- The paper presents the AlgoPuzzleVQA dataset that challenges LLMs with algorithmic puzzles integrating visual and logical reasoning.
- It details an automated framework generating puzzles from combinatorics, graph theory, and boolean logic to robustly test multimodal capabilities.
- Results indicate that models like GPT-4V and Gemini Pro perform near-randomly, highlighting gaps in visual perception and algorithmic reasoning.
Multimodal Reasoning Challenges: Insights from AlgoPuzzleVQA
Introduction
The paper "Are LLMs Puzzle Prodigies? Algorithmic Puzzles Unveil Serious Challenges in Multimodal Reasoning" presents the AlgoPuzzleVQA dataset, aimed at benchmarking the ability of multimodal LLMs to solve algorithmic puzzles. These puzzles require an overview of visual, language, and algorithmic reasoning, posing significant challenges to current models like GPT-4V and Gemini Pro. The paper explores the integration of diverse algorithmic topics such as boolean logic, combinatorics, and graph theory into visual question-answering (VQA) tasks.
Dataset and Ontology
AlgoPuzzleVQA is an automatically generated dataset designed to assess LLMs' capabilities to integrate visual data interpretation with algorithmic problem-solving. The dataset includes visual and algorithmic features organized into ontological categories, as illustrated by the visual (Figure 1) and algorithmic examples (Figure 2).
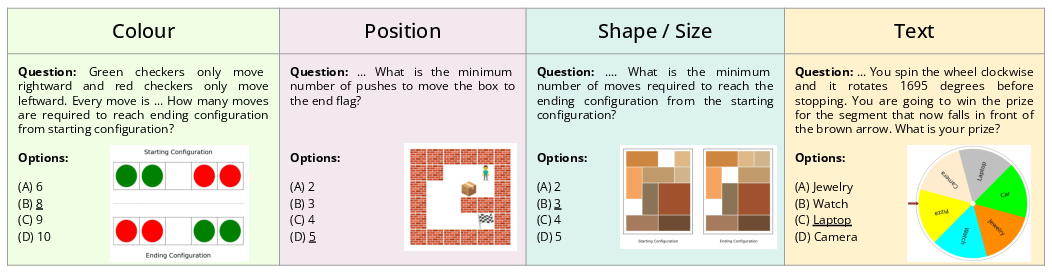
Figure 1: Examples of puzzles in AlgoPuzzleVQA based on visual features.

Figure 2: Examples of puzzles from AlgoPuzzleVQA based on algorithmic features.
Algorithmic puzzles in AlgoPuzzleVQA are designed to be self-contained, providing necessary knowledge as context, thus isolating the problem-solving aspect from mere factual recall. The dataset includes instances from combinatorics, graph algorithms, optimization, search strategies, and more. Importantly, the puzzles have definitive algorithmic solutions.
In evaluating models such as GPT-4V and Gemini Pro, the paper finds that their performance often approaches randomness in a multi-choice setup for a significant number of puzzles. This highlights a fundamental gap in models' ability to integrate and apply algorithmic reasoning in novel contexts.

Figure 3: Puzzle example asking for domino tiling on a checkerboard.
For instance, a puzzle like the domino tiling (Figure 3), based on a general result from Mendelsohn et al., tests models on tiling completeness — a task requiring non-trivial visual and logical deduction. Despite the structured nature of AlgoPuzzleVQA, performance across models demonstrated substantial shortcomings, particularly in visual perception and algorithmic reasoning.
Implementation and Scalability
The dataset’s scalability lies in its automated generation process, allowing for arbitrary increases in reasoning complexity and dataset size. Each puzzle can evolve as models improve, adapting to stronger multimodal capabilities without human reannotation bias. The automated framework permits continuous updates, crucial for maintaining benchmark relevance against progressively advanced models.
Challenges and Future Directions
Current multimodal models struggle significantly, achieving only marginally above-random performance levels, as observed in Table 1 for various models. These findings underscore the complexity and challenge of multimodal reasoning tasks embedded in AlgoPuzzleVQA. The dataset effectively delineates the visual and algorithmic skills models currently lack, providing a blueprint for development focus areas.
The potential improvement routes include enhancing visual perception capabilities and strengthening algorithmic reasoning faculties. Future versions of AlgoPuzzleVQA could incorporate broader puzzle varieties and finer-grained ontological categories to refine model assessments further. Additionally, exploring models that can generate code may offer new avenues for enhancing algorithmic reasoning capabilities.
Conclusion
AlgoPuzzleVQA serves as both a challenge and an opportunity for advancing multimodal AI. It lays bare the deficiencies in current state-of-the-art models regarding complex reasoning under a multimodal framework. The dataset should fuel further research into models that not only understand but can reason across domains of vision, language, and algorithms, fostering AI systems capable of tackling real-world complex problem-solving.