How Far Are We From AGI: Are LLMs All We Need?
Abstract: The evolution of AI has profoundly impacted human society, driving significant advancements in multiple sectors. AGI, distinguished by its ability to execute diverse real-world tasks with efficiency and effectiveness comparable to human intelligence, reflects a paramount milestone in AI evolution. While existing studies have reviewed specific advancements in AI and proposed potential paths to AGI, such as LLMs, they fall short of providing a thorough exploration of AGI's definitions, objectives, and developmental trajectories. Unlike previous survey papers, this work goes beyond summarizing LLMs by addressing key questions about our progress toward AGI and outlining the strategies essential for its realization through comprehensive analysis, in-depth discussions, and novel insights. We start by articulating the requisite capability frameworks for AGI, integrating the internal, interface, and system dimensions. As the realization of AGI requires more advanced capabilities and adherence to stringent constraints, we further discuss necessary AGI alignment technologies to harmonize these factors. Notably, we emphasize the importance of approaching AGI responsibly by first defining the key levels of AGI progression, followed by the evaluation framework that situates the status quo, and finally giving our roadmap of how to reach the pinnacle of AGI. Moreover, to give tangible insights into the ubiquitous impact of the integration of AI, we outline existing challenges and potential pathways toward AGI in multiple domains. In sum, serving as a pioneering exploration into the current state and future trajectory of AGI, this paper aims to foster a collective comprehension and catalyze broader public discussions among researchers and practitioners on AGI.
- 2022a. 10 years of Amazon robotics: how robots help sort packages, move product, and improve safety. https://www.aboutamazon.com/news/operations/10-years-of-amazon-robotics-how-robots-help-sort-packages-move-product-and-improve-safety. Accessed: 2023-09-21.
- 2022b. Amazon introduces Sparrow—a state-of-the-art robot that handles millions of diverse products. https://www.aboutamazon.com/news/operations/amazon-introduces-sparrow-a-state-of-the-art-robot-that-handles-millions-of-diverse-products. Accessed: 2023-09-21.
- 2023. TinyChat: Efficient and Lightweight Chatbot with AWQ. https://github.com/mit-han-lab/llm-awq/tree/main/tinychat.
- Persistent Anti-Muslim Bias in Large Language Models. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society (AIES ’21). Association for Computing Machinery, New York, NY, USA, 298–306. https://doi.org/10.1145/3461702.3462624
- John M Abowd and Lars Vilhuber. 2008. How protective are synthetic data?. In International Conference on Privacy in Statistical Databases. Springer, 239–246.
- Accurate structure prediction of biomolecular interactions with AlphaFold 3. Nature (2024). https://doi.org/10.1038/s41586-024-07487-w
- Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023).
- The cringe loss: Learning what language not to model. arXiv preprint arXiv:2211.05826 (2022).
- Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691 (2022).
- Anthropic AI. 2024. Claude 3. https://www.anthropic.com/news/claude-3-family.
- ReST meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent. arXiv:2312.10003 [cs.CL]
- RL4F: Generating Natural Language Feedback with Reinforcement Learning for Repairing Model Outputs. arXiv preprint arXiv:2305.08844 (2023).
- Flamingo: a visual language model for few-shot learning. NeurIPS (2022).
- Arwa I Alhussain and Aqil M Azmi. 2021. Automatic story generation: A survey of approaches. ACM Computing Surveys (CSUR) 54, 5 (2021), 1–38.
- SantaCoder: don’t reach for the stars! arXiv:2301.03988 [cs.SE]
- Guidelines for Human-AI Interaction. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems (CHI ’19). Association for Computing Machinery, New York, NY, USA, 1–13. https://doi.org/10.1145/3290605.3300233
- DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale. arXiv:2207.00032 [cs.LG]
- MathQA: Towards Interpretable Math Word Problem Solving with Operation-Based Formalisms. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Jill Burstein, Christy Doran, and Thamar Solorio (Eds.). Association for Computational Linguistics, Minneapolis, Minnesota, 2357–2367. https://doi.org/10.18653/v1/N19-1245
- Concrete problems in AI safety. arXiv preprint arXiv:1606.06565 (2016).
- Palm 2 technical report. arXiv preprint arXiv:2305.10403 (2023).
- ChainForge: A Visual Toolkit for Prompt Engineering and LLM Hypothesis Testing. https://doi.org/10.48550/arXiv.2309.09128 arXiv:2309.09128 [cs].
- A general language assistant as a laboratory for alignment. arXiv preprint arXiv:2112.00861 (2021).
- Program Synthesis with Large Language Models. arXiv:2108.07732 [cs.PL]
- OmniFill: Domain-Agnostic Form Filling Suggestions Using Multi-Faceted Context. https://doi.org/10.48550/arXiv.2310.17826 arXiv:2310.17826 [cs].
- A general theoretical paradigm to understand learning from human preferences. arXiv preprint arXiv:2310.12036 (2023).
- Improving Language Models with Advantage-based Offline Policy Gradients. arXiv preprint arXiv:2305.14718 (2023).
- Explaining neural scaling laws. arXiv preprint arXiv:2102.06701 (2021).
- Sequential Modeling Enables Scalable Learning for Large Vision Models. arXiv preprint arXiv:2312.00785 (2023).
- Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862 (2022).
- Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073 (2022).
- Examination of Ethical Principles for LLM-Based Recommendations in Conversational AI. In 2023 International Conference on Platform Technology and Service (PlatCon). IEEE, 109–113.
- Learning to Exploit Temporal Structure for Biomedical Vision-Language Processing. arXiv:2301.04558 [cs.CV]
- Is the Most Accurate AI the Best Teammate? Optimizing AI for Teamwork. Proceedings of the AAAI Conference on Artificial Intelligence 35, 13 (May 2021), 11405–11414. https://doi.org/10.1609/aaai.v35i13.17359 Number: 13.
- Updates in Human-AI Teams: Understanding and Addressing the Performance/Compatibility Tradeoff. Proceedings of the AAAI Conference on Artificial Intelligence 33, 01 (July 2019), 2429–2437. https://doi.org/10.1609/aaai.v33i01.33012429 Number: 01.
- Does the Whole Exceed its Parts? The Effect of AI Explanations on Complementary Team Performance. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems. ACM, Yokohama Japan, 1–16. https://doi.org/10.1145/3411764.3445717
- Chris Baraniuk. 2018. Exclusive: UK police wants AI to stop violent crime before it happens | New Scientist. https://www.newscientist.com/article/2186512-exclusive-uk-police-wants-ai-to-stop-violent-crime-before-it-happens/
- Identifying and Mitigating the Security Risks of Generative AI. Foundations and Trends® in Privacy and Security 6, 1 (2023), 1–52. https://doi.org/10.1561/3300000041 arXiv:2308.14840 [cs].
- Strong baselines for parameter efficient few-shot fine-tuning. arXiv preprint arXiv:2304.01917 (2023).
- Efficient Training of Language Models to Fill in the Middle. arXiv:2207.14255 [cs.CL]
- Introducing our Multimodal Models. https://www.adept.ai/blog/fuyu-8b
- Beijing Academy of Artificial Intelligence. 2023. Beijing AI Safety International Consensus. https://idais-beijing.baai.ac.cn/?lang=en. Accessed: 2023-04-25.
- Longformer: The Long-Document Transformer. arXiv:2004.05150 [cs.CL]
- A framework for the evaluation of code generation models. https://github.com/bigcode-project/bigcode-evaluation-harness.
- On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’21). Association for Computing Machinery, New York, NY, USA, 610–623. https://doi.org/10.1145/3442188.3445922
- Safe model-based reinforcement learning with stability guarantees. Advances in neural information processing systems 30 (2017).
- Towards language models that can see: Computer vision through the lens of natural language. arXiv preprint arXiv:2306.16410 (2023).
- Graph of thoughts: Solving elaborate problems with large language models. arXiv preprint arXiv:2308.09687 (2023).
- Uncertainty as a Form of Transparency: Measuring, Communicating, and Using Uncertainty. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society (AIES ’21). Association for Computing Machinery, New York, NY, USA, 401–413. https://doi.org/10.1145/3461702.3462571
- Patient and Consumer Safety Risks When Using Conversational Assistants for Medical Information: An Observational Study of Siri, Alexa, and Google Assistant. Journal of Medical Internet Research 20, 9 (Sept. 2018), e11510. https://doi.org/10.2196/11510 Company: Journal of Medical Internet Research Distributor: Journal of Medical Internet Research Institution: Journal of Medical Internet Research Label: Journal of Medical Internet Research Publisher: JMIR Publications Inc., Toronto, Canada.
- Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling. arXiv:2304.01373 [cs.CL]
- Jeffrey P. Bigham. 2023. How HCI Might Engage with the Easy Access to Statistical Likelihoods of Things. https://www.jeffreybigham.com/blog/2023/how-hci-might-engage-with-easy-access-to-unintuitive-statistical-likelihoods.html.
- Experience grounds language. arXiv preprint arXiv:2004.10151 (2020).
- Emergent autonomous scientific research capabilities of large language models. arXiv preprint arXiv:2304.05332 (2023).
- Autonomous chemical research with large language models. Nature 624, 7992 (12 2023), 570–578. https://doi.org/10.1038/s41586-023-06792-0
- On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258 (2021).
- Improving language models by retrieving from trillions of tokens. In International conference on machine learning. PMLR, 2206–2240.
- Petals: Collaborative Inference and Fine-tuning of Large Models. arXiv preprint arXiv:2209.01188 (2022). https://arxiv.org/abs/2209.01188
- Samuel R Bowman. 2023. Eight things to know about large language models. arXiv preprint arXiv:2304.00612 (2023).
- Measuring progress on scalable oversight for large language models. arXiv preprint arXiv:2211.03540 (2022).
- Embedding Large Language Models into Extended Reality: Opportunities and Challenges for Inclusion, Engagement, and Privacy. http://arxiv.org/abs/2402.03907 arXiv:2402.03907 [cs].
- JAX: composable transformations of Python+NumPy programs. http://github.com/google/jax
- Promptify: Text-to-Image Generation through Interactive Prompt Exploration with Large Language Models. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23). Association for Computing Machinery, New York, NY, USA, 1–14. https://doi.org/10.1145/3586183.3606725
- ChemCrow: Augmenting large-language models with chemistry tools. arXiv preprint arXiv:2304.05376 (2023).
- Learning to win by reading manuals in a monte-carlo framework. Journal of Artificial Intelligence Research 43 (2012), 661–704.
- Accurate, reliable and fast robustness evaluation. Advances in neural information processing systems 32 (2019).
- Selmer Bringsjord and David Ferrucci. 2003. Artificial intelligence and literary creativity: Inside the mind of Brutus, a storytelling machine. Routledge.
- Rt-2: Vision-language-action models transfer web knowledge to robotic control. arXiv preprint arXiv:2307.15818 (2023).
- Video generation models as world simulators. (2024). https://openai.com/research/video-generation-models-as-world-simulators
- Language models are few-shot learners. Advances in neural information processing systems 33 (2020), 1877–1901.
- Genie: Generative Interactive Environments. arXiv:2402.15391 [cs.LG]
- Improved prediction of protein-protein interactions using AlphaFold2. Nature communications 13, 1 (2022), 1265.
- Erik Brynjolfsson and Andrew McAfee. 2014. The Second Machine Age: Work, Progress, and Prosperity in a Time of Brilliant Technologies. W. W. Norton & Company.
- Joanna J Bryson and Alan Winfield. 2017. Standardizing ethical design for artificial intelligence and autonomous systems. Computer 50, 5 (2017), 116–119.
- Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712 (2023).
- Cameron Buckner and James Garson. 1997. Connectionism. (1997).
- Stephan Vladimir Bugaj and Ben Goertzel. 2007. Five ethical imperatives and their implications for human-AGI interaction. Dynamical Psychology (2007), 1–7.
- Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision. arXiv preprint arXiv:2312.09390 (2023).
- Consciousness in Artificial Intelligence: Insights from the Science of Consciousness. arXiv:2308.08708 [cs.AI]
- Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads. arXiv:2401.10774 [cs.LG]
- Large Language Models as Tool Makers. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=qV83K9d5WB
- Semantics derived automatically from language corpora contain human-like biases. Science 356, 6334 (April 2017), 183–186. https://doi.org/10.1126/science.aal4230 arXiv:1608.07187 [cs].
- Defending against alignment-breaking attacks via robustly aligned llm. arXiv preprint arXiv:2309.14348 (2023).
- Yang Trista Cao and Hal Daumé III. 2020. Toward Gender-Inclusive Coreference Resolution. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (Eds.). Association for Computational Linguistics, Online, 4568–4595. https://doi.org/10.18653/v1/2020.acl-main.418
- Converging on the divergent: The history (and future) of the international joint workshops in computational creativity. AI magazine 30, 3 (2009), 15–15.
- Graham Caron and Shashank Srivastava. 2022. Identifying and manipulating the personality traits of language models. arXiv preprint arXiv:2212.10276 (2022).
- Open problems and fundamental limitations of reinforcement learning from human feedback. arXiv preprint arXiv:2307.15217 (2023).
- Pew Research Center. 2017. The Future of Jobs and Jobs Training. https://www.pewresearch.org/internet/2017/05/03/the-future-of-jobs-and-jobs-training/.
- EvoPrompting: Language Models for Code-Level Neural Architecture Search. arXiv:2302.14838 [cs.NE]
- AdaBERT: Task-Adaptive BERT Compression with Differentiable Neural Architecture Search. arXiv:2001.04246 [cs.CL]
- X-llm: Bootstrapping advanced large language models by treating multi-modalities as foreign languages. arXiv preprint arXiv:2305.04160 (2023).
- Autoagents: A framework for automatic agent generation. arXiv preprint arXiv:2309.17288 (2023).
- Shikra: Unleashing Multimodal LLM’s Referential Dialogue Magic. arXiv preprint arXiv:2306.15195 (2023).
- Punica: Multi-Tenant LoRA Serving. arXiv:2310.18547 [cs.DC]
- FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance. arXiv:2305.05176 [cs.LG]
- Evaluating Large Language Models Trained on Code. (2021). arXiv:2107.03374 [cs.LG]
- TVM: An Automated End-to-End Optimizing Compiler for Deep Learning. arXiv:1802.04799 [cs.LG]
- Training Deep Nets with Sublinear Memory Cost. arXiv:1604.06174 [cs.LG]
- Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors in agents. arXiv preprint arXiv:2308.10848 (2023).
- Llava-interactive: An all-in-one demo for image chat, segmentation, generation and editing. arXiv preprint arXiv:2311.00571 (2023).
- Can large language models provide security & privacy advice? measuring the ability of llms to refute misconceptions. In Proceedings of the 39th Annual Computer Security Applications Conference. 366–378.
- LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models. arXiv:2309.12307 [cs.CL]
- Do models explain themselves? counterfactual simulatability of natural language explanations. arXiv preprint arXiv:2307.08678 (2023).
- Self-play fine-tuning converts weak language models to strong language models. arXiv preprint arXiv:2401.01335 (2024).
- Octavius: Mitigating Task Interference in MLLMs via MoE. arXiv preprint arXiv:2311.02684 (2023).
- CreativeConnect: Supporting Reference Recombination for Graphic Design Ideation with Generative AI. https://doi.org/10.48550/arXiv.2312.11949 arXiv:2312.11949 [cs].
- Jyoti Choudrie and Mohamad Selamat. 2006. The Consideration of Meta-Abilities in Tacit Knowledge Externalization and Organizational Learning. https://doi.org/10.1109/HICSS.2006.456
- PaLM: Scaling Language Modeling with Pathways. arXiv:2204.02311 [cs.CL]
- Patch-level Routing in Mixture-of-Experts is Provably Sample-efficient for Convolutional Neural Networks. arXiv preprint arXiv:2306.04073 (2023).
- Supervising strong learners by amplifying weak experts. arXiv preprint arXiv:1810.08575 (2018).
- Mobilevlm: A fast, reproducible and strong vision language assistant for mobile devices. arXiv preprint arXiv:2312.16886 (2023).
- Computational creativity: The final frontier?. In Ecai, Vol. 12. Montpelier, 21–26.
- Katherine Crowson. 2022. VQGAN-CLIP: Open Domain Image Generation and Editing with Natural Language Guidance. arXiv preprint arXiv:2204.08583 (2022).
- Holistic analysis of hallucination in gpt-4v (ision): Bias and interference challenges. arXiv preprint arXiv:2311.03287 (2023).
- Large Language Models for Compiler Optimization. arXiv:2309.07062 [cs.PL]
- Bennett Cyphers and Gennie Gebhart. 2019. Behind the One-Way Mirror: A Deep Dive Into the Technology of Corporate Surveillance. https://www.eff.org/wp/behind-the-one-way-mirror
- Cooperative AI: machines must learn to find common ground.
- Open problems in cooperative AI. arXiv preprint arXiv:2012.08630 (2020).
- InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning. NeurIPS (2023).
- GitHub Copilot AI pair programmer: Asset or Liability? arXiv:2206.15331 [cs.SE]
- Global optimization of quantum dynamics with AlphaZero deep exploration. npj Quantum Information 6, 1 (2020), 1–9.
- Tri Dao. 2023. FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. (2023).
- Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems 35 (2022), 16344–16359.
- Privacy in the Age of AI. Commun. ACM 66, 11 (Nov. 2023), 29–31. https://doi.org/10.1145/3625254
- Editing factual knowledge in language models. arXiv preprint arXiv:2104.08164 (2021).
- Mind2Web: Towards a Generalist Agent for the Web. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track. https://openreview.net/forum?id=kiYqbO3wqw
- Mind2web: Towards a generalist agent for the web. Advances in Neural Information Processing Systems 36 (2024).
- QLoRA: Efficient Finetuning of Quantized LLMs. arXiv:2305.14314 [cs.LG]
- Virginia Dignum. 2019. Responsible artificial intelligence: How to develop and use AI in a responsible way. Springer Nature.
- LongNet: Scaling Transformers to 1,000,000,000 Tokens. arXiv:2307.02486 [cs.CL]
- Enhancing chat language models by scaling high-quality instructional conversations. arXiv preprint arXiv:2305.14233 (2023).
- Documenting large webtext corpora: A case study on the colossal clean crawled corpus. arXiv preprint arXiv:2104.08758 (2021).
- Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents. arXiv preprint arXiv:2302.04754 (2023).
- ColD Fusion: Collaborative Descent for Distributed Multitask Finetuning. arXiv:2212.01378 [cs.LG]
- Towards Structured Sparsity in Transformers for Efficient Inference. In Workshop on Efficient Systems for Foundation Models @ ICML2023. https://openreview.net/forum?id=c4m0BkO4OL
- Raft: Reward ranked finetuning for generative foundation model alignment. arXiv preprint arXiv:2304.06767 (2023).
- Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378 (2023).
- Glam: Efficient scaling of language models with mixture-of-experts. In International Conference on Machine Learning. PMLR, 5547–5569.
- Improving Factuality and Reasoning in Language Models through Multiagent Debate. arXiv preprint arXiv:2305.14325 (2023).
- Generating Automatic Feedback on UI Mockups with Large Language Models. https://doi.org/10.1145/3613904.3642782 arXiv:2403.13139 [cs].
- Scalable Pre-training of Large Autoregressive Image Models. arXiv preprint arXiv:2401.08541 (2024).
- Douglas C. Engelbart. 1962. A conceptual framework for the augmentation of man’s intellect. Air Force Office of Scientific Research, AFOSR-3233, www.bootstrap.org/augdocs/friedewald030402/augmentinghumanintellect/ahi62index.html.
- Lessons from the amazon picking challenge: Four aspects of building robotic systems.. In Robotics: science and systems, Vol. 12.
- AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data. arXiv preprint arXiv:2003.06505 (2020).
- Human-Centered Loss Functions (HALOs). Technical Report. Contextual AI. https://github.com/ContextualAI/HALOs/blob/main/assets/report.pdf.
- Reasoning about knowledge. MIT press.
- FairScale authors. 2021. FairScale: A general purpose modular PyTorch library for high performance and large scale training. https://github.com/facebookresearch/fairscale.
- Reducing Transformer Depth on Demand with Structured Dropout. arXiv:1909.11556 [cs.LG]
- Muffin or Chihuahua? Challenging Large Vision-Language Models with Multipanel VQA. arXiv preprint arXiv:2401.15847 (2024).
- LLM Agents can Autonomously Hack Websites. https://doi.org/10.48550/arXiv.2402.06664 arXiv:2402.06664 [cs].
- Sparsity in transformers: A systematic literature review. Neurocomputing 582 (2024), 127468. https://doi.org/10.1016/j.neucom.2024.127468
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. arXiv:2101.03961 [cs.LG]
- Mmdialog: A large-scale multi-turn dialogue dataset towards multi-modal open-domain conversation. arXiv preprint arXiv:2211.05719 (2022).
- CoPrompt: Supporting Prompt Sharing and Referring in Collaborative Natural Language Programming. http://arxiv.org/abs/2310.09235 arXiv:2310.09235 [cs].
- LayoutGPT: Compositional Visual Planning and Generation with Large Language Models. arXiv:2305.15393 [cs.CV]
- Promptbreeder: Self-referential self-improvement via prompt evolution. arXiv preprint arXiv:2309.16797 (2023).
- Auto-Sklearn 2.0: Hands-free AutoML via Meta-Learning. (2020).
- Distributed constraint optimization problems and applications: A survey. Journal of Artificial Intelligence Research 61 (2018), 623–698.
- Principled Artificial Intelligence: Mapping Consensus in Ethical and Rights-Based Approaches to Principles for AI. https://doi.org/10.2139/ssrn.3518482
- Counterfactual multi-agent policy gradients. In Proceedings of the AAAI conference on artificial intelligence, Vol. 32.
- Martin Ford. 2015. Rise of the Robots: Technology and the Threat of a Jobless Future. Basic Books.
- World Economic Forum. 2020. The Future of Jobs Report 2020. https://www.weforum.org/reports/the-future-of-jobs-report-2020.
- Jonathan Frankle and Michael Carbin. 2019. The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks. arXiv:1803.03635 [cs.LG]
- InCoder: A Generative Model for Code Infilling and Synthesis. arXiv:2204.05999 [cs.SE]
- Hungry Hungry Hippos: Towards Language Modeling with State Space Models. arXiv:2212.14052 [cs.LG]
- Scene-LLM: Extending Language Model for 3D Visual Understanding and Reasoning. arXiv:2403.11401 [cs.CV]
- Text-guided 3D Human Generation from 2D Collections. arXiv:2305.14312 [cs.CV]
- Specializing Smaller Language Models towards Multi-Step Reasoning. arXiv preprint arXiv:2301.12726 (2023).
- Complexity-based prompting for multi-step reasoning. arXiv preprint arXiv:2210.00720 (2022).
- Yao Fu Jinjie Ni Zangwei Zheng Wangchunshu Zhou Fuzhao Xue, Zian Zheng and Yang You. 2023. OpenMoE: Open Mixture-of-Experts Language Models. https://github.com/XueFuzhao/OpenMoE.
- Iason Gabriel. 2020. Artificial intelligence, values, and alignment. Minds and Machines 30, 3 (2020), 411–437.
- A review on speech recognition technique. International Journal of Computer Applications 10, 3 (2010), 16–24.
- Krzysztof Z. Gajos and Lena Mamykina. 2022. Do People Engage Cognitively with AI? Impact of AI Assistance on Incidental Learning. In 27th International Conference on Intelligent User Interfaces (IUI ’22). Association for Computing Machinery, New York, NY, USA, 794–806. https://doi.org/10.1145/3490099.3511138
- MegaBlocks: Efficient Sparse Training with Mixture-of-Experts. arXiv:2211.15841 [cs.LG]
- Assistgui: Task-oriented desktop graphical user interface automation. arXiv preprint arXiv:2312.13108 (2023).
- Llama-adapter v2: Parameter-efficient visual instruction model. arXiv preprint arXiv:2304.15010 (2023).
- Making pre-trained language models better few-shot learners. arXiv preprint arXiv:2012.15723 (2020).
- Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs. arXiv:2310.01801 [cs.CL]
- Planting a seed of vision in large language model. arXiv preprint arXiv:2307.08041 (2023).
- OpenAGI: When LLM Meets Domain Experts. In Advances in Neural Information Processing Systems (NeurIPS) (2023).
- Daniel George and EA Huerta. 2018. Deep learning for real-time gravitational wave detection and parameter estimation: Results with Advanced LIGO data. Physics Letters B 778 (2018), 64–70.
- Supporting Sensemaking of Large Language Model Outputs at Scale. https://doi.org/10.48550/arXiv.2401.13726 arXiv:2401.13726 [cs].
- Navigating to objects in the real world. Science Robotics 8, 79 (2023), eadf6991. https://doi.org/10.1126/scirobotics.adf6991 arXiv:https://www.science.org/doi/pdf/10.1126/scirobotics.adf6991
- Amirata Ghorbani and James Zou. 2019. Data Shapley: Equitable Valuation of Data for Machine Learning. In Proceedings of the 36th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 97), Kamalika Chaudhuri and Ruslan Salakhutdinov (Eds.). PMLR, 2242–2251. https://proceedings.mlr.press/v97/ghorbani19c.html
- ChatGPT outperforms crowd workers for text-annotation tasks. Proceedings of the National Academy of Sciences 120, 30 (2023), e2305016120.
- Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 15180–15190.
- Improving alignment of dialogue agents via targeted human judgements. arXiv preprint arXiv:2209.14375 (2022).
- Aligning language models with preferences through f-divergence minimization. arXiv preprint arXiv:2302.08215 (2023).
- Multimodal-gpt: A vision and language model for dialogue with humans. arXiv preprint arXiv:2305.04790 (2023).
- Generative adversarial networks. Commun. ACM 63, 11 (2020), 139–144.
- Critic: Large language models can self-correct with tool-interactive critiquing. arXiv preprint arXiv:2305.11738 (2023).
- Alex Graves. 2013. Generating sequences with recurrent neural networks. arXiv preprint arXiv:1308.0850 (2013).
- Alex Graves and Alex Graves. 2012. Long short-term memory. Supervised sequence labelling with recurrent neural networks (2012), 37–45.
- OLMo: Accelerating the Science of Language Models. arXiv:2402.00838 [cs.CL]
- Designing LLM Chains by Adapting Techniques from Crowdsourcing Workflows. https://doi.org/10.48550/arXiv.2312.11681 arXiv:2312.11681 [cs].
- Albert Gu and Tri Dao. 2023. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv:2312.00752 [cs.LG]
- Efficiently Modeling Long Sequences with Structured State Spaces. arXiv:2111.00396 [cs.LG]
- On the Parameterization and Initialization of Diagonal State Space Models. arXiv:2206.11893 [cs.LG]
- Knowledge Distillation of Large Language Models. arXiv:2306.08543 [cs.CL]
- Textbooks Are All You Need. arXiv:2306.11644 [cs.CL]
- A comprehensive evaluation framework for deep model robustness. Pattern Recognition 137 (2023), 109308.
- Vision Superalignment: Weak-to-Strong Generalization for Vision Foundation Models. arXiv preprint arXiv:2402.03749 (2024).
- General-Purpose Embodied AI Agent via Reinforcement Learning with Internet-Scale Knowledge. arXiv preprint arXiv:2212.09710 (2022).
- Diagonal State Spaces are as Effective as Structured State Spaces. arXiv:2203.14343 [cs.LG]
- Cooperative multi-agent control using deep reinforcement learning. In Autonomous Agents and Multiagent Systems: AAMAS 2017 Workshops, Best Papers, São Paulo, Brazil, May 8-12, 2017, Revised Selected Papers 16. Springer, 66–83.
- Retrieval augmented language model pre-training. In International conference on machine learning. PMLR, 3929–3938.
- Cooperative inverse reinforcement learning. In Advances in Neural Information Processing Systems, Vol. 29.
- Mastering Diverse Domains through World Models. arXiv preprint arXiv:2301.04104 (2023).
- OneLLM: One Framework to Align All Modalities with Language. arXiv preprint arXiv:2312.03700 (2023).
- Imagebind-llm: Multi-modality instruction tuning. arXiv preprint arXiv:2309.03905 (2023).
- Proof Artifact Co-Training for Theorem Proving with Language Models. In International Conference on Learning Representations. https://openreview.net/forum?id=rpxJc9j04U
- EIE: Efficient Inference Engine on Compressed Deep Neural Network. arXiv:1602.01528 [cs.CV]
- Grounding language to entities and dynamics for generalization in reinforcement learning. In International Conference on Machine Learning. PMLR, 4051–4062.
- Reasoning with language model is planning with world model. arXiv preprint arXiv:2305.14992 (2023).
- Stevan Harnad. 1990. The symbol grounding problem. Physica D: Nonlinear Phenomena 42, 1-3 (1990), 335–346.
- Incorporating Visual Experts to Resolve the Information Loss in Multimodal Large Language Models. arXiv preprint arXiv:2401.03105 (2024).
- Towards the systematic reporting of the energy and carbon footprints of machine learning. Journal of Machine Learning Research 21, 248 (2020), 1–43.
- Measuring Coding Challenge Competence With APPS. arXiv:2105.09938 [cs.SE]
- Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300 (2020).
- Dan Hendrycks and Mantas Mazeika. 2022. X-risk analysis for ai research. arXiv preprint arXiv:2206.05862 (2022).
- Distilling the Knowledge in a Neural Network. arXiv:1503.02531 [stat.ML]
- Denoising diffusion probabilistic models. Advances in neural information processing systems 33 (2020), 6840–6851.
- Jonathan Ho and Tim Salimans. 2022. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022).
- Video Diffusion Models. arXiv:2204.03458 [cs.CV]
- Hal Hodson. 2016. Revealed: Google AI has access to huge haul of NHS patient data. https://www.newscientist.com/article/2086454-revealed-google-ai-has-access-to-huge-haul-of-nhs-patient-data/
- Training Compute-Optimal Large Language Models. arXiv:2203.15556 [cs.CL]
- DeepSpeed-FastGen: High-throughput Text Generation for LLMs via MII and DeepSpeed-Inference. arXiv:2401.08671 [cs.PF]
- FlashDecoding++: Faster Large Language Model Inference on GPUs. arXiv:2311.01282 [cs.LG]
- Metagpt: Meta programming for multi-agent collaborative framework. arXiv preprint arXiv:2308.00352 (2023).
- ScholarBERT: bigger is not always better. arXiv preprint arXiv:2205.11342 (2022).
- Eric Horvitz. 1999. Principles of mixed-initiative user interfaces. In Proceedings of the SIGCHI conference on Human Factors in Computing Systems (CHI ’99). Association for Computing Machinery, New York, NY, USA, 159–166. https://doi.org/10.1145/302979.303030
- Parameter-efficient transfer learning for NLP. In International conference on machine learning. PMLR, 2790–2799.
- Dirk Hovy and Shannon L. Spruit. 2016. The Social Impact of Natural Language Processing. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Katrin Erk and Noah A. Smith (Eds.). Association for Computational Linguistics, Berlin, Germany, 591–598. https://doi.org/10.18653/v1/P16-2096
- Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. arXiv preprint arXiv:2305.02301 (2023).
- Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685 (2021).
- AgentsCoDriver: Large Language Model Empowered Collaborative Driving with Lifelong Learning. arXiv:2404.06345 [cs.AI]
- SceneCraft: An LLM Agent for Synthesizing 3D Scene as Blender Code. arXiv:2403.01248 [cs.CV]
- Zhiting Hu and Tianmin Shu. 2023. Language Models, Agent Models, and World Models: The LAW for Machine Reasoning and Planning. arXiv:2312.05230 [cs.AI]
- LoraHub: Efficient Cross-Task Generalization via Dynamic LoRA Composition. arXiv:2307.13269 [cs.CL]
- Jie Huang and Kevin Chen-Chuan Chang. 2022. Towards reasoning in large language models: A survey. arXiv preprint arXiv:2212.10403 (2022).
- ChatGPT an ENFJ, Bard an ISTJ: Empirical Study on Personalities of Large Language Models. arXiv preprint arXiv:2305.19926 (2023).
- Audiogpt: Understanding and generating speech, music, sound, and talking head. arXiv preprint arXiv:2304.12995 (2023).
- Instruct2Act: Mapping Multi-modality Instructions to Robotic Actions with Large Language Model. arXiv preprint arXiv:2305.11176 (2023).
- Voxposer: Composable 3d value maps for robotic manipulation with language models. arXiv preprint arXiv:2307.05973 (2023).
- Inner monologue: Embodied reasoning through planning with language models. arXiv preprint arXiv:2207.05608 (2022).
- In-context Learning Distillation: Transferring Few-shot Learning Ability of Pre-trained Language Models. arXiv preprint arXiv:2212.10670 (2022).
- GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism. arXiv:1811.06965 [cs.CV]
- Evan Hubinger. 2023. AI safety via market making. https://www.lesswrong.com/posts/YWwzccGbcHMJMpT45/ai-safety-via-market-making..
- GenAssist: Making Image Generation Accessible. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23). Association for Computing Machinery, New York, NY, USA, 1–17. https://doi.org/10.1145/3586183.3606735
- Automated Machine Learning: Methods, Systems, Challenges (1st ed.). Springer Publishing Company, Incorporated.
- Tutel: Adaptive Mixture-of-Experts at Scale. arXiv:2206.03382 [cs.DC]
- FedPara: Low-Rank Hadamard Product for Communication-Efficient Federated Learning. arXiv:2108.06098 [cs.LG]
- Editing Models with Task Arithmetic. arXiv:2212.04089 [cs.LG]
- MathPrompter: Mathematical Reasoning using Large Language Models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 5: Industry Track). 37–42.
- McKinsey Global Institute. 2017. Jobs lost, jobs gained: Workforce transitions in a time of automation. https://www.mckinsey.com/featured-insights/future-of-work/jobs-lost-jobs-gained-what-the-future-of-work-will-mean-for-jobs-skills-and-wages.
- Brookings Institution. 2021. How to combat America’s digital divide. https://www.brookings.edu/research/how-to-combat-americas-digital-divide/.
- Geoffrey Irving and Amanda Askell. 2019. AI safety needs social scientists. Distill 4, 2 (2019), e14.
- AI safety via debate. arXiv preprint arXiv:1805.00899 (2018).
- Brett W Israelsen. 2019. Algorithmic assurances and self-assessment of competency boundaries in autonomous systems. Ph. D. Dissertation. University of Colorado at Boulder.
- Frustration as a way toward autonomy and self-improvement in robotic navigation. In 2013 IEEE Third Joint International Conference on Development and Learning and Epigenetic Robotics (ICDL). IEEE, 1–7.
- From self-assessment to frustration, a small step toward autonomy in robotic navigation. Frontiers in neurorobotics 7 (2013), 16.
- Phi-2: The surprising power of small language models. Microsoft Research Blog (2023).
- Neural amortized inference for nested multi-agent reasoning. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 530–537.
- Aligner: Achieving efficient alignment through weak-to-strong correction. arXiv preprint arXiv:2402.02416 (2024).
- Ai alignment: A comprehensive survey. arXiv preprint arXiv:2310.19852 (2023).
- Survey of hallucination in natural language generation. Comput. Surveys 55, 12 (2023), 1–38.
- Towards Efficient Data Valuation Based on the Shapley Value. In Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics (Proceedings of Machine Learning Research, Vol. 89), Kamalika Chaudhuri and Masashi Sugiyama (Eds.). PMLR, 1167–1176. https://proceedings.mlr.press/v89/jia19a.html
- Beyond Data and Model Parallelism for Deep Neural Networks. arXiv:1807.05358 [cs.DC]
- Mistral 7B. arXiv:2310.06825 [cs.CL]
- MotionGPT: Human Motion as a Foreign Language. arXiv preprint arXiv:2306.14795 (2023).
- Evaluating and Inducing Personality in Pre-trained Language Models. (2022).
- Graphologue: Exploring Large Language Model Responses with Interactive Diagrams. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23). Association for Computing Machinery, New York, NY, USA, 1–20. https://doi.org/10.1145/3586183.3606737
- Lion: Adversarial Distillation of Closed-Source Large Language Model. arXiv preprint arXiv:2305.12870 (2023).
- Vima: General robot manipulation with multimodal prompts. arXiv (2022).
- HexGen: Generative Inference of Foundation Model over Heterogeneous Decentralized Environment. arXiv:2311.11514 [cs.DC]
- SWE-bench: Can Language Models Resolve Real-World GitHub Issues? arXiv:2310.06770 [cs.CL]
- Mmtom-qa: Multimodal theory of mind question answering. arXiv preprint arXiv:2401.08743 (2024).
- The Cultural Psychology of Large Language Models: Is ChatGPT a Holistic or Analytic Thinker? arXiv preprint arXiv:2308.14242 (2023).
- S3: Increasing GPU Utilization during Generative Inference for Higher Throughput. arXiv:2306.06000 [cs.AR]
- The global landscape of AI ethics guidelines. Nature Machine Intelligence 1, 9 (Sept. 2019), 389–399. https://doi.org/10.1038/s42256-019-0088-2 Publisher: Nature Publishing Group.
- TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. arXiv:1705.03551 [cs.CL]
- TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings. arXiv:2304.01433 [cs.AR]
- Highly accurate protein structure prediction with AlphaFold. Nature 596, 7873 (2021), 583–589.
- Maieutic prompting: Logically consistent reasoning with recursive explanations. arXiv preprint arXiv:2205.11822 (2022).
- Scaling Laws for Neural Language Models. arXiv preprint arXiv:2001.08361 (2020).
- OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web. arXiv preprint arXiv:2402.17553 (2024).
- Data Debugging with Shapley Importance over End-to-End Machine Learning Pipelines. arXiv:2204.11131 [cs.LG]
- Dense passage retrieval for open-domain question answering. arXiv preprint arXiv:2004.04906 (2020).
- Understanding Contestability on the Margins: Implications for the Design of Algorithmic Decision-making in Public Services. (2024).
- Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention. arXiv:2006.16236 [cs.LG]
- CodeAid: Evaluating a Classroom Deployment of an LLM-based Programming Assistant that Balances Student and Educator Needs. https://doi.org/10.1145/3613904.3642773 arXiv:2401.11314 [cs].
- Alignment of Language Agents. https://doi.org/10.48550/arXiv.2103.14659 arXiv:2103.14659 [cs].
- Ben Kenward and Thomas Sinclair. 2021. Machine morality, moral progress, and the looming environmental disaster.
- DreamIX: DreamFusion via Iterative Spatiotemporal Mixing. arXiv preprint arXiv:2212.04508 (2022).
- Demonstrate-Search-Predict: Composing Retrieval and Language Models for Knowledge-Intensive NLP. arXiv preprint arXiv:2212.14024 (2022).
- DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines. arXiv preprint arXiv:2310.03714 (2023).
- DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset. arXiv:2403.12945 [cs.RO]
- Decomposed prompting: A modular approach for solving complex tasks. arXiv preprint arXiv:2210.02406 (2022).
- Aligning Large Language Models through Synthetic Feedback. arXiv preprint arXiv:2305.13735 (2023).
- EvalLM: Interactive Evaluation of Large Language Model Prompts on User-Defined Criteria. https://doi.org/10.1145/3613904.3642216 arXiv:2309.13633 [cs].
- Diederik P Kingma and Max Welling. 2013. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013).
- Generating images with multimodal language models. arXiv preprint arXiv:2305.17216 (2023).
- Grounding language models to images for multimodal inputs and outputs. In International Conference on Machine Learning. PMLR, 17283–17300.
- Large language models are zero-shot reasoners. Advances in neural information processing systems 35 (2022), 22199–22213.
- Bart Kosko. 1992. Neural networks and fuzzy systems: a dynamical systems approach to machine intelligence. Prentice-Hall, Inc.
- Automated Scientific Discovery: From Equation Discovery to Autonomous Discovery Systems. arXiv preprint arXiv:2305.02251 (2023).
- Beyond Distillation: Task-level Mixture-of-Experts for Efficient Inference. arXiv:2110.03742 [cs.CL]
- ZipLM: Inference-Aware Structured Pruning of Language Models. arXiv:2302.04089 [cs.LG]
- Natural Questions: A Benchmark for Question Answering Research. Transactions of the Association for Computational Linguistics 7 (2019), 452–466. https://doi.org/10.1162/tacl_a_00276
- Unspeaking on Facebook? Testing network effects on self-censorship of political expressions in social network sites. Quality & Quantity 49, 4 (July 2015), 1417–1435. https://doi.org/10.1007/s11135-014-0078-8
- Reward design with language models. arXiv preprint arXiv:2303.00001 (2023).
- Efficient Memory Management for Large Language Model Serving with PagedAttention. arXiv:2309.06180 [cs.LG]
- DS-1000: A Natural and Reliable Benchmark for Data Science Code Generation. arXiv:2211.11501 [cs.SE]
- Brenden M Lake and Marco Baroni. 2023. Human-like systematic generalization through a meta-learning neural network. Nature (2023), 1–7.
- Lambda. 2023. OpenAI’s GPT-3 Language Model: A Technical Overview. https://lambdalabs.com/blog/demystifying-gpt-3
- Obelics: An open web-scale filtered dataset of interleaved image-text documents. Advances in Neural Information Processing Systems 36 (2024).
- Nam Le. 2019. Evolving Self-supervised Neural Networks Autonomous Intelligence from Evolved Self-teaching. arXiv:1906.08865 [cs.NE]
- Yann LeCun. 2022. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27. Open Review 62, 1 (2022).
- Rlaif: Scaling reinforcement learning from human feedback with ai feedback. arXiv preprint arXiv:2309.00267 (2023).
- Deepfakes, Phrenology, Surveillance, and More! A Taxonomy of AI Privacy Risks. https://doi.org/10.48550/arXiv.2310.07879 arXiv:2310.07879 [cs].
- A Design Space for Intelligent and Interactive Writing Assistants. https://doi.org/10.1145/3613904.3642697 arXiv:2403.14117 [cs].
- CoAuthor: Designing a Human-AI Collaborative Writing Dataset for Exploring Language Model Capabilities. In CHI Conference on Human Factors in Computing Systems. 1–19. https://doi.org/10.1145/3491102.3502030 arXiv:2201.06796 [cs].
- Scalable agent alignment via reward modeling: a research direction. arXiv preprint arXiv:1811.07871 (2018).
- HILL: A Hallucination Identifier for Large Language Models. http://arxiv.org/abs/2403.06710 arXiv:2403.06710 [cs].
- The Power of Scale for Parameter-Efficient Prompt Tuning. arXiv:2104.08691 [cs.CL]
- Fast Inference from Transformers via Speculative Decoding. arXiv:2211.17192 [cs.LG]
- Sam Levin. 2017. New AI can guess whether you’re gay or straight from a photograph. The Guardian (Sept. 2017). https://www.theguardian.com/technology/2017/sep/07/new-artificial-intelligence-can-tell-whether-youre-gay-or-straight-from-a-photograph
- Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems 33 (2020), 9459–9474.
- Solving quantitative reasoning problems with language models. arXiv preprint arXiv:2206.14858 (2022).
- OtterHD: A High-Resolution Multi-modality Model. arXiv preprint arXiv:2311.04219 (2023).
- Otter: A multi-modal model with in-context instruction tuning. arXiv preprint arXiv:2305.03726 (2023).
- BEHAVIOR-1K: A Human-Centered, Embodied AI Benchmark with 1,000 Everyday Activities and Realistic Simulation. arXiv:2403.09227 [cs.RO]
- Camel: Communicative agents for" mind" exploration of large scale language model society. arXiv preprint arXiv:2303.17760 (2023).
- Ethics of large language models in medicine and medical research. The Lancet Digital Health 5, 6 (2023), e333–e335.
- Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls. Advances in Neural Information Processing Systems 36 (2024).
- Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. ICML (2023).
- OmniActions: Predicting Digital Actions in Response to Real-World Multimodal Sensory Inputs with LLMs. (2024).
- Videochat: Chat-centric video understanding. arXiv preprint arXiv:2305.06355 (2023).
- Silkie: Preference distillation for large visual language models. arXiv preprint arXiv:2312.10665 (2023).
- Symbolic chain-of-thought distillation: Small models can also" think" step-by-step. arXiv preprint arXiv:2306.14050 (2023).
- DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models. arXiv:2402.19481 [cs.CV]
- Reflection-tuning: Data recycling improves llm instruction-tuning. arXiv preprint arXiv:2310.11716 (2023).
- StarCoder: may the source be with you! arXiv:2305.06161 [cs.CL]
- Explanations from large language models make small reasoners better. arXiv preprint arXiv:2210.06726 (2022).
- Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. arXiv preprint arXiv:2101.00190 (2021).
- Textbooks are all you need ii: phi-1.5 technical report. arXiv preprint arXiv:2309.05463 (2023).
- Competition-level code generation with AlphaCode. Science 378, 6624 (Dec. 2022), 1092–1097. https://doi.org/10.1126/science.abq1158
- Evaluating object hallucination in large vision-language models. arXiv preprint arXiv:2305.10355 (2023).
- Guiding large language models via directional stimulus prompting. Advances in Neural Information Processing Systems 36 (2024).
- LEGO: Language Enhanced Multi-modal Grounding Model. arXiv preprint arXiv:2401.06071 (2024).
- Holistic Evaluation of Language Models. arXiv:2211.09110 [cs.CL]
- Q. Vera Liao and Jennifer Wortman Vaughan. 2023. AI Transparency in the Age of LLMs: A Human-Centered Research Roadmap. https://doi.org/10.48550/arXiv.2306.01941 arXiv:2306.01941 [cs].
- Jamba: A Hybrid Transformer-Mamba Language Model. arXiv:2403.19887 [cs.CL]
- Let’s Verify Step by Step. arXiv preprint arXiv:2305.20050 (2023).
- Infinite-LLM: Efficient LLM Service for Long Context with DistAttention and Distributed KVCache. arXiv:2401.02669 [cs.DC]
- The unlocking spell on base llms: Rethinking alignment via in-context learning. arXiv preprint arXiv:2312.01552 (2023).
- AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration. arXiv:2306.00978 [cs.CL]
- VILA: On Pre-training for Visual Language Models. arXiv:2312.07533 [cs.CV]
- On-Device Training Under 256KB Memory. arXiv:2206.15472 [cs.CV]
- TruthfulQA: Measuring How Models Mimic Human Falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (Eds.). Association for Computational Linguistics, Dublin, Ireland, 3214–3252. https://doi.org/10.18653/v1/2022.acl-long.229
- Rambler: Supporting Writing With Speech via LLM-Assisted Gist Manipulation. https://doi.org/10.1145/3613904.3642217 arXiv:2401.10838 [cs].
- QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving. arXiv:2405.04532 [cs.CL]
- Language models of protein sequences at the scale of evolution enable accurate structure prediction. bioRxiv (2022). https://doi.org/10.1101/2022.07.20.500902 arXiv:https://www.biorxiv.org/content/early/2022/07/21/2022.07.20.500902.full.pdf
- SPHINX: The Joint Mixing of Weights, Tasks, and Visual Embeddings for Multi-modal Large Language Models. ArXiv abs/2311.07575 (2023). https://api.semanticscholar.org/CorpusID:265150267
- We’re Afraid Language Models Aren’t Modeling Ambiguity. arXiv preprint arXiv:2304.14399 (2023).
- Llm+ p: Empowering large language models with optimal planning proficiency. arXiv preprint arXiv:2304.11477 (2023).
- Visual instruction tuning. arXiv preprint arXiv:2304.08485 (2023).
- Chain of hindsight aligns language models with feedback. arXiv preprint arXiv:2302.02676 3 (2023).
- Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning. arXiv:2205.05638 [cs.LG]
- World Model on Million-Length Video And Language With RingAttention. arXiv:2402.08268 [cs.LG]
- Ring Attention with Blockwise Transformers for Near-Infinite Context. arXiv:2310.01889 [cs.CL]
- CLIP-Layout: Style-Consistent Indoor Scene Synthesis with Semantic Furniture Embedding. arXiv:2303.03565 [cs.CV]
- Second thoughts are best: Learning to re-align with human values from text edits. Advances in Neural Information Processing Systems 35 (2022), 181–196.
- Best Practices and Lessons Learned on Synthetic Data for Language Models. arXiv preprint arXiv:2404.07503 (2024).
- Aligning generative language models with human values. In Findings of the Association for Computational Linguistics: NAACL 2022. 241–252.
- EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention. arXiv:2305.07027 [cs.CV]
- AgentBench: Evaluating LLMs as Agents. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=zAdUB0aCTQ
- CacheGen: Fast Context Loading for Language Model Applications. arXiv:2310.07240 [cs.NI]
- Scissorhands: Exploiting the Persistence of Importance Hypothesis for LLM KV Cache Compression at Test Time. arXiv:2305.17118 [cs.LG]
- Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time. arXiv:2310.17157 [cs.LG]
- Dynamic llm-agent network: An llm-agent collaboration framework with agent team optimization. arXiv preprint arXiv:2310.02170 (2023).
- Katherine Anne Long. 2021. Amazon and Microsoft team up to defend against facial recognition lawsuits. https://www.seattletimes.com/business/technology/facial-recognition-lawsuits-against-amazon-and-microsoft-can-proceed-judge-rules/
- The flan collection: Designing data and methods for effective instruction tuning. In International Conference on Machine Learning. PMLR, 22631–22648.
- Dengsheng Lu and Qihao Weng. 2007. A survey of image classification methods and techniques for improving classification performance. International journal of Remote sensing 28, 5 (2007), 823–870.
- Routing to the Expert: Efficient Reward-guided Ensemble of Large Language Models. arXiv:2311.08692 [cs.CL]
- Cheap and quick: Efficient vision-language instruction tuning for large language models. arXiv preprint arXiv:2305.15023 (2023).
- BioGPT: generative pre-trained transformer for biomedical text generation and mining. Briefings in bioinformatics 23, 6 (2022), bbac409.
- Macaw-LLM: Multi-Modal Language Modeling with Image, Audio, Video, and Text Integration. arXiv preprint arXiv:2306.09093 (2023).
- Towards Faithful Model Explanation in NLP: A Survey. https://doi.org/10.48550/arXiv.2209.11326 arXiv:2209.11326 [cs].
- Large language models play starcraft ii: Benchmarks and a chain of summarization approach. arXiv preprint arXiv:2312.11865 (2023).
- Eureka: Human-Level Reward Design via Coding Large Language Models. arXiv:2310.12931 [cs.RO]
- Self-refine: Iterative refinement with self-feedback. Advances in Neural Information Processing Systems 36 (2024).
- PriorBand: Practical Hyperparameter Optimization in the Age of Deep Learning. arXiv:2306.12370 [cs.LG]
- GPT-Driver: Learning to Drive with GPT. arXiv:2310.01415 [cs.CV]
- A Language Agent for Autonomous Driving. arXiv:2311.10813 [cs.CV]
- Andres Marzal and Enrique Vidal. 1993. Computation of normalized edit distance and applications. IEEE transactions on pattern analysis and machine intelligence 15, 9 (1993), 926–932.
- Molecular Optimization using Language Models. arXiv preprint arXiv:2210.00299 (2022).
- Kris McGuffie and Alex Newhouse. 2020. The Radicalization Risks of GPT-3 and Advanced Neural Language Models. https://doi.org/10.48550/arXiv.2009.06807 arXiv:2009.06807 [cs].
- The inadequacy of reinforcement learning from human feedback-radicalizing large language models via semantic vulnerabilities. IEEE Transactions on Cognitive and Developmental Systems (2024).
- David A Medler. 1998. A brief history of connectionism. Neural computing surveys 1 (1998), 18–72.
- AIOS: LLM Agent Operating System. arXiv:2403.16971 [cs.OS]
- Bahar Memarian and Tenzin Doleck. 2023. Fairness, Accountability, Transparency, and Ethics (FATE) in Artificial Intelligence (AI), and higher education: A systematic review. Computers and Education: Artificial Intelligence (2023), 100152.
- Sdedit: Guided image synthesis and editing with stochastic differential equations. arXiv preprint arXiv:2108.01073 (2021).
- PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models. arXiv preprint arXiv:2404.02948 (2024).
- GAIA: a benchmark for General AI Assistants. arXiv:2311.12983 [cs.CL]
- Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems. arXiv:2312.15234 [cs.LG]
- SpecInfer: Accelerating Generative Large Language Model Serving with Tree-based Speculative Inference and Verification. arXiv:2305.09781 [cs.CL]
- Dan Milmo. 2021. Amazon asks Ring owners to respect privacy after court rules usage broke law. The Guardian (Oct. 2021). https://www.theguardian.com/uk-news/2021/oct/14/amazon-asks-ring-owners-to-respect-privacy-after-court-rules-usage-broke-law
- Smartphone-Based Conversational Agents and Responses to Questions About Mental Health, Interpersonal Violence, and Physical Health. JAMA Internal Medicine 176, 5 (May 2016), 619. https://doi.org/10.1001/jamainternmed.2016.0400
- Fast model editing at scale. arXiv preprint arXiv:2110.11309 (2021).
- Model Cards for Model Reporting. In Proceedings of the Conference on Fairness, Accountability, and Transparency (FAT* ’19). Association for Computing Machinery, New York, NY, USA, 220–229. https://doi.org/10.1145/3287560.3287596
- MLC team. 2023. MLC-LLM. https://github.com/mlc-ai/mlc-llm
- Amirkeivan Mohtashami and Martin Jaggi. 2023. Landmark Attention: Random-Access Infinite Context Length for Transformers. arXiv:2305.16300 [cs.CL]
- Levels of AGI: Operationalizing Progress on the Path to AGI. arXiv:2311.02462 [cs.AI]
- AI-assisted Code Authoring at Scale: Fine-tuning, deploying, and mixed methods evaluation. arXiv:2305.12050 [cs.SE]
- Past, present, and future of user interface software tools. ACM Transactions on Computer-Human Interaction 7, 1 (2000), 3–28. https://doi.org/10.1145/344949.344959
- Meenakshi Nadimpalli. 2017. Artificial intelligence risks and benefits. International Journal of Innovative Research in Science, Engineering and Technology 6, 6 (2017).
- LLMatic: Neural Architecture Search via Large Language Models and Quality Diversity Optimization. arXiv:2306.01102 [cs.NE]
- LLMs for Science: Usage for Code Generation and Data Analysis. arXiv preprint arXiv:2311.16733 (2023).
- Evaluating the Robustness to Instructions of Large Language Models. arXiv preprint arXiv:2308.14306 (2023).
- Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741 (2021).
- Sergey I Nikolenko. 2021. Synthetic data for deep learning. Vol. 174. Springer.
- ScreenAgent: A Vision Language Model-driven Computer Control Agent. arXiv preprint arXiv:2402.07945 (2024).
- NVIDIA. 2023a. FasterTransformer. https://github.com/NVIDIA/FasterTransformer.
- NVIDIA. 2023b. TensorRT-LLM: A TensorRT Toolbox for Optimized Large Language Model Inference. https://github.com/NVIDIA/TensorRT-LLM.
- Show your work: Scratchpads for intermediate computation with language models. arXiv preprint arXiv:2112.00114 (2021).
- I Lead, You Help but Only with Enough Details: Understanding User Experience of Co-Creation with Artificial Intelligence. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems (CHI ’18). Association for Computing Machinery, New York, NY, USA, 1–13. https://doi.org/10.1145/3173574.3174223
- OpenAI. 2018. Charter. https://www.openai.com/charter/.
- OpenAI. 2023a. GPT-4 Technical Report. Technical Report. OpenAI.
- OpenAI. 2023b. GPT-4v(ision) Technical Work and Authors. Technical Report. OpenAI. https://cdn.openai.com/contributions/gpt-4v.pdf
- OpenAI. 2024. Hello GPT-4o. https://openai.com/index/hello-gpt-4o/
- Training language models to follow instructions with human feedback. Advances in neural information processing systems 35 (2022), 27730–27744.
- Generative agents: Interactive simulacra of human behavior. arXiv preprint arXiv:2304.03442 (2023).
- Kaushikkumar Patel. 2024. Ethical reflections on data-centric AI: balancing benefits and risks. International Journal of Artificial Intelligence Research and Development 2, 1 (2024), 1–17.
- Gorilla: Large language model connected with massive apis. arXiv preprint arXiv:2305.15334 (2023).
- William Peebles and Saining Xie. 2023. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 4195–4205.
- Rwkv: Reinventing rnns for the transformer era. arXiv preprint arXiv:2305.13048 (2023).
- Eagle and Finch: RWKV with Matrix-Valued States and Dynamic Recurrence. arXiv:2404.05892 [cs.CL]
- Instruction Tuning with GPT-4. arXiv:2304.03277 [cs.CL]
- Hyena Hierarchy: Towards Larger Convolutional Language Models. arXiv:2302.10866 [cs.LG]
- Mechanistic Design and Scaling of Hybrid Architectures. arXiv:2403.17844 [cs.LG]
- Stanislas Polu and Ilya Sutskever. 2022. Formal mathematics statement curriculum learning. arXiv preprint arXiv:2202.01344 (2022).
- Efficiently Scaling Transformer Inference. arXiv:2211.05102 [cs.LG]
- The Kaldi speech recognition toolkit. In IEEE 2011 workshop on automatic speech recognition and understanding. IEEE Signal Processing Society.
- Predibase. 2023. Multi-LoRA inference server that scales to 1000s of fine-tuned LLMs. https://github.com/predibase/lorax.
- A review of nuclear batteries. Progress in Nuclear Energy 75 (2014), 117–148. https://doi.org/10.1016/j.pnucene.2014.04.007
- David Premack and Guy Woodruff. 1978. Does the chimpanzee have a theory of mind? Behavioral and brain sciences 1, 4 (1978), 515–526.
- Watch-and-help: A challenge for social perception and human-ai collaboration. arXiv preprint arXiv:2010.09890 (2020).
- Is Next Token Prediction Sufficient for GPT? Exploration on Code Logic Comprehension. arXiv preprint arXiv:2404.08885 (2024).
- Visual adversarial examples jailbreak aligned large language models. In The Second Workshop on New Frontiers in Adversarial Machine Learning, Vol. 1.
- Communicative agents for software development. arXiv preprint arXiv:2307.07924 (2023).
- CREATOR: Tool Creation for Disentangling Abstract and Concrete Reasoning of Large Language Models. In Findings of the Association for Computational Linguistics: EMNLP 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 6922–6939. https://doi.org/10.18653/v1/2023.findings-emnlp.462
- Creator: Disentangling abstract and concrete reasonings of large language models through tool creation. arXiv preprint arXiv:2305.14318 (2023).
- Investigate-Consolidate-Exploit: A General Strategy for Inter-Task Agent Self-Evolution. arXiv:2401.13996 [cs.CL]
- Guanghui Qin and Jason Eisner. 2021. Learning how to ask: Querying LMs with mixtures of soft prompts. arXiv preprint arXiv:2104.06599 (2021).
- Tool learning with foundation models. arXiv preprint arXiv:2304.08354 (2023).
- Toolllm: Facilitating large language models to master 16000+ real-world apis. arXiv preprint arXiv:2307.16789 (2023).
- Learning transferable visual models from natural language supervision. In International conference on machine learning. PMLR, 8748–8763.
- Language models are unsupervised multitask learners. OpenAI blog 1, 8 (2019), 9.
- Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems 36 (2024).
- Trivellore E Raghunathan. 2021. Synthetic data. Annual review of statistics and its application 8 (2021), 129–140.
- SQuAD: 100,000+ Questions for Machine Comprehension of Text. arXiv:1606.05250 [cs.CL]
- Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 1, 2 (2022), 3.
- Tailoring self-rationalizers with multi-reward distillation. arXiv preprint arXiv:2311.02805 (2023).
- Waseem Rawat and Zenghui Wang. 2017. Deep convolutional neural networks for image classification: A comprehensive review. Neural computation 29, 9 (2017), 2352–2449.
- Android in the wild: A large-scale dataset for android device control. arXiv preprint arXiv:2307.10088 (2023).
- Shahana Rayhan. 2023. Ethical Implications of Creating AGI: Impact on Human Society, Privacy, and Power Dynamics. Artificial Intelligence Review (2023).
- Coqa: A conversational question answering challenge. Transactions of the Association for Computational Linguistics 7 (2019), 249–266.
- Acquisition of Multimodal Models via Retrieval. arXiv preprint arXiv:2302.02916 (2023).
- Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530 (2024).
- Identifying quantum phase transitions with adversarial neural networks. Nature Physics 15, 9 (2019), 917–920.
- Samreen Rizvi. 2023. Blockchain-Based LLMs: A Game Changer for Data Privacy Protection. https://www.dataversity.net/blockchain-based-llms-a-game-changer-for-data-privacy-protection
- High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10684–10695.
- Efficient Content-Based Sparse Attention with Routing Transformers. arXiv:2003.05997 [cs.LG]
- Code Llama: Open Foundation Models for Code. arXiv:2308.12950 [cs.CL]
- Learning to retrieve prompts for in-context learning. arXiv preprint arXiv:2112.08633 (2021).
- Sebastian Ruder. 2020. Why You Should Do NLP Beyond English. http://ruder.io/nlp-beyond-english.
- Stuart Russell. 2019. Human Compatible: Artificial Intelligence and the Problem of Control. Viking.
- SWARM Parallelism: Training Large Models Can Be Surprisingly Communication-Efficient. arXiv:2301.11913 [cs.DC]
- Tandem Transformers for Inference Efficient LLMs. arXiv:2402.08644 [cs.AI]
- Palette: Image-to-image diffusion models. In ACM SIGGRAPH 2022 conference proceedings. 1–10.
- Whose opinions do language models reflect?. In International Conference on Machine Learning. PMLR, 29971–30004.
- Neural theory-of-mind? on the limits of social intelligence in large lms. arXiv preprint arXiv:2210.13312 (2022).
- Testing the general deductive reasoning capacity of large language models using ood examples. Advances in Neural Information Processing Systems 36 (2024).
- Apoorv Saxena. 2023. Prompt Lookup Decoding. https://github.com/apoorvumang/prompt-lookup-decoding/
- Training language models with language feedback at scale. arXiv preprint arXiv:2303.16755 (2023).
- Toolformer: Language models can teach themselves to use tools. arXiv preprint arXiv:2302.04761 (2023).
- Timo Schick and Hinrich Schütze. 2020. Exploiting cloze questions for few shot text classification and natural language inference. arXiv preprint arXiv:2001.07676 (2020).
- Self-diagnosis and self-debiasing: A proposal for reducing corpus-based bias in nlp. Transactions of the Association for Computational Linguistics 9 (2021), 1408–1424.
- Mastering Atari, Go, chess and shogi by planning with a learned model. Nature 588, 7839 (Dec. 2020), 604–609. https://doi.org/10.1038/s41586-020-03051-4
- Green ai. Commun. ACM 63, 12 (2020), 54–63.
- Charbel-Raphaël Segerie. 2023. Task decomposition for scalable oversight (AGISF Distillation). https://www.lesswrong.com/posts/FFz6H35Gy6BArHxkc/task-decomposition-for-scalable-oversight-agisf-distillation.
- AI-Augmented Brainwriting: Investigating the use of LLMs in group ideation. https://doi.org/10.48550/arXiv.2402.14978 arXiv:2402.14978 [cs].
- Blockchain for Deep Learning: Review and Open Challenges. (Oct. 2021). https://doi.org/10.36227/techrxiv.16823140.v1
- Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action. In Conference on Robot Learning. PMLR, 492–504.
- Murray Shanahan and Catherine Clarke. 2023. Evaluating Large Language Model Creativity from a Literary Perspective. arXiv preprint arXiv:2312.03746 (2023).
- Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538 (2017).
- Mathbert: A pre-trained language model for general nlp tasks in mathematics education. arXiv preprint arXiv:2106.07340 (2021).
- Large language model alignment: A survey. arXiv preprint arXiv:2309.15025 (2023).
- Hugginggpt: Solving ai tasks with chatgpt and its friends in huggingface. arXiv preprint arXiv:2303.17580 (2023).
- S-LoRA: Serving Thousands of Concurrent LoRA Adapters. arXiv:2311.03285 [cs.LG]
- FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU. arXiv:2303.06865 [cs.LG]
- Large language models can be easily distracted by irrelevant context. In International Conference on Machine Learning. PMLR, 31210–31227.
- Yell At Your Robot: Improving On-the-Fly from Language Corrections. arXiv:2403.12910 [cs.RO]
- Haotian Liu Hao Zhang Feng Li Tianhe Ren Xueyan Zou Jianwei Yang Hang Su Jun Zhu Lei Zhang Jianfeng Gao Chunyuan Li Shilong Liu, Hao Cheng. 2023. LLaVA-Plus: Learning to Use Tools for Creating Multimodal Agents. arXiv preprint arXiv:2311.05437 (2023).
- BioMegatron: Larger Biomedical Domain Language Model. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (Eds.). Association for Computational Linguistics, Online, 4700–4706. https://doi.org/10.18653/v1/2020.emnlp-main.379
- Reflexion: Language agents with verbal reinforcement learning. In Thirty-seventh Conference on Neural Information Processing Systems.
- Ben Shneiderman and Pattie Maes. 1997. Direct manipulation vs. interface agents. Interactions 4, 6 (1997), 42–61. https://doi.org/10.1145/267505.267514
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. arXiv:1909.08053 [cs.CL]
- Perceiver-Actor: A Multi-Task Transformer for Robotic Manipulation. arXiv:2209.05451 [cs.RO]
- Audio-Visual LLM for Video Understanding. arXiv preprint arXiv:2312.06720 (2023).
- Retrieval augmentation reduces hallucination in conversation. arXiv preprint arXiv:2104.07567 (2021).
- Mastering the game of Go with deep neural networks and tree search. nature 529, 7587 (2016), 484–489.
- Mastering the game of go without human knowledge. nature 550, 7676 (2017), 354–359.
- Progprompt: Generating situated robot task plans using large language models. In 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 11523–11530.
- Simplified State Space Layers for Sequence Modeling. arXiv:2208.04933 [cs.LG]
- Nate Soares. 2016. The value learning problem. Machine Intelligence Research Institute Technical Report 4 (2016).
- Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learning. PMLR, 2256–2265.
- Llm-planner: Few-shot grounded planning for embodied agents with large language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 2998–3009.
- Preference ranking optimization for human alignment. arXiv preprint arXiv:2306.17492 (2023).
- Yang Song and Stefano Ermon. 2019. Generative modeling by estimating gradients of the data distribution. Advances in neural information processing systems 32 (2019).
- Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020).
- Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. arXiv preprint arXiv:2206.04615 (2022).
- Reinforcement Learning from Automatic Feedback for High-Quality Unit Test Generation. arXiv:2310.02368 [cs.SE]
- Learning to summarize with human feedback. Advances in Neural Information Processing Systems 33 (2020), 3008–3021.
- Energy and policy considerations for deep learning in NLP. arXiv preprint arXiv:1906.02243 (2019).
- Sheldon Stryker. 1959. Symbolic interaction as an approach to family research. Marriage and Family Living 21, 2 (1959), 111–119.
- Pandagpt: One model to instruction-follow them all. arXiv preprint arXiv:2305.16355 (2023).
- Evaluating model robustness and stability to dataset shift. In International conference on artificial intelligence and statistics. PMLR, 2611–2619.
- Luminate: Structured Generation and Exploration of Design Space with Large Language Models for Human-AI Co-Creation. https://doi.org/10.1145/3613904.3642400 arXiv:2310.12953 [cs].
- Sensecape: Enabling Multilevel Exploration and Sensemaking with Large Language Models. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23). Association for Computing Machinery, New York, NY, USA, 1–18. https://doi.org/10.1145/3586183.3606756
- Learning multiagent communication with backpropagation. Advances in neural information processing systems 29 (2016).
- Cognitive architectures for language agents. arXiv preprint arXiv:2309.02427 (2023).
- 3D-GPT: Procedural 3D Modeling with Large Language Models. arXiv preprint arXiv:2310.12945 (2023).
- Generative pretraining in multimodality. arXiv preprint arXiv:2307.05222 (2023).
- Retentive Network: A Successor to Transformer for Large Language Models. ArXiv abs/2307.08621 (2023). https://api.semanticscholar.org/CorpusID:259937453
- Principle-driven self-alignment of language models from scratch with minimal human supervision. arXiv preprint arXiv:2305.03047 (2023).
- Principle-driven self-alignment of language models from scratch with minimal human supervision. Advances in Neural Information Processing Systems 36 (2024).
- Easy-to-Hard Generalization: Scalable Alignment Beyond Human Supervision. arXiv preprint arXiv:2403.09472 (2024).
- Value-decomposition networks for cooperative multi-agent learning. arXiv preprint arXiv:1706.05296 (2017).
- An Empirical Study of Multimodal Model Merging. arXiv:2304.14933 [cs.CV]
- Beyond Expertise and Roles: A Framework to Characterize the Stakeholders of Interpretable Machine Learning and their Needs. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI ’21). Association for Computing Machinery, New York, NY, USA, 1–16. https://doi.org/10.1145/3411764.3445088
- Merging by Matching Models in Task Subspaces. arXiv:2312.04339 [cs.LG]
- Understanding the Capabilities, Limitations, and Societal Impact of Large Language Models. http://arxiv.org/abs/2102.02503 arXiv:2102.02503 [cs].
- Towards general computer control: A multimodal agent for red dead redemption ii as a case study. arXiv preprint arXiv:2403.03186 (2024).
- MedAgents: Large Language Models as Collaborators for Zero-shot Medical Reasoning. arXiv:2311.10537 [cs.CL]
- FusionAI: Decentralized Training and Deploying LLMs with Massive Consumer-Level GPUs. arXiv:2309.01172 [cs.DC]
- Stanford Alpaca: An Instruction-following LLaMA model. https://github.com/tatsu-lab/stanford_alpaca.
- Efficient transformers: A survey. Comput. Surveys 55, 6 (2022), 1–28.
- Galactica: A large language model for science. arXiv preprint arXiv:2211.09085 (2022).
- Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023).
- SuperBench Team. 2023. SuperBench is Measuring LLMs in The Open: A Critical Analysis.
- Max Tegmark. 2017. Life 3.0: Being Human in the Age of Artificial Intelligence. Knopf.
- The Economic Times. 2024. China develops groundbreaking nuclear battery that can last 50 years without charging. https://economictimes.indiatimes.com/news/international/business/china-introduces-revolutionary-nuclear-battery-that-lasts-50-years-without-charging/articleshow/106880627.cms?from=mdr
- Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction. https://api.semanticscholar.org/CorpusID:268876071
- DebugBench: Evaluating Debugging Capability of Large Language Models. arXiv:2401.04621 [cs.SE]
- Triton: an intermediate language and compiler for tiled neural network computations. In Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages (Phoenix, AZ, USA) (MAPL 2019). Association for Computing Machinery, New York, NY, USA, 10–19. https://doi.org/10.1145/3315508.3329973
- Memorization Without Overfitting: Analyzing the Training Dynamics of Large Language Models. arXiv:2205.10770 [cs.CL]
- Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs. ArXiv abs/2401.06209 (2024). https://api.semanticscholar.org/CorpusID:266976992
- AutoML in the Age of Large Language Models: Current Challenges, Future Opportunities and Risks. arXiv:2306.08107 [cs.LG]
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023).
- How Many Unicorns Are in This Image? A Safety Evaluation Benchmark for Vision LLMs. arXiv preprint arXiv:2311.16101 (2023).
- ReSee: Responding through Seeing Fine-grained Visual Knowledge in Open-domain Dialogue. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 7720–7735.
- Sight Beyond Text: Multi-Modal Training Enhances LLMs in Truthfulness and Ethics. In NeurIPS 2023 Workshop on Instruction Tuning and Instruction Following.
- A. M. Turing. 1950. Computing Machinery and Intelligence. Mind 59, 236 (1950), 433–460. http://www.jstor.org/stable/2251299
- Victor Turner. 1975. Symbolic studies. Annual review of anthropology 4, 1 (1975), 145–161.
- RetroTRAE: retrosynthetic translation of atomic environments with Transformer. (2022).
- Can Large Language Models Identify And Reason About Security Vulnerabilities? Not Yet. arXiv:2312.12575 [cs.CR]
- Tomer Ullman. 2023. Large language models fail on trivial alterations to theory-of-mind tasks. arXiv preprint arXiv:2302.08399 (2023).
- “The less I type, the better”: How AI Language Models can Enhance or Impede Communication for AAC Users. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI ’23). Association for Computing Machinery, New York, NY, USA, 1–14. https://doi.org/10.1145/3544548.3581560
- Attention is all you need. Advances in neural information processing systems 30 (2017).
- SimNet: Learning Simulation-Based World Models for Physical Reasoning. In International Conference on Learning Representations.
- Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 575 (2019), 350 – 354. https://api.semanticscholar.org/CorpusID:204972004
- Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 575, 7782 (2019), 350–354.
- Peter Voss and Mladjan Jovanovic. 2023. Concepts is All You Need: A More Direct Path to AGI. arXiv preprint arXiv:2309.01622 (2023).
- Counterfactual explanations without opening the black box: Automated decisions and the GDPR. Harvard Journal of Law & Technology 31 (2017), 841.
- GPT-4V(ision) for Robotics: Multimodal Task Planning from Human Demonstration. arXiv:2311.12015 [cs.RO]
- Cost-Effective Hyperparameter Optimization for Large Language Model Generation Inference. arXiv:2303.04673 [cs.CL]
- Designing Theory-Driven User-Centric Explainable AI. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems (CHI ’19). Association for Computing Machinery, New York, NY, USA, 1–15. https://doi.org/10.1145/3290605.3300831
- What Makes for Good Visual Tokenizers for Large Language Models? arXiv preprint arXiv:2305.12223 (2023).
- Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291 (2023).
- The Impact of Deep Learning on Organizational Agility.. In ICIS.
- CocktailSGD: Fine-tuning Foundation Models over 500Mbps Networks. In Proceedings of the 40th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 202), Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett (Eds.). PMLR, 36058–36076. https://proceedings.mlr.press/v202/wang23t.html
- Fine-tuning Language Models over Slow Networks using Activation Compression with Guarantees. arXiv:2206.01299 [cs.LG]
- Pei Wang and Patrick Hammer. 2018. Perception from an AGI perspective. In Artificial General Intelligence: 11th International Conference, AGI 2018, Prague, Czech Republic, August 22-25, 2018, Proceedings 11. Springer, 259–269.
- Conceptions of artificial intelligence and singularity. Information 9, 4 (2018), 79.
- Visionllm: Large language model is also an open-ended decoder for vision-centric tasks. arXiv preprint arXiv:2305.11175 (2023).
- LightSeq: A High Performance Inference Library for Transformers. arXiv:2010.13887 [cs.MS]
- Seggpt: Segmenting everything in context. arXiv preprint arXiv:2304.03284 (2023).
- Mementos: A comprehensive benchmark for multimodal large language model reasoning over image sequences. arXiv preprint arXiv:2401.10529 (2024).
- Self-instruct: Aligning language models with self-generated instructions. arXiv preprint arXiv:2212.10560 (2022).
- Self-Instruct: Aligning Language Models with Self-Generated Instructions. arXiv:2212.10560 [cs.CL]
- Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks. arXiv preprint arXiv:2204.07705 (2022).
- Generalizing from a few examples: A survey on few-shot learning. ACM computing surveys (csur) 53, 3 (2020), 1–34.
- Jarvis-1: Open-world multi-task agents with memory-augmented multimodal language models. arXiv preprint arXiv:2311.05997 (2023).
- Describe, explain, plan and select: Interactive planning with large language models enables open-world multi-task agents. arXiv preprint arXiv:2302.01560 (2023).
- De-Diffusion Makes Text a Strong Cross-Modal Interface. arXiv preprint arXiv:2311.00618 (2023).
- Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652 (2021).
- Emergent Abilities of Large Language Models. arXiv:2206.07682 [cs.CL]
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems 35 (2022), 24824–24837.
- Ethical and social risks of harm from language models. arXiv preprint arXiv:2112.04359 (2021).
- Design Principles for Generative AI Applications. https://doi.org/10.1145/3613904.3642466 arXiv:2401.14484 [cs].
- DiLu: A Knowledge-Driven Approach to Autonomous Driving with Large Language Models. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=OqTMUPuLuC
- Kyle Wiggers. 2021. AI datasets are prone to mismanagement, study finds. https://venturebeat.com/ai/ai-datasets-are-prone-to-mismanagement-study-finds/
- Language Models are Few-shot Multilingual Learners. https://doi.org/10.48550/arXiv.2109.07684 arXiv:2109.07684 [cs].
- Machine ethics: The design and governance of ethical AI and autonomous systems [scanning the issue]. Proc. IEEE 107, 3 (2019), 509–517.
- Refining Decompiled C Code with Large Language Models. arXiv:2310.06530 [cs.SE]
- Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. arXiv:2203.05482 [cs.LG]
- Fast Distributed Inference Serving for Large Language Models. arXiv:2305.05920 [cs.LG]
- π𝜋\piitalic_π-Tuning: Transferring Multimodal Foundation Models with Optimal Multi-task Interpolation. arXiv:2304.14381 [cs.CV]
- Learning to See Physics via Visual De-animation. In Advances in Neural Information Processing Systems, I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (Eds.), Vol. 30. Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2017/file/4c56ff4ce4aaf9573aa5dff913df997a-Paper.pdf
- A brief overview of ChatGPT: The history, status quo and potential future development. IEEE/CAA Journal of Automatica Sinica 10, 5 (2023), 1122–1136.
- PromptChainer: Chaining Large Language Model Prompts through Visual Programming. https://doi.org/10.48550/arXiv.2203.06566 arXiv:2203.06566 [cs].
- AI Chains: Transparent and Controllable Human-AI Interaction by Chaining Large Language Model Prompts. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems (CHI ’22). Association for Computing Machinery, New York, NY, USA, 1–22. https://doi.org/10.1145/3491102.3517582
- Do language models plan ahead for future tokens? arXiv preprint arXiv:2404.00859 (2024).
- ReFT: Representation Finetuning for Language Models. arXiv preprint arXiv:2404.03592 (2024).
- OS-Copilot: Towards Generalist Computer Agents with Self-Improvement. arXiv:2402.07456 [cs.AI]
- The rise and potential of large language model based agents: A survey. arXiv preprint arXiv:2309.07864 (2023).
- Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference with Unstructured Sparsity. arXiv:2309.10285 [cs.DC]
- Training Trajectories of Language Models Across Scales. arXiv:2212.09803 [cs.CL]
- Language Models Meet World Models: Embodied Experiences Enhance Language Models. In Thirty-seventh Conference on Neural Information Processing Systems. https://openreview.net/forum?id=SVBR6xBaMl
- SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models. arXiv:2211.10438 [cs.CL]
- Efficient Streaming Language Models with Attention Sinks. arXiv:2309.17453 [cs.CL]
- Translating natural language to planning goals with large-language models. arXiv preprint arXiv:2302.05128 (2023).
- Effective Long-Context Scaling of Foundation Models. arXiv:2309.16039 [cs.CL]
- Leashing the Inner Demons: Self-Detoxification for Language Models. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 36. 11530–11537.
- Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244 (2023).
- A Survey on Game Playing Agents and Large Models: Methods, Applications, and Challenges. arXiv preprint arXiv:2403.10249 (2024).
- Roman V Yampolskiy. 2020. Artificial Intelligence Safety and Security. CRC Press.
- King-Yin Yan. 2022. AGI via Combining Logic with Deep Learning. In Artificial General Intelligence: 14th International Conference, AGI 2021, Palo Alto, CA, USA, October 15–18, 2021, Proceedings 14. Springer, 327–343.
- InterCode: Standardizing and Benchmarking Interactive Coding with Execution Feedback. arXiv:2306.14898 [cs.CL]
- Diffusion models: A comprehensive survey of methods and applications. Comput. Surveys 56, 4 (2023), 1–39.
- Harnessing Biomedical Literature to Calibrate Clinicians’ Trust in AI Decision Support Systems. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. ACM, Hamburg Germany, 1–14. https://doi.org/10.1145/3544548.3581393
- Re-examining Whether, Why, and How Human-AI Interaction Is Uniquely Difficult to Design. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems (CHI ’20). Association for Computing Machinery, New York, NY, USA, 1–13. https://doi.org/10.1145/3313831.3376301
- Gpt4tools: Teaching large language model to use tools via self-instruction. arXiv preprint arXiv:2305.18752 (2023).
- Gated linear attention transformers with hardware-efficient training. arXiv preprint arXiv:2312.06635 (2023).
- AppAgent: Multimodal Agents as Smartphone Users. arXiv preprint arXiv:2312.13771 (2023).
- Keep calm and explore: Language models for action generation in text-based games. arXiv preprint arXiv:2010.02903 (2020).
- Tree of thoughts: Deliberate problem solving with large language models. arXiv preprint arXiv:2305.10601 (2023).
- React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629 (2022).
- A survey on large language model (llm) security and privacy: The good, the bad, and the ugly. High-Confidence Computing (2024), 100211.
- mplug-owl: Modularization empowers large language models with multimodality. arXiv preprint arXiv:2304.14178 (2023).
- Anil Yemme and Shayan Srinivasa Garani. 2023. A Scalable GPT-2 Inference Hardware Architecture on FPGA. In 2023 International Joint Conference on Neural Networks (IJCNN). 1–8. https://doi.org/10.1109/IJCNN54540.2023.10191067
- A Survey on Multimodal Large Language Models. arXiv preprint arXiv:2306.13549 (2023).
- William York and Jerry Swan. 2012. Taking Turing Seriously.
- Orca: A Distributed Serving System for Transformer-Based Generative Models. In 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). USENIX Association, Carlsbad, CA, 521–538. https://www.usenix.org/conference/osdi22/presentation/yu
- Building ethics into artificial intelligence. In Proceedings of the 27th International Joint Conference on Artificial Intelligence. 5527–5533.
- Language to rewards for robotic skill synthesis. arXiv preprint arXiv:2306.08647 (2023).
- Decentralized Training of Foundation Models in Heterogeneous Environments. arXiv:2206.01288 [cs.DC]
- Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. arXiv preprint arXiv:2311.16502 (2023).
- Lotfi A Zadeh. 1996. Fuzzy logic, neural networks, and soft computing. In Fuzzy sets, fuzzy logic, and fuzzy systems: selected papers by Lotfi A Zadeh. World Scientific, 775–782.
- Why Johnny Can’t Prompt: How Non-AI Experts Try (and Fail) to Design LLM Prompts. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI ’23). Association for Computing Machinery, New York, NY, USA, 1–21. https://doi.org/10.1145/3544548.3581388
- ByteTransformer: A High-Performance Transformer Boosted for Variable-Length Inputs. arXiv:2210.03052 [cs.LG]
- UFO: A UI-Focused Agent for Windows OS Interaction. arXiv preprint arXiv:2402.07939 (2024).
- A Simple LLM Framework for Long-Range Video Question-Answering. arXiv preprint arXiv:2312.17235 (2023).
- Building cooperative embodied agents modularly with large language models. arXiv preprint arXiv:2307.02485 (2023).
- Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858 (2023).
- Draft & Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding. arXiv:2309.08168 [cs.CL]
- Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 3836–3847.
- What if the tv was off? examining counterfactual reasoning abilities of multi-modal language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 4629–4633.
- AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning. arXiv:2303.10512 [cs.CL]
- LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention. arXiv:2303.16199 [cs.CV]
- Llama-adapter: Efficient fine-tuning of language models with zero-init attention. arXiv preprint arXiv:2303.16199 (2023).
- NOIR: Neural Signal Operated Intelligent Robots for Everyday Activities. In 7th Annual Conference on Robot Learning. https://openreview.net/forum?id=eyykI3UIHa
- OPT: Open Pre-trained Transformer Language Models. arXiv:2205.01068 [cs.CL]
- Rethinking Human-AI Collaboration in Complex Medical Decision Making: A Case Study in Sepsis Diagnosis. https://doi.org/10.1145/3613904.3642343 arXiv:2309.12368 [cs].
- From dark matter to galaxies with convolutional networks. Proceedings of the National Academy of Sciences 116, 28 (2019), 13825–13832.
- Privacyasst: Safeguarding user privacy in tool-using large language model agents. IEEE Transactions on Dependable and Secure Computing (2024).
- MetaSim: Learning to Generate Synthetic Datasets. arXiv preprint arXiv:2302.03213 (2023).
- Effect of confidence and explanation on accuracy and trust calibration in AI-assisted decision making. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency (FAT* ’20). Association for Computing Machinery, New York, NY, USA, 295–305. https://doi.org/10.1145/3351095.3372852
- A Survey on the Memory Mechanism of Large Language Model based Agents. arXiv preprint arXiv:2404.13501 (2024).
- H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models. arXiv:2306.14048 [cs.LG]
- Automatic chain of thought prompting in large language models. arXiv preprint arXiv:2210.03493 (2022).
- Expel: Llm agents are experiential learners. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 19632–19642.
- Tuning LayerNorm in Attention: Towards Efficient Multi-Modal LLM Finetuning. arXiv preprint arXiv:2312.11420 (2023).
- GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection. arXiv preprint arXiv:2403.03507 (2024).
- Slic-hf: Sequence likelihood calibration with human feedback. arXiv preprint arXiv:2305.10425 (2023).
- On evaluating adversarial robustness of large vision-language models. arXiv preprint arXiv:2305.16934 (2023).
- Assessing and Understanding Creativity in Large Language Models. arXiv preprint arXiv:2401.12491 (2024).
- Progressive-hint prompting improves reasoning in large language models. arXiv preprint arXiv:2304.09797 (2023).
- Minigpt-5: Interleaved vision-and-language generation via generative vokens. arXiv preprint arXiv:2310.02239 (2023).
- Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems 36 (2024).
- Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning. arXiv:2201.12023 [cs.LG]
- Can chatgpt understand too? a comparative study on chatgpt and fine-tuned bert. arXiv preprint arXiv:2302.10198 (2023).
- Agieval: A human-centric benchmark for evaluating foundation models. arXiv preprint arXiv:2304.06364 (2023).
- Lima: Less is more for alignment. Advances in Neural Information Processing Systems 36 (2024).
- Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625 (2022).
- Jian Zhou and Olga G Troyanskaya. 2015. Predicting effects of noncoding variants with deep learning–based sequence model. Nature methods 12, 10 (2015), 931–934.
- Navigating the grey area: Expressions of overconfidence and uncertainty in language models. arXiv preprint arXiv:2302.13439 (2023).
- WebArena: A Realistic Web Environment for Building Autonomous Agents. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=oKn9c6ytLx
- Agents: An open-source framework for autonomous language agents. arXiv preprint arXiv:2309.07870 (2023).
- Mixture-of-Experts with Expert Choice Routing. arXiv:2202.09368 [cs.LG]
- Large Language Models Are Human-Level Prompt Engineers. arXiv:2211.01910 [cs.LG]
- Principled Reinforcement Learning with Human Feedback from Pairwise or K𝐾Kitalic_K-wise Comparisons. arXiv preprint arXiv:2301.11270 (2023).
- LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment. arXiv preprint arXiv:2310.01852 (2023).
- Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592 (2023).
- ToolQA: A Dataset for LLM Question Answering with External Tools. arXiv preprint arXiv:2306.13304 (2023).
- Mindstorms in natural language-based societies of mind. arXiv preprint arXiv:2305.17066 (2023).
- Maximum entropy inverse reinforcement learning.. In Aaai, Vol. 8. Chicago, IL, USA, 1433–1438.
- Auto-pytorch tabular: Multi-fidelity metalearning for efficient and robust autodl. arXiv preprint arXiv:2006.13799 (2020).

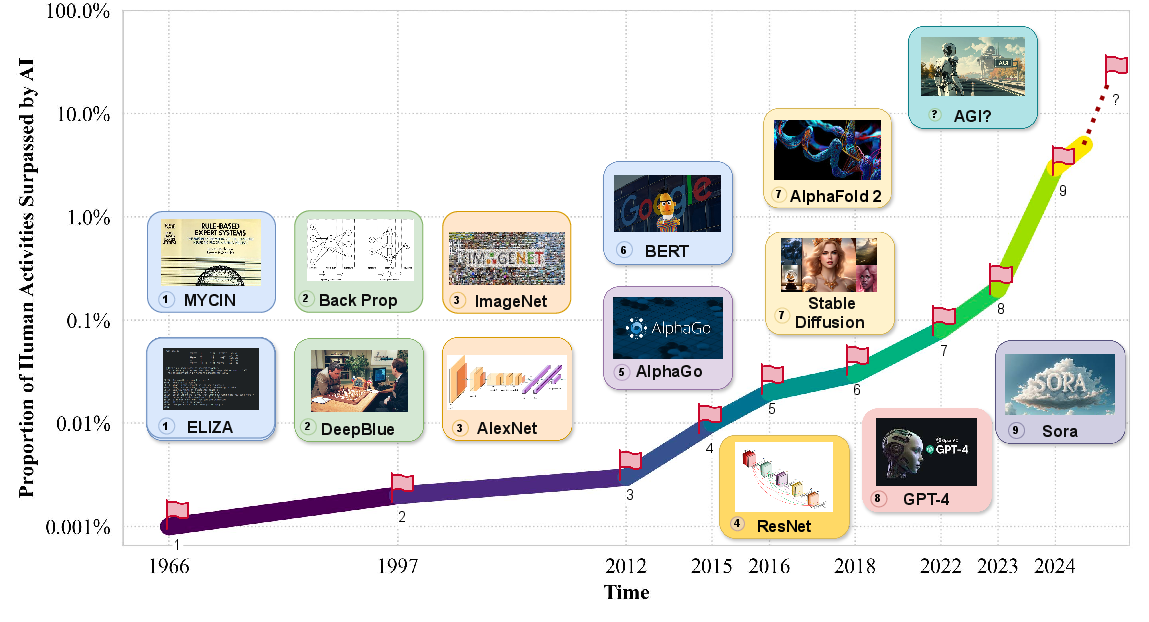
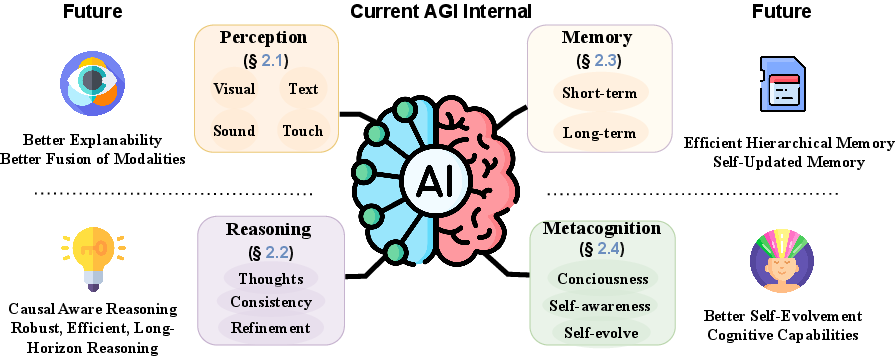
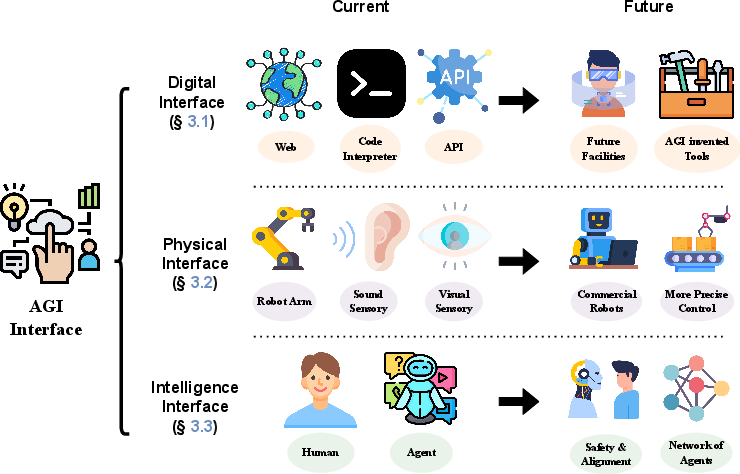
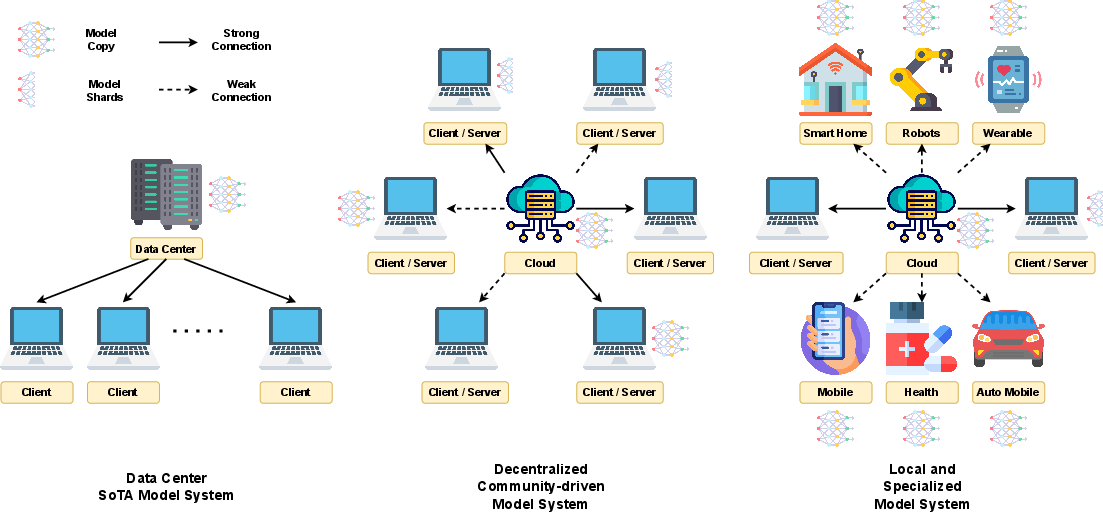
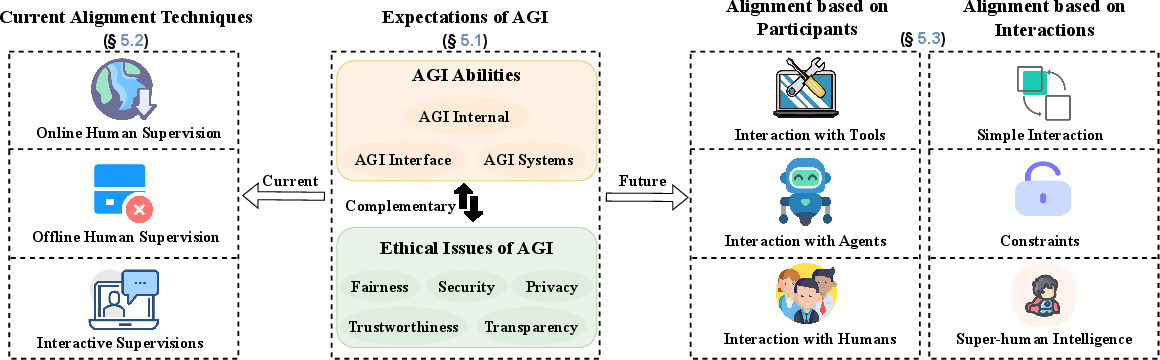
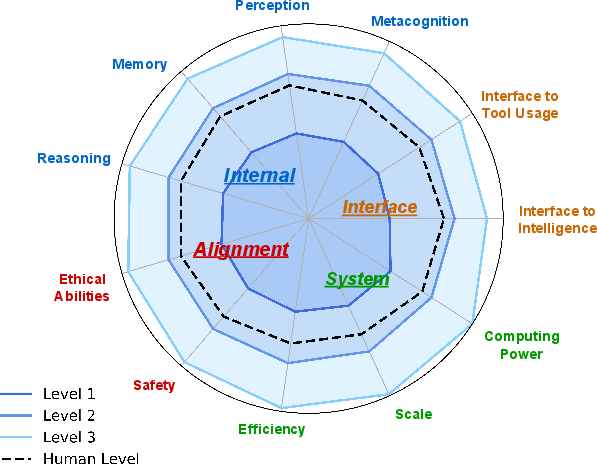
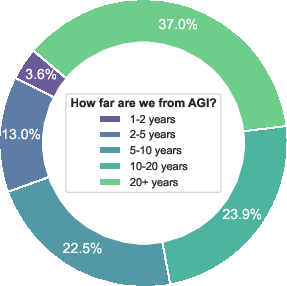
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

