Voice Attribute Editing with Text Prompt
Abstract: Despite recent advancements in speech generation with text prompt providing control over speech style, voice attributes in synthesized speech remain elusive and challenging to control. This paper introduces a novel task: voice attribute editing with text prompt, with the goal of making relative modifications to voice attributes according to the actions described in the text prompt. To solve this task, VoxEditor, an end-to-end generative model, is proposed. In VoxEditor, addressing the insufficiency of text prompt, a Residual Memory (ResMem) block is designed, that efficiently maps voice attributes and these descriptors into the shared feature space. Additionally, the ResMem block is enhanced with a voice attribute degree prediction (VADP) block to align voice attributes with corresponding descriptors, addressing the imprecision of text prompt caused by non-quantitative descriptions of voice attributes. We also establish the open-source VCTK-RVA dataset, which leads the way in manual annotations detailing voice characteristic differences among different speakers. Extensive experiments demonstrate the effectiveness and generalizability of our proposed method in terms of both objective and subjective metrics. The dataset and audio samples are available on the website.
- GPU accelerated t-distributed stochastic neighbor embedding. J. Parallel Distributed Comput., 131:1–13.
- Wavlm: Large-scale self-supervised pre-training for full stack speech processing. IEEE J. Sel. Top. Signal Process., 16(6):1505–1518.
- Cross-modal memory networks for radiology report generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, August 1-6, 2021, pages 5904–5914. Association for Computational Linguistics.
- ECAPA-TDNN: emphasized channel attention, propagation and aggregation in TDNN based speaker verification. In Interspeech 2020, 21st Annual Conference of the International Speech Communication Association, Virtual Event, Shanghai, China, 25-29 October 2020, pages 3830–3834. ISCA.
- BERT: pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), pages 4171–4186. Association for Computational Linguistics.
- Prompttts: Controllable text-to-speech with text descriptions. In IEEE International Conference on Acoustics, Speech and Signal Processing ICASSP 2023, Rhodes Island, Greece, June 4-10, 2023, pages 1–5. IEEE.
- Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
- Textrolspeech: A text style control speech corpus with codec language text-to-speech models. CoRR, abs/2308.14430.
- Imagic: Text-based real image editing with diffusion models. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 6007–6017. IEEE.
- Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
- Prompttts 2: Describing and generating voices with text prompt. CoRR, abs/2309.02285.
- Freevc: Towards high-quality text-free one-shot voice conversion. In IEEE International Conference on Acoustics, Speech and Signal Processing ICASSP 2023, Rhodes Island, Greece, June 4-10, 2023, pages 1–5. IEEE.
- Promptstyle: Controllable style transfer for text-to-speech with natural language descriptions. CoRR, abs/2305.19522.
- Seyed Hamidreza Mohammadi and Alexander Kain. 2017. An overview of voice conversion systems. Speech Commun., 88:65–82.
- Face-driven zero-shot voice conversion with memory-based face-voice alignment. In Proceedings of the 31st ACM International Conference on Multimedia, MM 2023, Ottawa, ON, Canada, 29 October 2023- 3 November 2023, pages 8443–8452. ACM.
- Prompttts++: Controlling speaker identity in prompt-based text-to-speech using natural language descriptions. CoRR, abs/2309.08140.
- Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit.
- Zachary Wallmark and Roger A Kendall. 2018. Describing sound: The cognitive linguistics of timbre.
- COCO-NUT: corpus of japanese utterance and voice characteristics description for prompt-based control. In IEEE Automatic Speech Recognition and Understanding Workshop, ASRU 2023, Taipei, Taiwan, December 16-20, 2023, pages 1–8. IEEE.
- Memory networks. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings.
- Instructtts: Modelling expressive TTS in discrete latent space with natural language style prompt. CoRR, abs/2301.13662.
- Promptvc: Flexible stylistic voice conversion in latent space driven by natural language prompts. CoRR, abs/2309.09262.
- Promptspeaker: Speaker generation based on text descriptions. In IEEE Automatic Speech Recognition and Understanding Workshop, ASRU 2023, Taipei, Taiwan, December 16-20, 2023, pages 1–7. IEEE.
- Content-dependent fine-grained speaker embedding for zero-shot speaker adaptation in text-to-speech synthesis. In Interspeech 2022, 23rd Annual Conference of the International Speech Communication Association, Incheon, Korea, 18-22 September 2022, pages 2573–2577. ISCA.

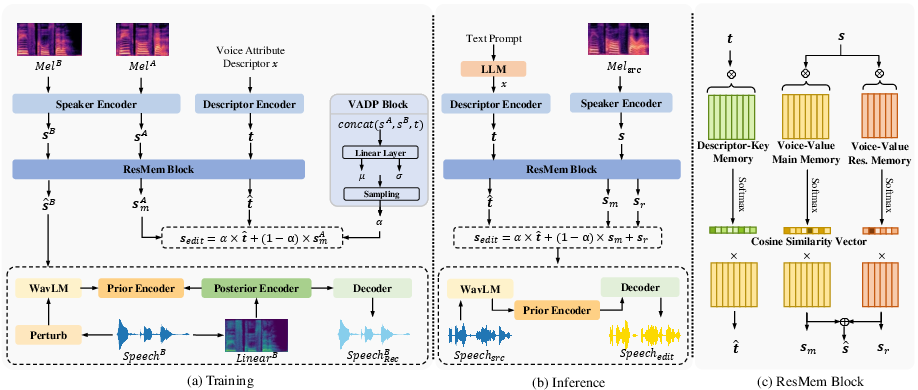 *Figure 2: The overall flowchart of our proposed VoxEditor. During the training process, two speech segments (SpeechA and SpeechB) are used, along with voice attribute descriptor x. In the inference process, the model takes source speech and the text prompt as inputs to generate edited speech. Here Mel denotes the Mel spectrograms, Linear denotes the linear spectrograms, $\bm{s$
*Figure 2: The overall flowchart of our proposed VoxEditor. During the training process, two speech segments (SpeechA and SpeechB) are used, along with voice attribute descriptor x. In the inference process, the model takes source speech and the text prompt as inputs to generate edited speech. Here Mel denotes the Mel spectrograms, Linear denotes the linear spectrograms, $\bm{s$
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

