StableToolBench: Towards Stable Large-Scale Benchmarking on Tool Learning of Large Language Models
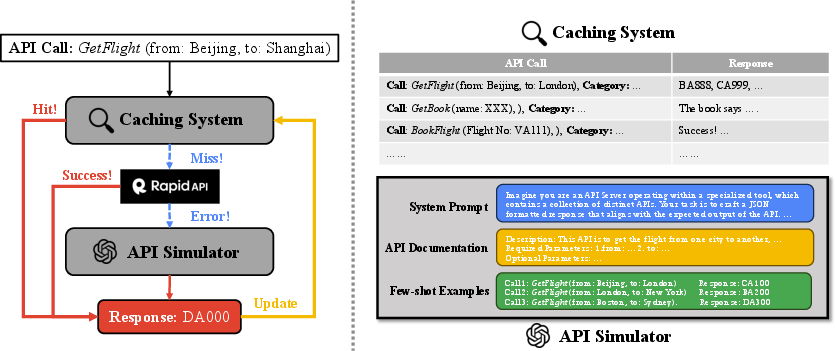
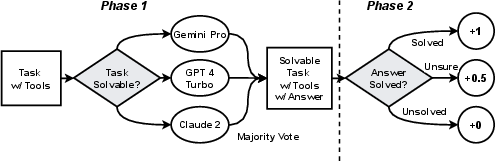
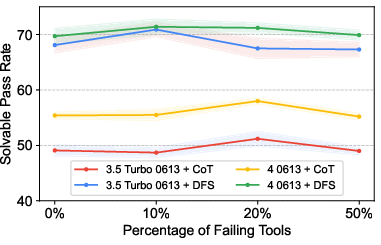
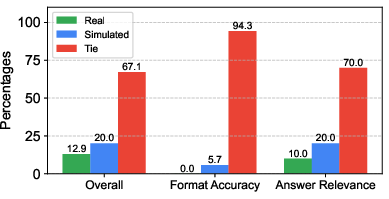
Abstract: LLMs have witnessed remarkable advancements in recent years, prompting the exploration of tool learning, which integrates LLMs with external tools to address diverse real-world challenges. Assessing the capability of LLMs to utilise tools necessitates large-scale and stable benchmarks. However, previous works relied on either hand-crafted online tools with limited scale, or large-scale real online APIs suffering from instability of API status. To address this problem, we introduce StableToolBench, a benchmark evolving from ToolBench, proposing a virtual API server and stable evaluation system. The virtual API server contains a caching system and API simulators which are complementary to alleviate the change in API status. Meanwhile, the stable evaluation system designs solvable pass and win rates using GPT-4 as the automatic evaluator to eliminate the randomness during evaluation. Experimental results demonstrate the stability of StableToolBench, and further discuss the effectiveness of API simulators, the caching system, and the evaluator system.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Large language models as tool makers. In The Twelfth International Conference on Learning Representations.
- Fireact: Toward language agent fine-tuning. arXiv preprint arXiv:2310.05915.
- T-eval: Evaluating the tool utilization capability step by step. arXiv preprint arXiv:2312.14033.
- Gemini Team. 2023. Gemini: A family of highly capable multimodal models.
- Tanmay Gupta and Aniruddha Kembhavi. 2023. Visual programming: Compositional visual reasoning without training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14953–14962.
- Toolkengpt: Augmenting frozen language models with massive tools via tool embeddings. arXiv preprint arXiv:2305.11554.
- Tool documentation enables zero-shot tool-usage with large language models. arXiv preprint arXiv:2308.00675.
- Metatool benchmark for large language models: Deciding whether to use tools and which to use. arXiv preprint arXiv:2310.03128.
- Genegpt: Augmenting large language models with domain tools for improved access to biomedical information. ArXiv.
- Api-bank: A benchmark for tool-augmented llms. arXiv preprint arXiv:2304.08244.
- Api-bank: A benchmark for tool-augmented llms.
- Chameleon: Plug-and-play compositional reasoning with large language models. arXiv preprint arXiv:2304.09842.
- Umap: Uniform manifold approximation and projection. The Journal of Open Source Software, 3(29):861.
- Augmented language models: a survey. arXiv preprint arXiv:2302.07842.
- Webgpt: Browser-assisted question-answering with human feedback.
- OpenAI. 2023. Gpt-4 technical report.
- Gorilla: Large language model connected with massive apis. arXiv preprint arXiv:2305.15334.
- Webcpm: Interactive web search for chinese long-form question answering. arXiv preprint arXiv:2305.06849.
- Tool learning with foundation models. arXiv preprint arXiv:2304.08354.
- Toolllm: Facilitating large language models to master 16000+ real-world apis.
- Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics.
- Tptu: Task planning and tool usage of large language model-based ai agents. arXiv preprint arXiv:2308.03427.
- Toolformer: Language models can teach themselves to use tools. ArXiv preprint, abs/2302.04761.
- Restgpt: Connecting large language models with real-world applications via restful apis. arXiv preprint arXiv:2306.06624.
- Toolalpaca: Generalized tool learning for language models with 3000 simulated cases.
- Llama: Open and efficient foundation language models.
- Alan M. Turing. 2009. Computing Machinery and Intelligence, pages 23–65. Springer Netherlands, Dordrecht.
- Mint: Evaluating llms in multi-turn interaction with tools and language feedback. arXiv preprint arXiv:2309.10691.
- Chain-of-thought prompting elicits reasoning in large language models.
- On the tool manipulation capability of open-source large language models.
- Chatgpt is not enough: Enhancing large language models with knowledge graphs for fact-aware language modeling. arXiv preprint arXiv:2306.11489.
- Gpt4tools: Teaching large language model to use tools via self-instruction.
- Webshop: Towards scalable real-world web interaction with grounded language agents. In Advances in Neural Information Processing Systems, volume 35, pages 20744–20757. Curran Associates, Inc.
- ReAct: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR).
- Tooleyes: Fine-grained evaluation for tool learning capabilities of large language models in real-world scenarios.
- Toolqa: A dataset for llm question answering with external tools. arXiv preprint arXiv:2306.13304.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.