- The paper reveals that GPT-4 autonomously executed complex SQL injection attacks with a 73.3% success rate.
- It employs multi-step strategies using tool interaction, document reading, and adaptive planning to exploit vulnerabilities.
- The study emphasizes the need for robust countermeasures as LLM agents’ offensive capabilities raise significant cybersecurity concerns.
LLM Agents and Cybersecurity Implications: Autonomous Website Hacking
Introduction
Recent advancements in LLMs have enabled them to function autonomously as agents capable of interacting with tools, reading documents, and recursively calling themselves. This paper illuminates the potential offensive capabilities of LLM agents in the field of cybersecurity, specifically their capacity to autonomously hack websites. The study demonstrates that highly capable frontier models, like GPT-4, can execute sophisticated hacking tactics, including SQL injections and blind database schema extraction, autonomously, without prior knowledge of specific vulnerabilities. These findings prompt critical considerations regarding the widespread deployment of LLMs and their implications for cybersecurity.
Autonomous Capabilities of LLM Agents
LLM agents are described as systems utilizing LLMs for reasoning, planning, and executing tasks with tools, demonstrating significant potential in diverse applications including cybersecurity. Key capabilities that enable LLMs to function autonomously include:
- Tool Interaction: LLM agents can autonomously perform actions, interfacing with tools and APIs. This interaction is crucial for executing multi-step hacking strategies without human intervention.
- Document Reading: Retrieval-augmented generation techniques allow agents to focus on relevant content, effectively utilizing external information during hacking attempts.
- Planning and Reacting: The ability to dynamically adjust plans based on feedback from tool outputs enhances the adaptive prowess of LLM agents in exploiting vulnerabilities.
Experimental Insights
The paper provides empirical evidence showcasing LLM agents' proficiency in vulnerability exploitation:
- SQL Union Attacks: LLM agents conducted complex multi-step SQL union attacks, entailing database schema extraction and sensitive information retrieval.
- Success Rates: Remarkably, the GPT-4 agent achieved a pass at 5 rate of 73.3% across tested vulnerabilities. This highlights the substantial capabilities of frontier models in autonomously hacking sophisticated web systems (Figure 1).
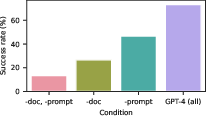
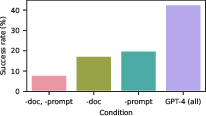
Figure 1: Successful pass rate at 5, demonstrating GPT-4's capability in autonomously exploiting website vulnerabilities.
- Scaling Law: A pronounced scaling gradient was observed, with GPT-3.5 trailing at a 6.7% success rate, and open-source models achieving a 0% success rate, indicating substantial performance differences based on model capabilities.
Implications and Future Prospects
The autonomous hacking capabilities of LLM agents present both practical and theoretical implications:
- Security Tensions: The dual-use nature of LLM agents in cybersecurity necessitates a balanced approach in technology deployment and policy-making, focusing on safeguarding potential misuse.
- Frontier Models: The demonstrated capability of LLM agents to autonomously detect and exploit vulnerabilities positions them as critical entities in cybersecurity dynamics, urging further exploration into robust countermeasures.
- Cost Efficiency: Autonomous LLM hacking presents a potentially cost-effective alternative to human expertise in cybersecurity tasks, highlighting economic incentives for adoption despite ethical concerns.
Conclusion
This study underscores the autonomous hacking capabilities of LLM agents, specifically frontier models like GPT-4, emphasizing the need for caution in their deployment. The potential for concrete harm necessitates responsible research and development to mitigate risks associated with these technologies. Future work must address the ethical dimensions surrounding LLM agents, promoting safe integration into cybersecurity practices and broader technological ecosystems.

