- The paper introduces Diffree, advancing text-guided inpainting by integrating a diffusion model with an object mask predictor.
- The methodology employs a latent diffusion process and a curated OABench dataset to ensure consistent backgrounds and realistic object alignment.
- Experimental results demonstrate over 98% success rates and superior performance compared to traditional methods across established metrics.
Overview of "Diffree: Text-Guided Shape Free Object Inpainting with Diffusion Model"
The paper "Diffree: Text-Guided Shape Free Object Inpainting with Diffusion Model" introduces Diffree, an innovative approach for text-guided object inpainting within images without predefined shapes or masks. This technique seamlessly integrates new objects into existing images guided solely by textual descriptions, maintaining consistency in visual context, such as lighting and spatial orientation, without requiring human intervention to define regions for object placement.
Motivation and Background
The advent of Text-to-Image (T2I) models like Stable Diffusion and DALL-E has spurred interest in text-guided image editing, crucial for applications in advertising, virtual try-on, and design visualization. Traditional methods necessitate cumbersome user input or manual mask specifications, hindering workflow efficiency. Diffree circumvents these limitations by enabling shape-free, text-guided object addition, ensuring new objects harmonize with existing backgrounds visually.
Methodology
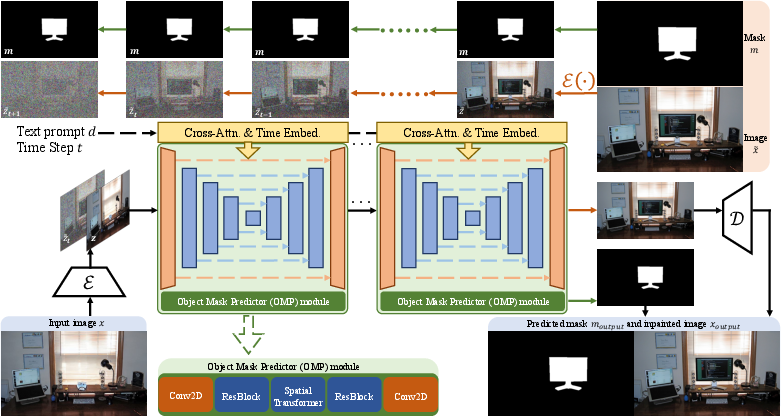
Diffree leverages a diffusion model augmented with an Object Mask Predictor (OMP) module, trained on a novel dataset called OABench. OABench is synthetically curated by using advanced image inpainting to remove objects from real-world images, creating a dataset of 74,000 tuples comprising original images, inpainted versions, object masks, and textual descriptions.
Diffree Architecture
Diffree uses a latent diffusion model built upon Stable Diffusion, enhanced with an OMP module that predicts object masks during the early steps of the diffusion process, enabling efficient inpainting:
Dataset Creation: OABench
OABench introduces a robust dataset for object inpainting, drawing on instance segmentation datasets like COCO, processed using image inpainting techniques such as PowerPaint, to ensure background consistency and realistic object alignment.
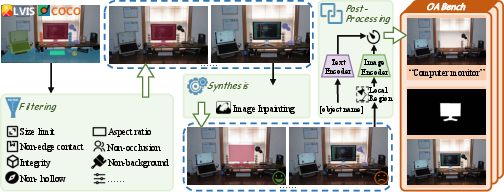
Figure 2: The data collection process of OABench.
Experimental Results
Diffree's efficacy is evaluated through rigorous experiments comparing its performance against existing methods like InstructPix2Pix and PowerPaint, showcasing superior success rates and improved metrics in background consistency, object location reasonableness, and generated object correlation, quality, and diversity.
Success Metrics
Quantitative experiments on COCO and OpenImages reveal Diffree's mastery, reflected in high success rates exceeding 98%, and impressive unified metric scores juxtaposed to traditional methods.

Figure 3: Diffree iteratively generates results. Objects added later can relate to the earlier.
Evaluation with Established Metrics
Diffree surpasses state-of-the-art models using a spectrum of evaluation metrics, including Local FID and CLIP Scores for object quality and correlation, and LPIPS for background consistency.

Figure 4: Qualitative comparisons of Diffree and different kinds of methods.
Practical Implications and Applications
Diffree embodies scalability, effortlessly integrating with other models like AnyDoor for distinct object customization tasks. Its effective mask prediction facilitates iterative inpainting, preserving background while allowing successive object additions—an attribute paramount for complex design and architectural applications.

Figure 5: Applications combined with Diffree. (a): combined with anydoor to add a specific object. (b): using GPT4V to plan what should be added.
Conclusion
Diffree represents an advancement in text-guided object inpainting, offering seamless integration of objects within backgrounds with minimal overhead. The development of OABench provides a comprehensive dataset for training models in visual consistency, enabling the potential for further exploration in diverse applications within the field of AI-driven image editing. The methodology detailed in the paper not only enhances the fidelity of inpainting results but also demonstrates potential pathways for future research in automated visual content generation and manipulation.