- The paper proposes ReLCE, a method leveraging residual and context encoding to address offline-to-online reinforcement learning in fluctuating dynamics.
- It employs a context encoder to infer latent changes in the environment, enabling the residual agent to adaptively adjust the offline base policy.
- Experimental results on D4RL MuJoCo benchmarks show enhanced sample efficiency and superior adaptability compared to baseline approaches.
"Residual Learning and Context Encoding for Adaptive Offline-to-Online Reinforcement Learning"
The paper presents an approach to address adaptive reinforcement learning (RL) in environments where dynamics may change between offline and online training phases. The method, named Residual Learning and Context Encoding (ReLCE), combines residual learning with context encoding to adaptively fine-tune policies in changing dynamics conditions.
This research tackles an offline-to-online RL problem where the transition dynamics vary, a scenario often ignored by typical offline RL methods. Conventional approaches assume consistent dynamics across training phases, limiting their applicability in dynamically changing environments. ReLCE introduces a framework where a residual agent augments a base offline policy to react to variations, leveraging a context encoder to infer latent dynamics changes from historical data.
The offline-to-online transition is modeled using a contextual representation that captures environmental changes. Through a context encoder, a latent variable is derived to adapt the policy to the altered dynamics. Training involves a residual policy that modifies actions of the offline base policy using this contextual information.
Figure 1: ReLCE overview - The offline policy πoffline is used as a base policy trained on existing datasets D. The context encoder infers the changes in the environment, and the residual agent compensates for the modifications by considering the context and offline policy.
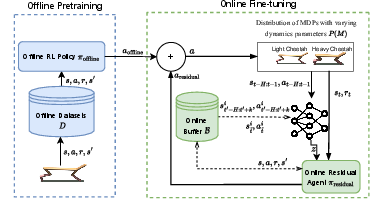
Figure 1: Architecture of the proposed ReLCE method.
Implementation and Experiments
The architecture consists of an offline agent trained with the COMBO algorithm, a context encoder to discern environmental changes, and a residual agent that employs a context-aware policy. The method was tested on D4RL MuJoCo benchmarks, where the transition dynamics are intentionally varied at each episode reset.
The context encoder's training is pivotal, relying on multi-step prediction losses to learn a latent space that accurately represents dynamics changes. This enables the residual policy to provide corrective actions based on predicted state transitions, enhancing efficiency beyond static offline-to-online techniques.
In the experiments, ReLCE demonstrated superior adaptability to dynamic changes and generalized well to conditions not encountered during training. Figures representing learning curves (not shown here) affirm that ReLCE outperforms baselines like Recurrent SAC, PEARL, and Adaptive BC in terms of sample efficiency and adaptability to dynamic changes in the environment.
Challenges and Future Work
A notable design decision is the constant coefficient controlling the influence balance between the offline and residual policies. This static parameter selection could be dynamic, optimizing based on training progression to minimize early performance drops.
Future iterations could explore automatic hyper-parameter tuning to enhance learning stability. Additionally, expanding the scope of dynamics considered during training could bolster out-of-distribution generalization capabilities.
Conclusion
ReLCE introduces a novel reliance on contextually encoded representations within an adaptive policy framework to enhance offline-to-online RL's efficacy in variable environments. By effectively inferring environment dynamics changes, ReLCE sets a precedent for future investigations into adaptive policy learning in non-static settings. The results are promising for broadening RL applications in real-world scenarios where environmental dynamics fluctuate unpredictably.