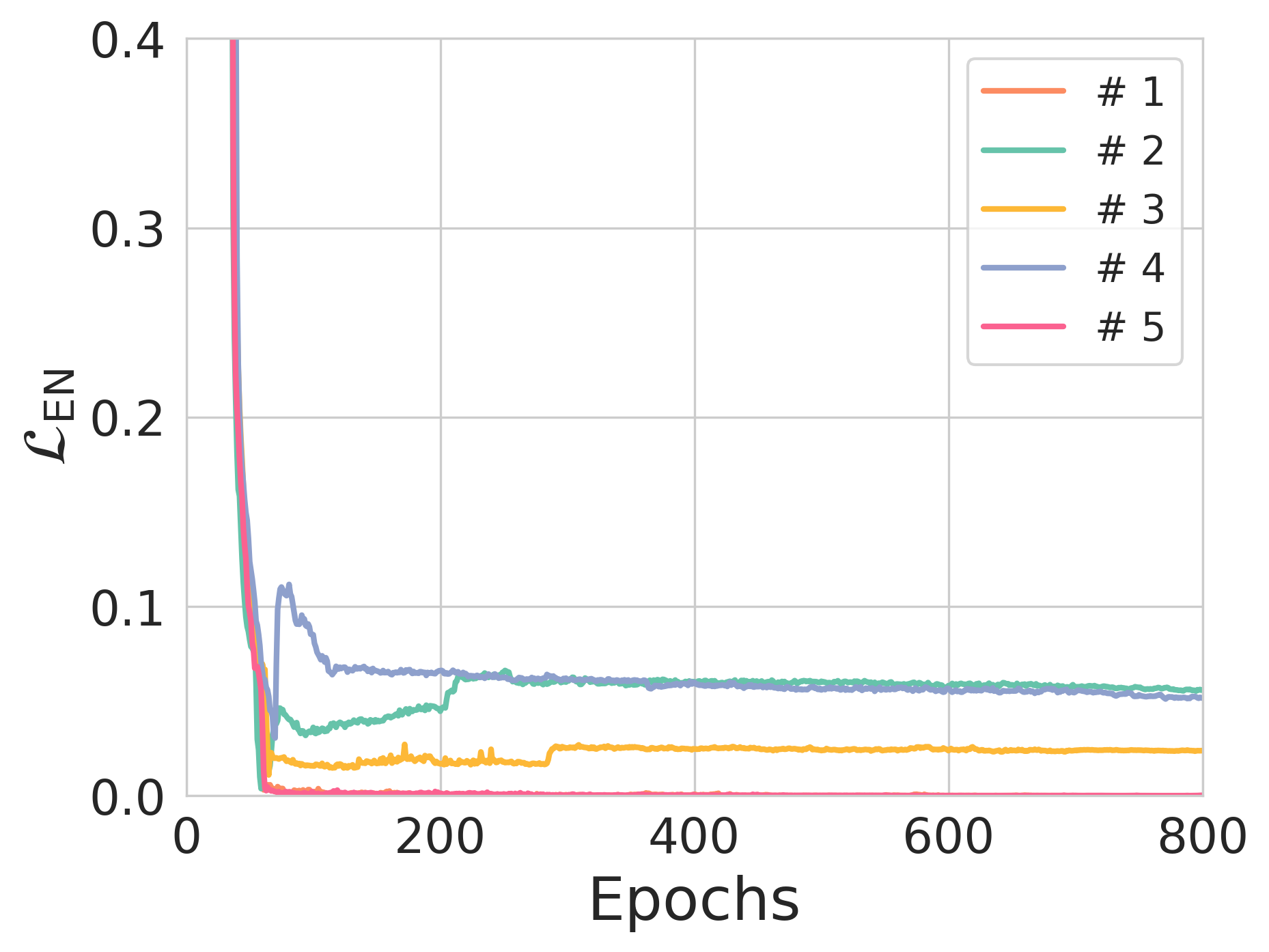
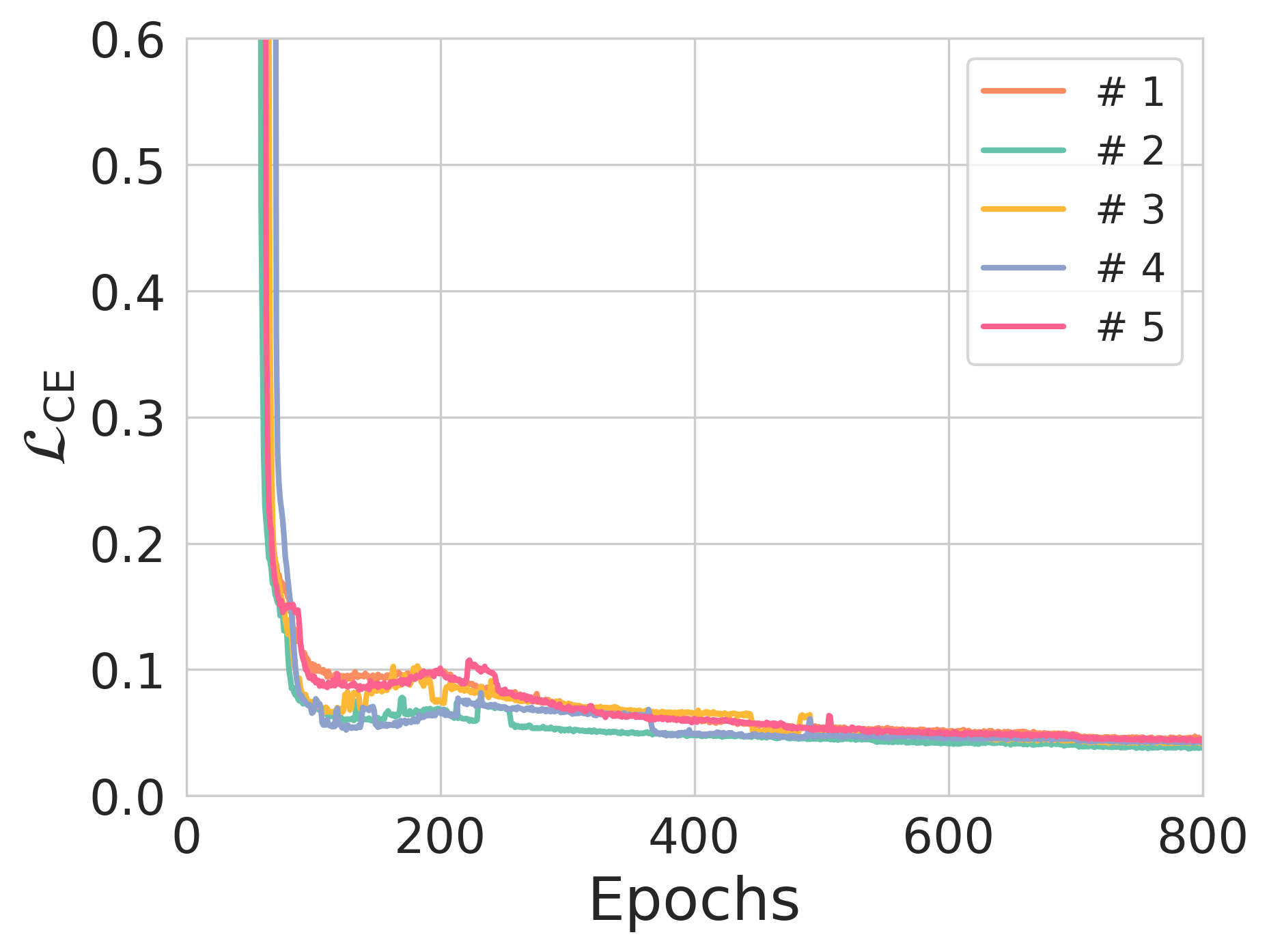
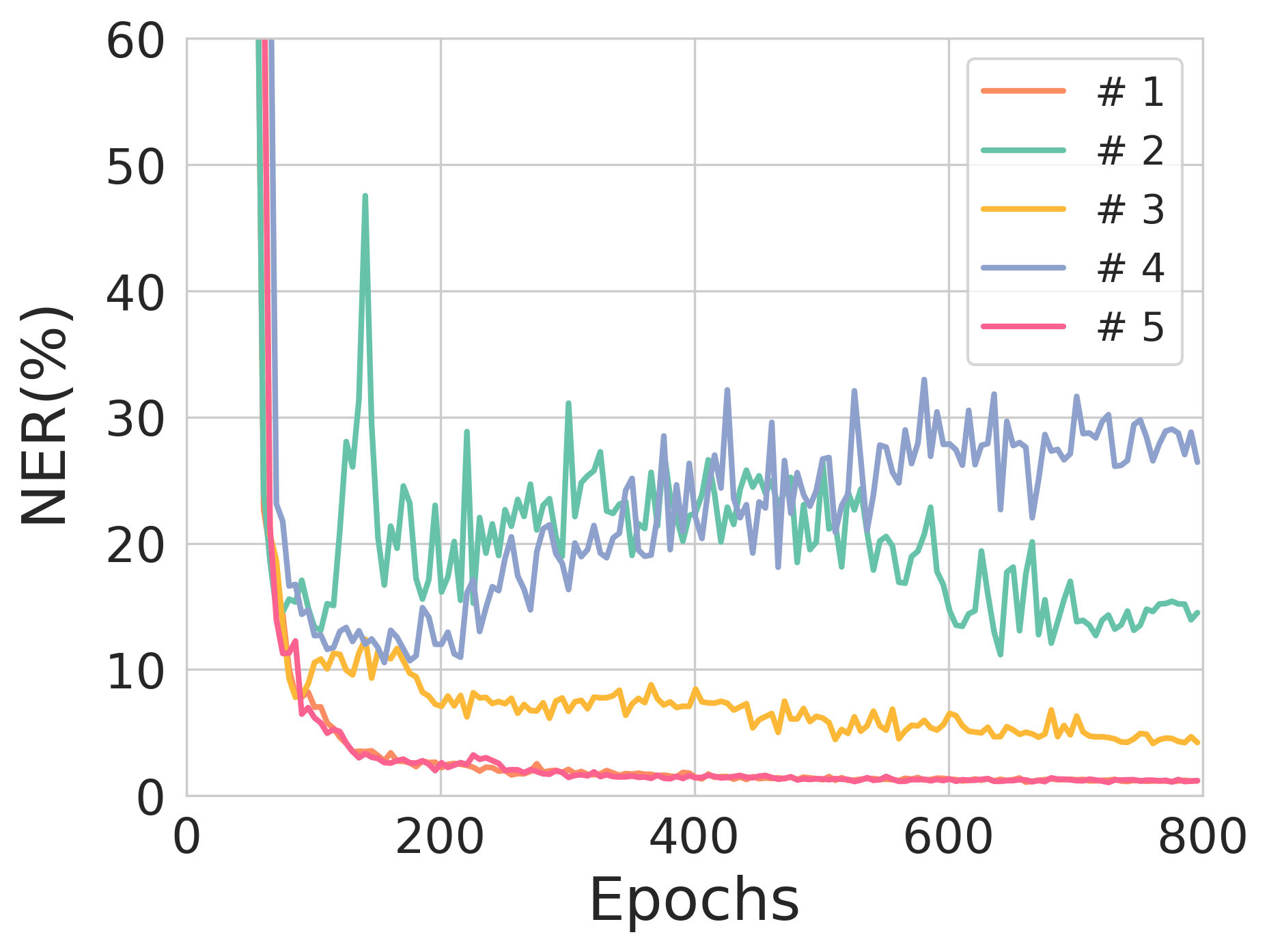
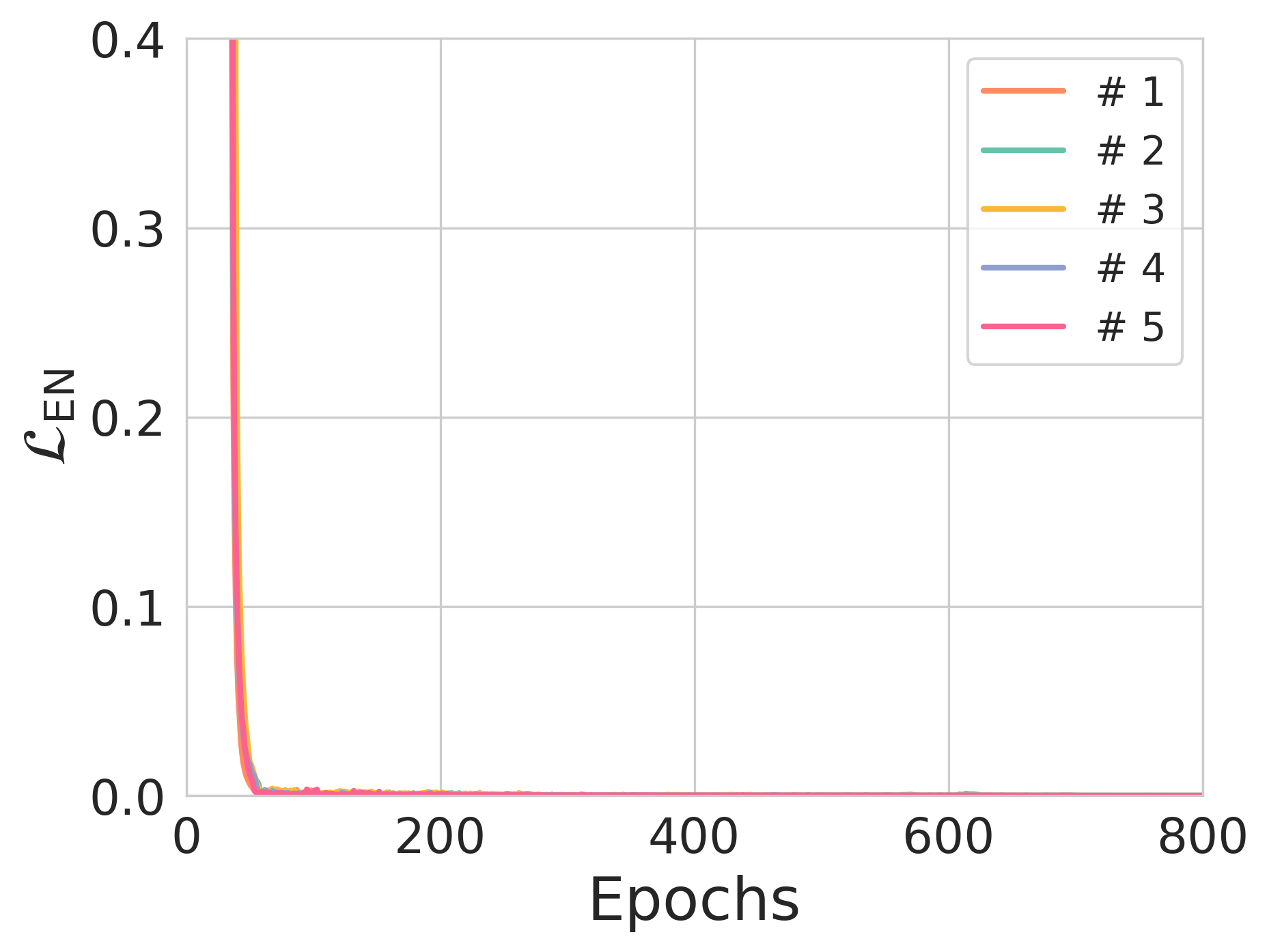
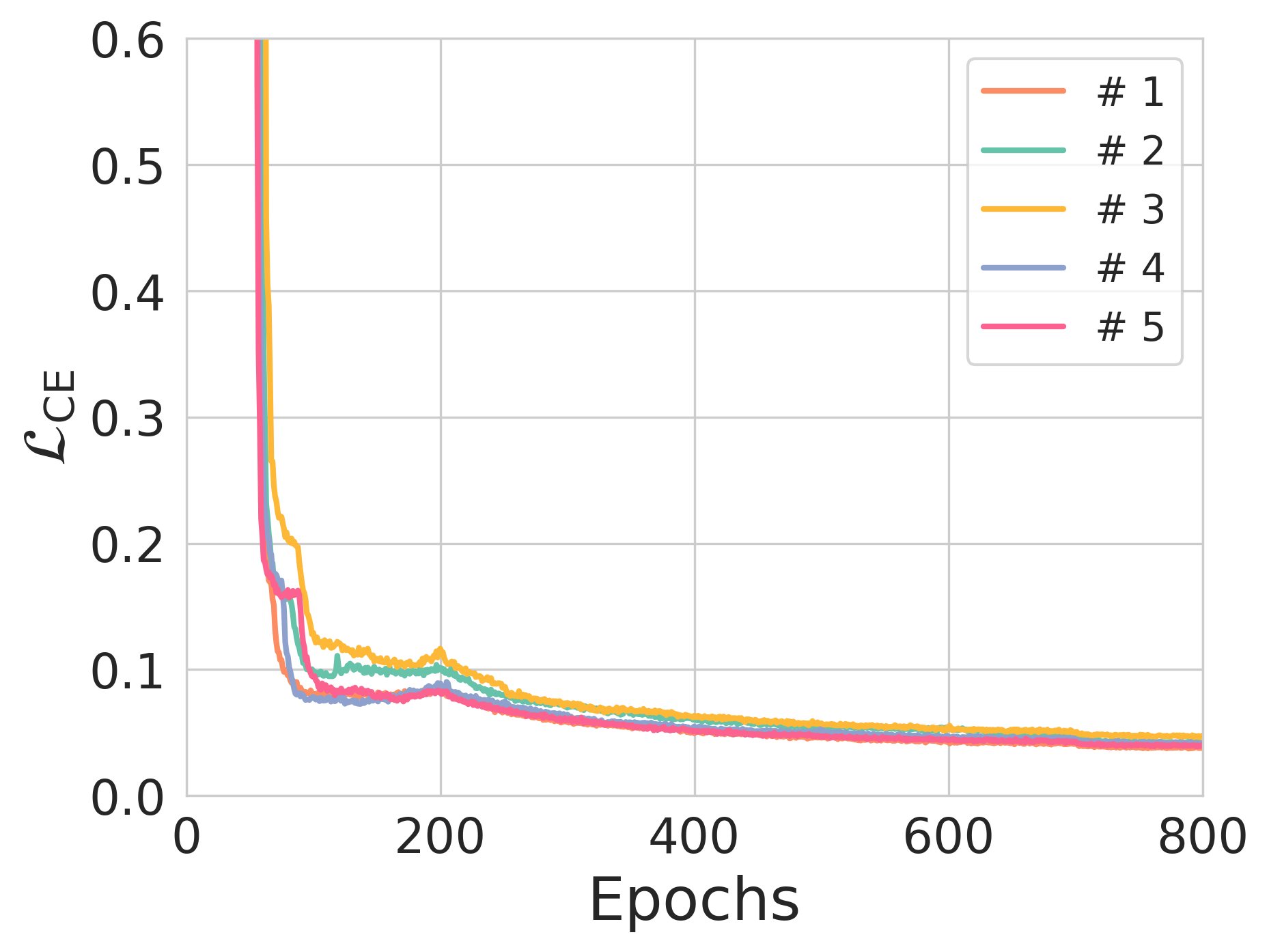
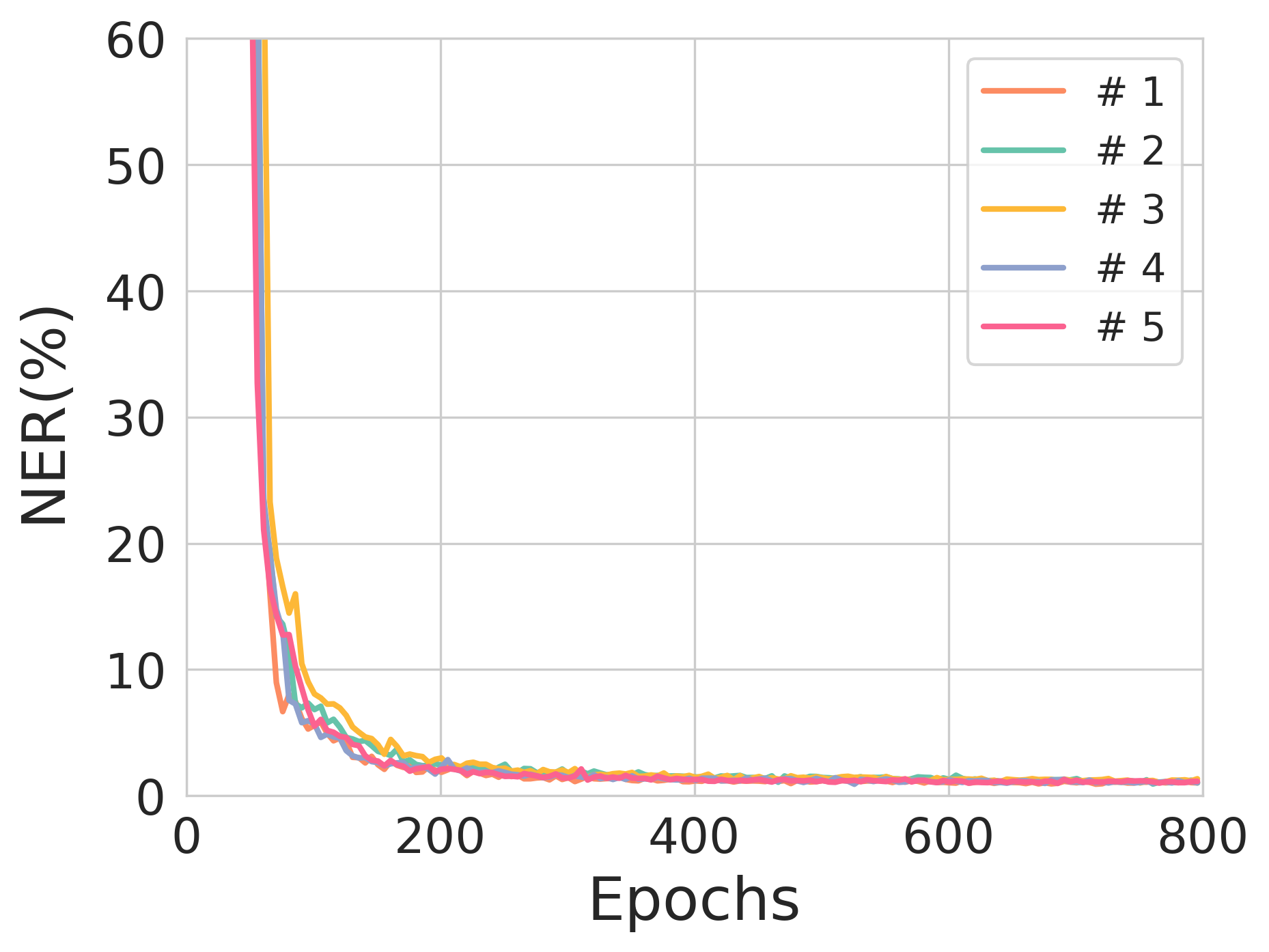
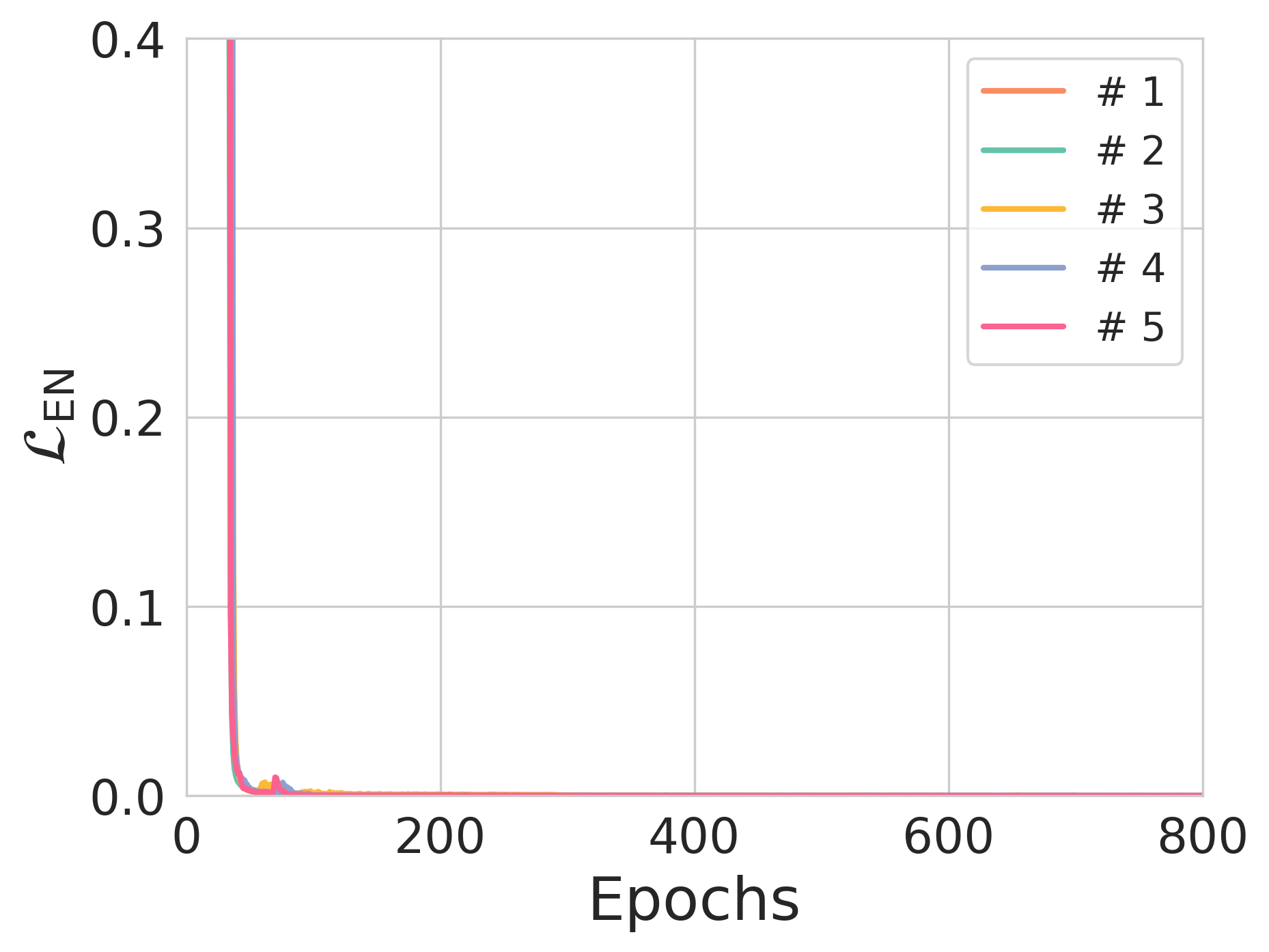
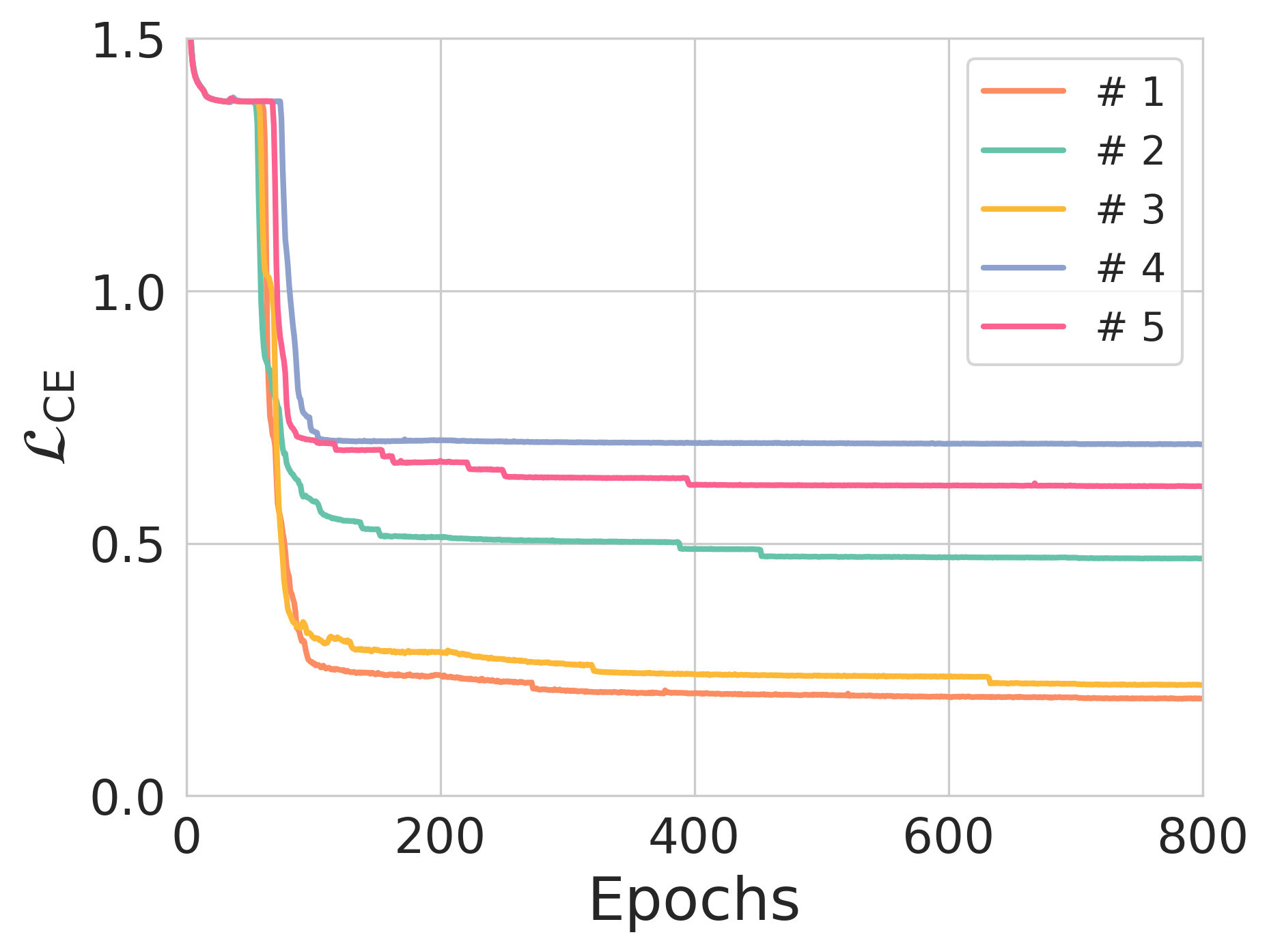
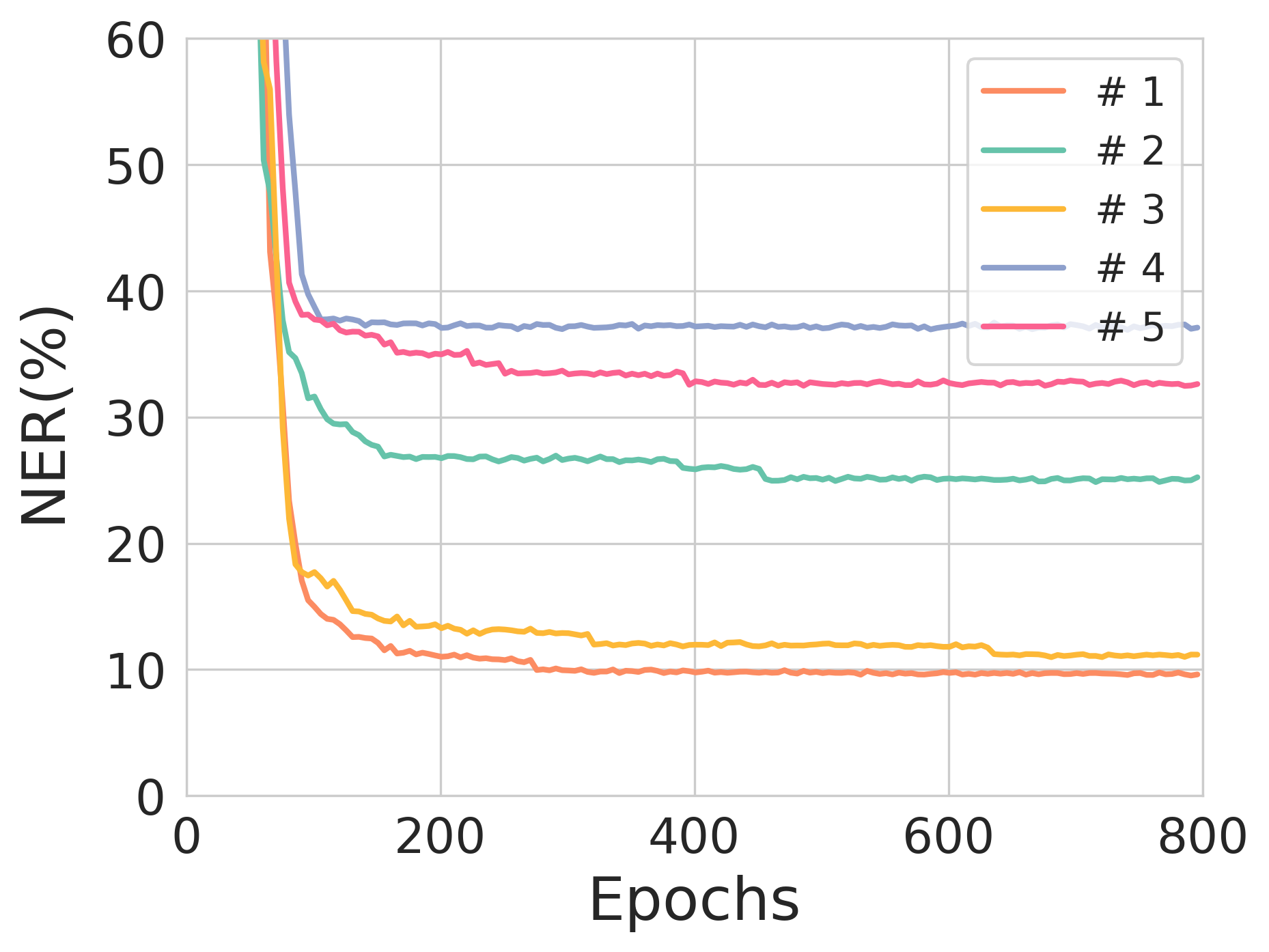
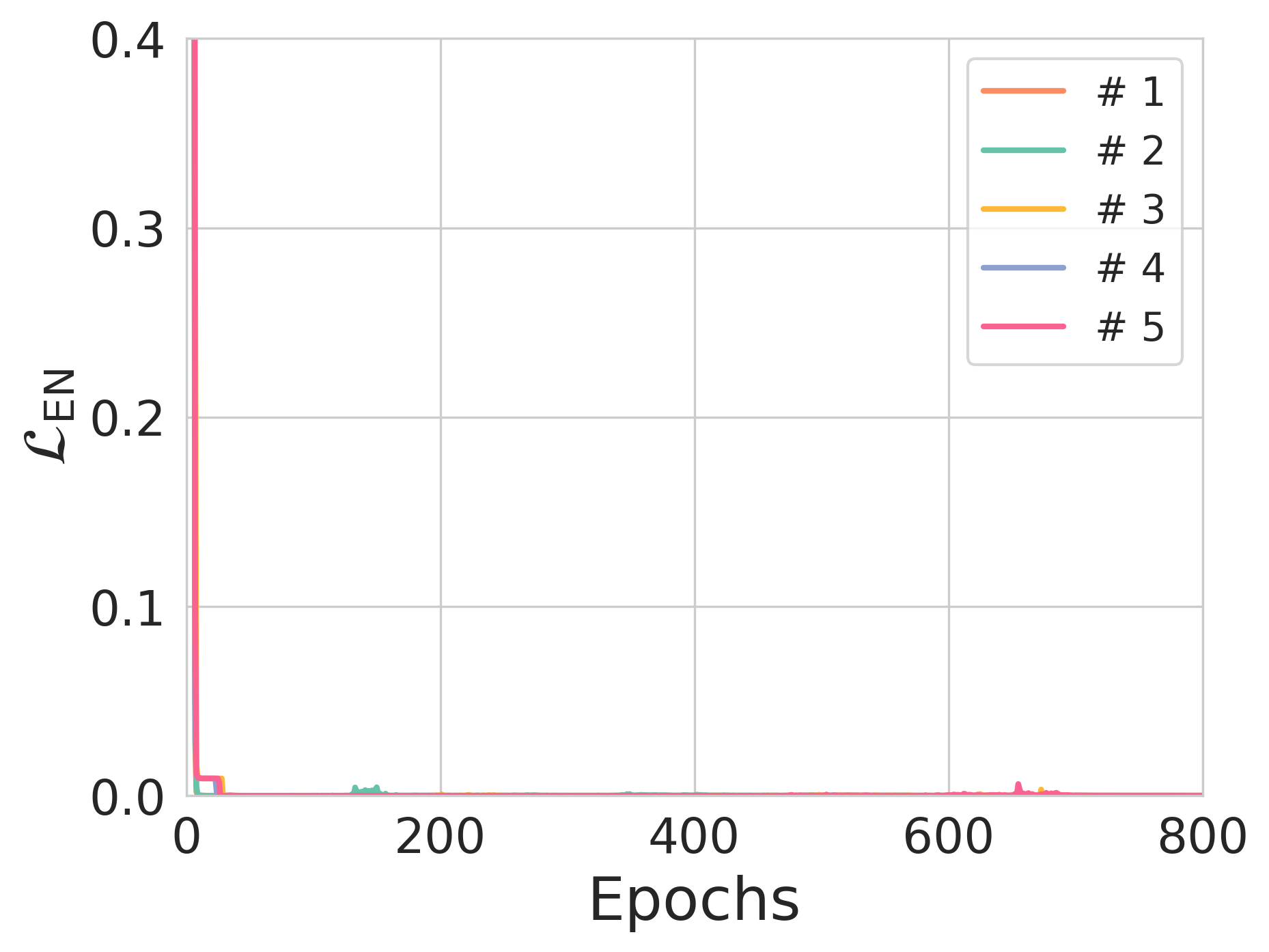
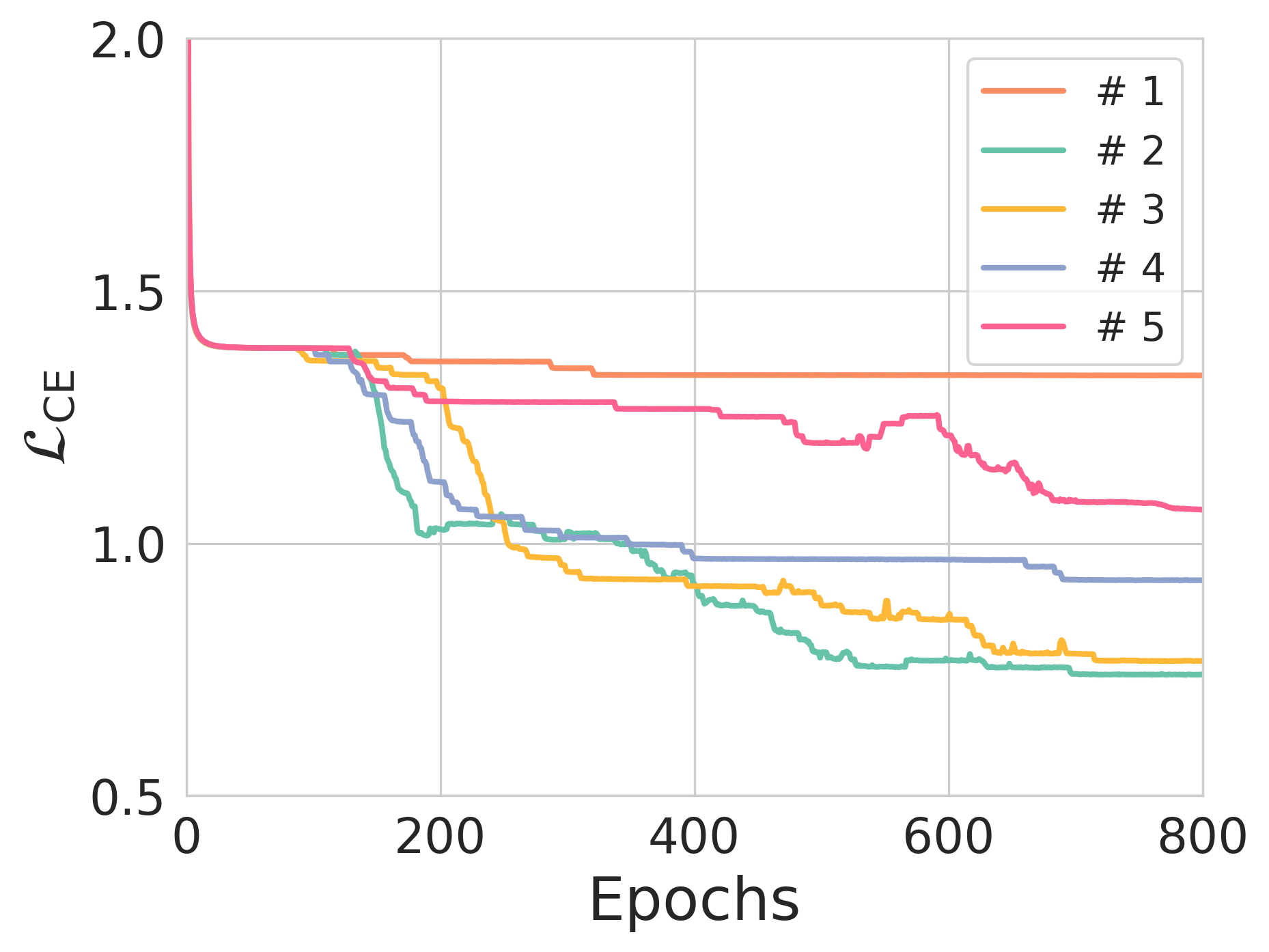
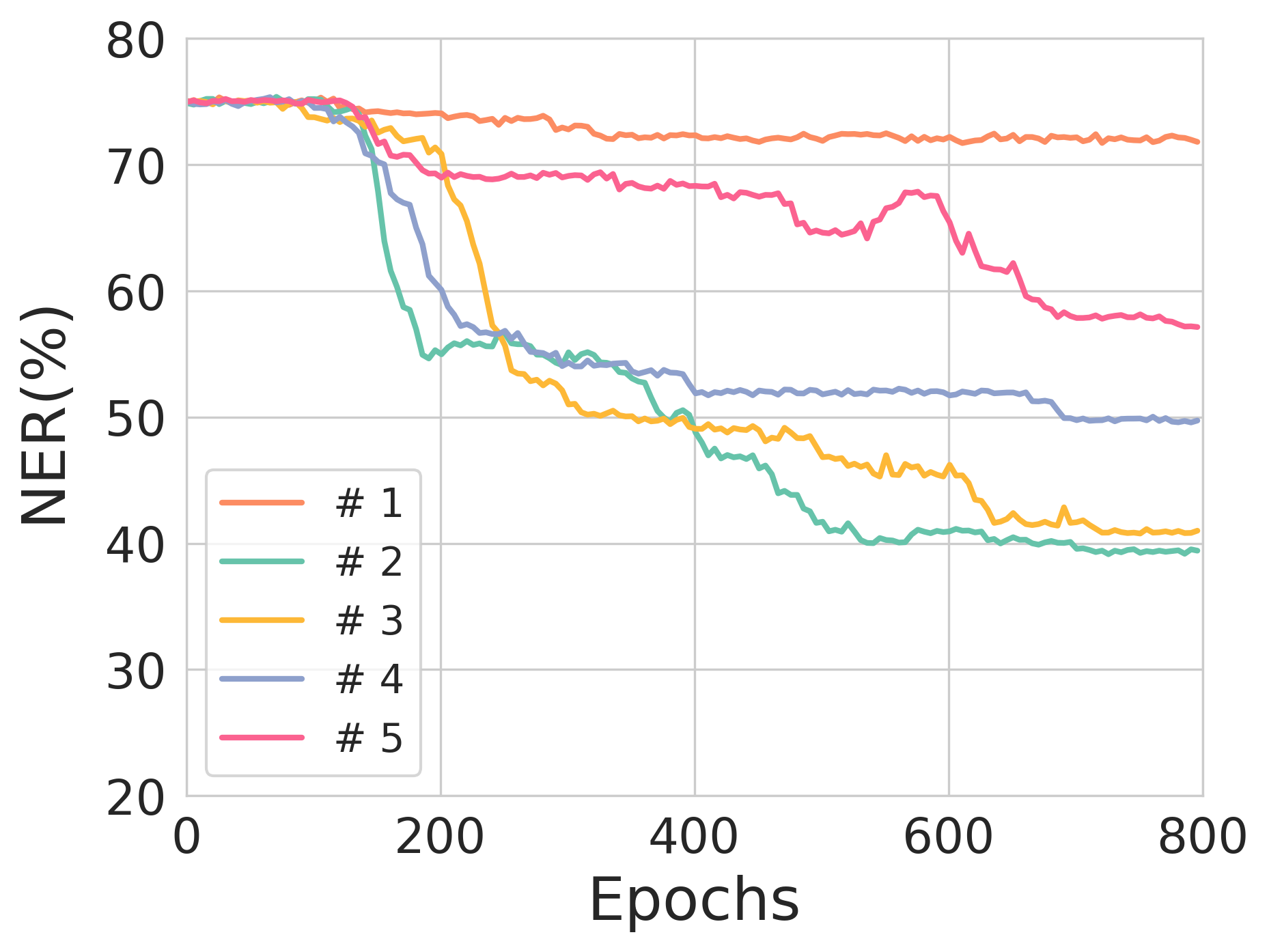
Figure 3: The effect of entropy constraints on reconstruction loss and NER across different training scenarios.
Implications and Future Developments
The proposed THEA-Code presents a substantial advancement in leveraging neural network architectures for error-correcting codes in non-traditional data channels such as DNA storage. The application of deep learning techniques offers a layer of abstraction that simplifies the design and potential adaptability of IDS-correcting codes, paving the way for innovative solutions in data storage technology.
Future research directions could explore optimizing the differentiable channel's architecture, expand the robustness of auxiliary tasks in stabilizing encoder-decoder training, and reducing computational costs through advanced neural architecture search strategies.
Conclusion
THEA-Code represents a significant stride forward in the domain of DNA data storage by integrating modern deep learning methodologies with the long-standing challenges of IDS correction. Its framework, based on a differentiable IDS channel and supported by strategic entropy control, sets a precedent for future research aiming to integrate similar techniques in the broader context of error-correcting codes.