- The paper demonstrates that pretraining data frequency correlates with task performance using n-gram analysis and cosine gradient similarity.
- The study employs experiments on models like Pythia and OLMo, revealing a performance boost after reaching a threshold of ~400 million parameters.
- Results indicate larger models generate novel n-gram pairs, suggesting enhanced generalization compared to smaller, more memorization-prone models.
Generalization vs. Memorization: Tracing LLMs' Capabilities Back to Pretraining Data
Introduction
This paper investigates the intricate balance between generalization and memorization in LLMs during pretraining. By employing an n-gram analysis across different model sizes and pretraining data corpora, the authors aim to uncover how pretraining data contributes to LLM capabilities, examining tasks such as translation, question-answering, and multiple-choice reasoning.
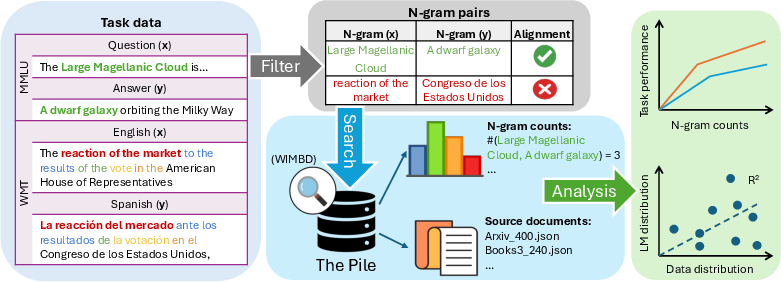
Figure 1: An overview of our proposed analysis pipeline for tracing LLM capabilities back to pretraining data.
Experimental Methodology
The paper examines LLMs, specifically Pythia and OLMo, and their pretraining corpora, notably the Pile and Dolma datasets. The authors propose a method to estimate data distribution through task-relevant n-gram pairs, mined from specific tasks.
To understand pretraining's role, the authors devised a gradient-based analysis. This involves computing the gradient similarity between pretraining data and task examples, using cosine similarity as a metric.
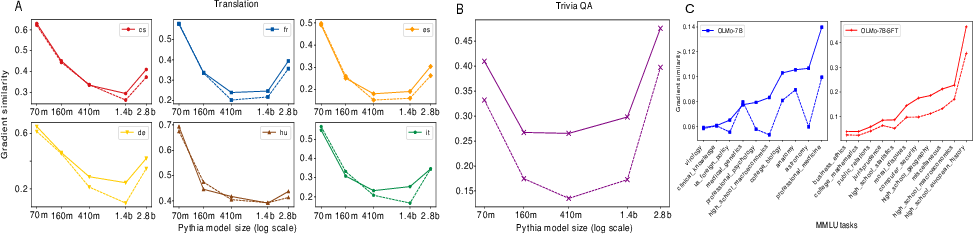
Figure 2: Cosine similarity between n-gram task gradient and pretraining gradient for different tasks and model sizes.
A key finding is the correlation between the frequency of task-related n-gram pairs in the pretraining corpus and task performance. There is a notable model size threshold—around 400 million parameters—after which performance improves significantly.
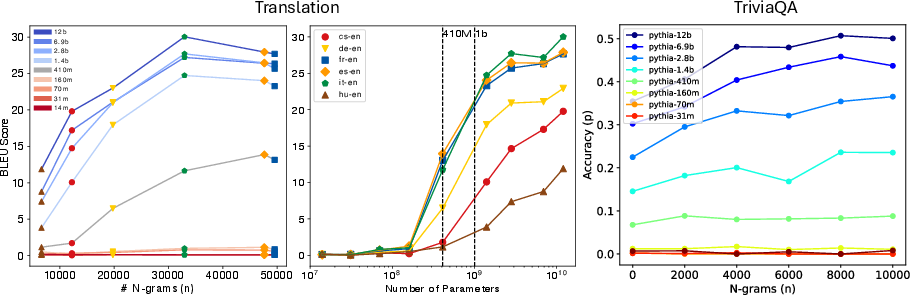
Figure 3: BLEU and exact match scores vs. total n-gram pair count in the pretraining corpus and model parameters.
The authors demonstrate that LLMs require both sufficient model size and relevant pretraining data to exhibit emergent abilities.
Memorization vs. Generalization
The study extends the definition of memorization beyond exact recall, evaluating the degree of similarity between generated text and training data. A linear regression analysis measures the similarity between LM distributions and pretraining data distributions, quantified by the R2 score.
The results illustrate that smaller models closely mirror the pretraining distribution, indicating higher memorization, while larger models show increased generalization.
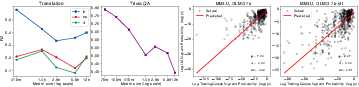
Figure 4: R2 score of linear regression from data distribution to LM distribution across different model sizes.
Data Distribution and LLM Novelty
The authors observe that larger models generate novel n-gram pairs, indicating a shift towards generalization from memorization. Instruction tuning also enhances the utilization of pretraining data, resulting in improved performance and stronger alignment with pretraining distributions.
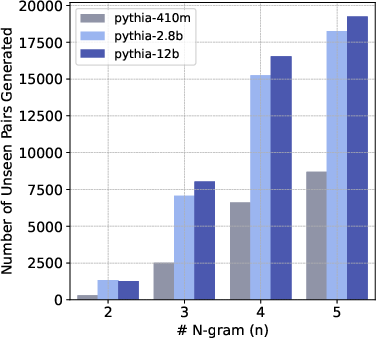
Figure 5: Number of unique n-gram pairs generated for different n values and model sizes.
Conclusion
This paper provides insights into LLMs' capabilities via n-gram pair analysis, highlighting the dynamic interplay between pretraining data, model size, and task performance. It emphasizes the importance of both memorization and generalization in achieving optimal LLM functionalities. Future research could enhance methods for filtering and analyzing task-relevant n-gram pairs, while leveraging larger, updated corpora for even more profound understanding.