PRoLoRA: Partial Rotation Empowers More Parameter-Efficient LoRA
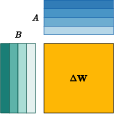
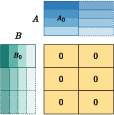
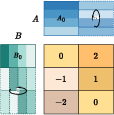
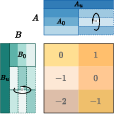
Abstract: With the rapid scaling of LLMs, serving numerous low-rank adaptations (LoRAs) concurrently has become increasingly impractical, leading to unaffordable costs and necessitating more parameter-efficient finetuning methods. In this work, we introduce Partially Rotation-enhanced Low-Rank Adaptation (PRoLoRA), an intra-layer sharing mechanism comprising four essential components: broadcast reduction, rotation enhancement, partially-sharing refinement, and rectified initialization strategy. As a superset of LoRA, PRoLoRA retains its advantages, and effectively circumvent the drawbacks of peer parameter-sharing methods with superior model capacity, practical feasibility, and broad applicability. Empirical experiments demonstrate the remarkably higher parameter efficiency of PRoLoRA in both specific parameter budget and performance target scenarios, and its scalability to larger LLMs. Notably, with one time less trainable parameters, PRoLoRA still outperforms LoRA on multiple instruction tuning datasets. Subsequently, an ablation study is conducted to validate the necessity of individual components and highlight the superiority of PRoLoRA over three potential variants. Hopefully, the conspicuously higher parameter efficiency can establish PRoLoRA as a resource-friendly alternative to LoRA.
- Intrinsic dimensionality explains the effectiveness of language model fine-tuning. arXiv preprint arXiv:2012.13255.
- Sahil Chaudhary. 2023. Code alpaca: An instruction-following llama model for code generation. https://github.com/sahil280114/codealpaca.
- Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374.
- Llava-mole: Sparse mixture of lora experts for mitigating data conflicts in instruction finetuning mllms. arXiv preprint arXiv:2401.16160.
- Netgpt: A native-ai network architecture beyond provisioning personalized generative services. arXiv preprint arXiv:2307.06148.
- Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416.
- Tydi qa: A benchmark for information-seeking question answering in ty pologically di verse languages. Transactions of the Association for Computational Linguistics, 8:454–470.
- Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Universal transformers. arXiv preprint arXiv:1807.03819.
- Qlora: Efficient finetuning of quantized llms. arXiv preprint arXiv:2305.14314.
- Edgeformer: A parameter-efficient transformer for on-device seq2seq generation. arXiv preprint arXiv:2202.07959.
- Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE international conference on computer vision, pages 1026–1034.
- Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR).
- Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, pages 2790–2799. PMLR.
- Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
- Lorahub: Efficient cross-task generalization via dynamic lora composition. arXiv preprint arXiv:2307.13269.
- Vera: Vector-based random matrix adaptation. arXiv preprint arXiv:2310.11454.
- Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles.
- P-tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 61–68.
- The flan collection: Designing data and methods for effective instruction tuning. arXiv preprint arXiv:2301.13688.
- Dictformer: Tiny transformer with shared dictionary. In International Conference on Learning Representations.
- Peft: State-of-the-art parameter-efficient fine-tuning methods. https://github.com/huggingface/peft.
- OpenAI. 2023. Gpt-4 technical report.
- One wide feedforward is all you need. arXiv preprint arXiv:2309.01826.
- Subformer: Exploring weight sharing for parameter efficiency in generative transformers. arXiv preprint arXiv:2101.00234.
- Tied-lora: Enhacing parameter efficiency of lora with weight tying. arXiv preprint arXiv:2311.09578.
- Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. arXiv preprint arXiv:2206.04615.
- Challenging big-bench tasks and whether chain-of-thought can solve them. arXiv preprint arXiv:2210.09261.
- Sho Takase and Shun Kiyono. 2023. Lessons on parameter sharing across layers in transformers. In Proceedings of The Fourth Workshop on Simple and Efficient Natural Language Processing (SustaiNLP), pages 78–90, Toronto, Canada (Hybrid). Association for Computational Linguistics.
- Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- How far can camels go? exploring the state of instruction tuning on open resources. arXiv preprint arXiv:2306.04751.
- Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks. arXiv preprint arXiv:2204.07705.
- Aligning large language models with human: A survey. arXiv preprint arXiv:2307.12966.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837.
- Adaptive budget allocation for parameter-efficient fine-tuning. arXiv preprint arXiv:2303.10512.
- Instruction tuning for large language models: A survey. arXiv preprint arXiv:2308.10792.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.