Learning Spatial Adaptation and Temporal Coherence in Diffusion Models for Video Super-Resolution
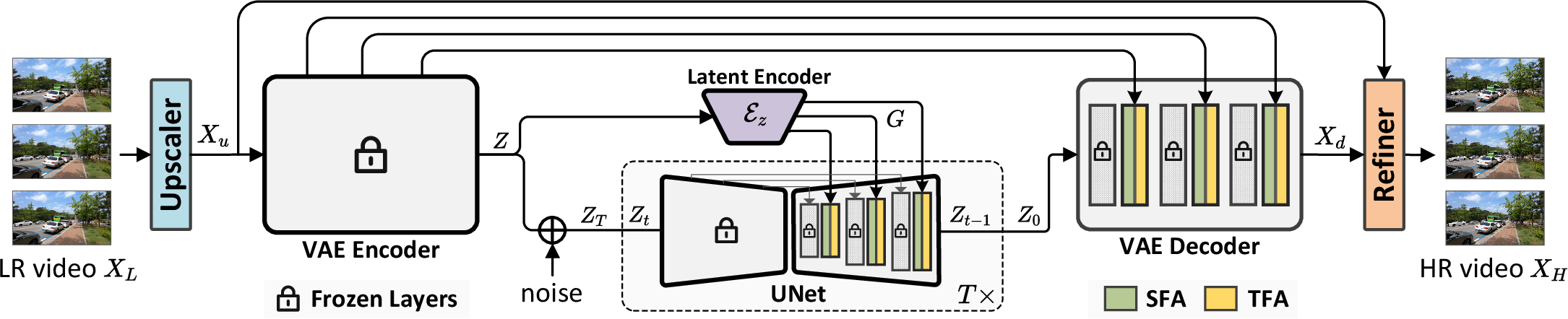
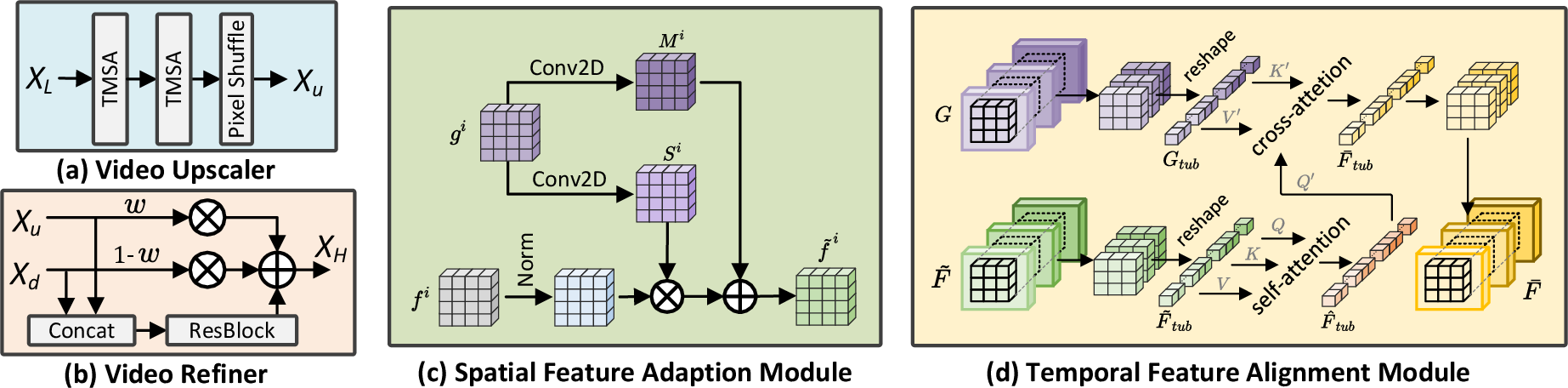
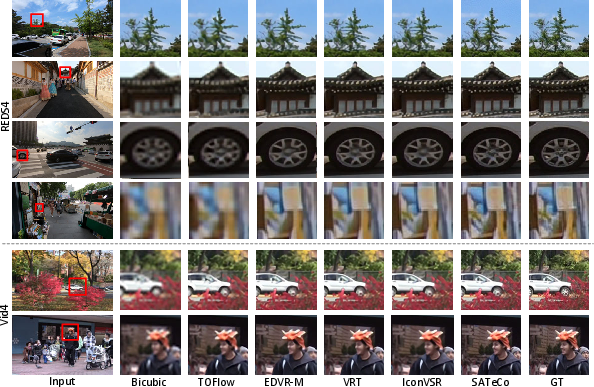
Abstract: Diffusion models are just at a tipping point for image super-resolution task. Nevertheless, it is not trivial to capitalize on diffusion models for video super-resolution which necessitates not only the preservation of visual appearance from low-resolution to high-resolution videos, but also the temporal consistency across video frames. In this paper, we propose a novel approach, pursuing Spatial Adaptation and Temporal Coherence (SATeCo), for video super-resolution. SATeCo pivots on learning spatial-temporal guidance from low-resolution videos to calibrate both latent-space high-resolution video denoising and pixel-space video reconstruction. Technically, SATeCo freezes all the parameters of the pre-trained UNet and VAE, and only optimizes two deliberately-designed spatial feature adaptation (SFA) and temporal feature alignment (TFA) modules, in the decoder of UNet and VAE. SFA modulates frame features via adaptively estimating affine parameters for each pixel, guaranteeing pixel-wise guidance for high-resolution frame synthesis. TFA delves into feature interaction within a 3D local window (tubelet) through self-attention, and executes cross-attention between tubelet and its low-resolution counterpart to guide temporal feature alignment. Extensive experiments conducted on the REDS4 and Vid4 datasets demonstrate the effectiveness of our approach.
- Real-time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation. In CVPR, 2017.
- BasicVSR: The Search for Essential Components in Video Super-Resolution and Beyond. In CVPR, 2021.
- BasicVSR++: Improving Video Super-Resolution with Enhanced Propagation and Alignment. In CVPR, 2022a.
- Investigating Tradeoffs in Real-World Video Super-Resolution. In CVPR, 2022b.
- Two Deterministic Half-quadratic Regularization Algorithms for Computed Imaging. In ICIP, 1994.
- AnchorFormer: Point Cloud Completion from Discriminative Nodes. In CVPR, 2023.
- ILVR: Conditioning Method for Denoising Diffusion Probabilistic Models. In ICCV, 2021.
- Perception Prioritized Training of Diffusion Models. In CVPR, 2022.
- Improving Diffusion Dodels for Inverse Problems Using Manifold Constraints. In NeurIPS, 2022.
- Diffusion Posterior Sampling for General Noisy Inverse Problems. In ICLR, 2023.
- Diffusion Models Beat GANs on Image Synthesis. In NeurIPS, 2021.
- Image Quality Assessment: Unifying Structure and Texture Similarity. IEEE TPAMI, 2020.
- Generative Diffusion Prior for Unified Image Restoration and Enhancement. In CVPR, 2023.
- RSTT: Real-time Spatial Temporal Transformer for Space-Time Video Super-Resolution. In CVPR, 2022.
- Recurrent Back-Projection Network for Video Super-Resolution. In CVPR, 2019.
- Prompt-to-Prompt Image Editing with Cross-Attention Control. In ICLR, 2023.
- Video Super-Resolution via Bidirectional Recurrent Convolutional Networks. IEEE TPAMI, 2017.
- Video Super-Resolution with Recurrent Structure-Detail Network. In ECCV, 2020a.
- Video Super-resolution with Temporal Group Attention. In CVPR, 2020b.
- Deep Video Super-Resolution Network Using Dynamic Upsampling Filters Without Explicit Motion Compensation. In CVPR, 2018.
- Denoising Diffusion Restoration Models. In NeurIPS, 2022.
- MuCAN: Multi-Correspondence Aggregation Network for Video Super-Resolution. In ECCV, 2020.
- VRT: A Video Restoration Transformer. arXiv:2201.12288, 2022a.
- Recurrent Video Restoration Transformer with Guided Deformable Attention. In NeurIPS, 2022b.
- On Bayesian Adaptive Video Super Resolution. IEEE TPAMI, 2013.
- Learning Trajectory-Aware Transformer for Video Super-Resolution. In CVPR, 2022.
- Stand-Alone Inter-Frame Attention in Video Models. In CVPR, 2022a.
- Dynamic Temporal Filtering in Video Models. In ECCV, 2022b.
- PointClustering: Unsupervised Point Cloud Pre-training using Transformation Invariance in Clustering. In CVPR, 2023.
- VideoDrafter: Content-Consistent Multi-Scene Video Generation with LLM. arXiv:2401.01256, 2024.
- Diffusion Model Based Posterior Sampling for Noisy Linear Inverse Problems. arXiv:2211.12343, 2022.
- Making a “Completely Blind” Image Quality Analyzer. IEEE SPL, 2012.
- NTIRE 2019 Challenge on Video Deblurring and Super-Resolution: Dataset and Study. In CVPRW, 2019.
- Glide: Towards Photorealistic Image Generation and Editing with Text-guided Diffusion Models. In ICML, 2022.
- Learning Transferable Visual Models From Natural Language Supervision. In ICML, 2021.
- High-Resolution Image Synthesis with Latent Diffusion Models. In CVPR, 2022.
- Palette: Image-to-Image Diffusion Models. In ACM SIGGRAPH, 2022.
- Frame-Recurrent Video Super-Resolution. In CVPR, 2018.
- Rethinking Alignment in Video Super-Resolution Transformers. In NeurIPS, 2022.
- Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In CVPR, 2016.
- Very Deep Convolutional Networks for Large-Scale Image Recognition. In ICLR, 2015.
- Pseudoinverse-guided Diffusion Models for Inverse Problems. In ICLR, 2022.
- TDAN: Temporally-Deformable Alignment Network for Video Super-Resolution. In CVPR, 2020.
- Diffusers: State-of-the-art Diffusion Models, 2022.
- Exploring CLIP for Assessing the Look and Feel of Images. In AAAI, 2023a.
- Exploiting Diffusion Prior for Real-World Image Super-Resolution. arXiv:2305.07015, 2023b.
- Deep Video Super-Resolution using HR Optical Flow Estimation. IEEE TIP, 2020.
- EDVR: Video Restoration with Enhanced Deformable Convolutional Networks. In CVPRW, 2019.
- Zero-Shot Image Restoration Using Denoising Diffusion Null-Space Model. In ICLR, 2023c.
- Temporal Modulation Network for Controllable Space-Time Video Super-Resolution. In CVPR, 2021.
- Video Enhancement with Task-Oriented Flow. IJCV, 2019.
- Pixel-Aware Stable Diffusion for Realistic Image Super-Resolution and Personalized Stylization. arXiv:2308.14469, 2023.
- Progressive Fusion Video Super-Resolution Network via Exploiting Non-Local Spatio-Temporal Correlations. In ICCV, 2019.
- Omniscient Video Super-Resolution. In ICCV, 2021.
- Adding Conditional Control to Text-to-Image Diffusion Models. In ICCV, 2023.
- The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In CVPR, 2018.
- Denoising Diffusion Models for Plug-and-Play Image Restoration. In CVPRW, 2023.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.