- The paper introduces a finite state machine paradigm that decomposes complex multi-hop questions into single-hop sub-tasks, streamlining LLM reasoning.
- The paper details an iterative process with error checking and backtracking to minimize reasoning errors and enhance output consistency.
- The paper demonstrates FSM’s effectiveness through significant benchmark improvements, notably nearly doubling the F1 score on Musique.
FSM: A Finite State Machine Based Zero-Shot Prompting Paradigm for Multi-Hop Question Answering
The paper "FSM: A Finite State Machine Based Zero-Shot Prompting Paradigm for Multi-Hop Question Answering" explores the challenges faced by LLMs in multi-hop question answering (MHQA) tasks. It introduces a new prompting paradigm, known as the Finite State Machine (FSM), designed to enhance the reasoning capabilities of LLMs by decomposing complex questions into manageable sub-tasks.
Introduction
Multi-hop question answering presents significant challenges due to its requirement for reasoning over interconnected pieces of information across multiple contexts. Traditional methods for addressing these challenges often involve manual intervention or domain-specific fine-tuning, both demanding extensive resources and expertise. Furthermore, existing approaches frequently suffer from issues like hallucination, limited context length handling, and error propagation. FSM aims to systematically improve the effectiveness and reliability of LLMs in such tasks by employing an automaton-like, iterative process for decomposing questions.
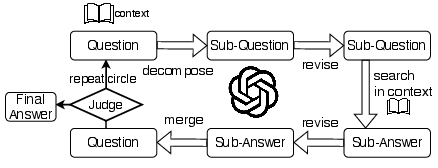
Figure 1: The abstract flow chart of FSM.
FSM Methodology
FSM employs a structured, iterative approach to break down complex questions into simpler, single-hop sub-questions, which are progressively addressed. Each sub-question is handled independently and evaluated, allowing FSM to self-correct errors as they arise, thereby mitigating the propagation of erroneous conclusions.
Strategies
- Iterative Decomposition: FSM differs from traditional chain-of-thought (COT) techniques by using multi-turn interactions. Each interaction focuses on a single sub-question, facilitating clearer understanding and execution of instructions.
- Error Checking and Backtracking: After each sub-question is resolved, FSM checks for irregularities in the reasoning process and allows for corrective adjustments, reducing the likelihood of error propagation.
- Final Review Step: By summing up all sub-question answers, FSM ensures consistency across different sub-problems, solidifying the final aggregate answer.
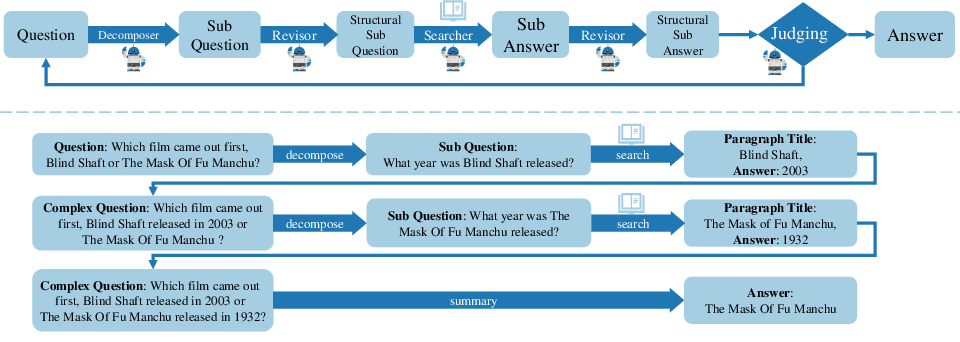
Figure 2: The flow chart of proposed FSM and a simple case in detail. A multi-hop question is solved step by step orderly.
Experimental Evaluation
Extensive experiments on benchmarks such as HotpotQA, 2WikiMultiHopQA, and Musique demonstrate FSM's superiority in challenging MHQA environments. Notably, on Musique, FSM almost doubled the F1 score compared to baseline models. The study establishes FSM's capability to produce formatted outputs consistently, reducing post-process extraction difficulties and enhancing the overall trustworthiness of the LLM's responses.
The results can be categorized into two settings:
- Direct answer generation without supporting evidence.
- Answer generation with supporting evidence and reasoning chain verification.
FSM's advantage in producing accurate formats and consistent outputs was highlighted in both settings, showcasing its robustness against hallucinations and formatting errors prevalent in other methods.

Figure 3: The outputs of FSM are standard JSON format.
Discussion
Error analysis pinpointed several types of errors in existing methods, such as reasoning loss, formatting issues, incorrect decomposition, and hallucination responses. Through careful sub-task management, FSM aims to address these weaknesses effectively.
FSM also aligns the LLM's processing closely with the structured decomposition found in classical automaton theories, providing both precision and interpretability. This structured approach reduces the cognitive load on LLMs and enables more accurate execution of complex instructions.

Figure 4: There are some error format examples for COT.
Conclusion
FSM represents a significant step toward optimizing LLM prompting techniques for MHQA tasks. By automating the decomposition and iterative handling of sub-questions, FSM improves accuracy and reduces the occurrence of reasoning errors. This paradigm holds potential for application in other complex reasoning tasks, such as natural language to SQL conversion, further extending its impact in AI research and deployment.

Figure 5: Contrast between baseline and FSM. There are some error examples for baseline.
In conclusion, FSM not only enhances the reliability of LLM responses by addressing reasoning and format errors but also sets a foundation for future advancements in automaton-like approaches in AI-driven reasoning systems.