- The paper introduces a contrastive learning method (puCL) for PU data that avoids class prior estimation and improves performance.
- It employs a two-step approach combining contrastive representation learning with pseudo-labeling (puPL) to assign high-quality labels to unlabeled samples.
- Experimental results across benchmarks show up to 2% improvement and strong theoretical guarantees, underscoring the method's practical efficiency.
Understanding Contrastive Representation Learning from Positive Unlabeled (PU) Data
This paper introduces a novel framework for Positive Unlabeled (PU) learning by leveraging contrastive representation learning. The approach is designed to overcome traditional PU learning challenges, especially the need for class prior estimation, and demonstrates improved performance across several benchmark datasets.
Introduction to PU Learning
Positive Unlabeled (PU) learning involves training a binary classifier using a dataset with a few labeled positive samples and a set of unlabeled samples. The absence of labeled negative examples complicates traditional supervised learning approaches. The concept of PU learning is crucial in domains where negative examples are hard to obtain, such as recommendation systems and medical diagnostics. Traditional methods often require an accurate estimate of the class prior, which can be computationally expensive and prone to errors.
Proposed Framework
The paper proposes a two-step approach to PU learning:
- Contrastive Representation Learning (puCL):
- The authors extend the InfoNCE family of contrastive objectives tailored for PU data. They introduce an objective that efficiently leverages weak supervision from labeled positives.
- This approach ensures that the learned feature space fosters semantic similarity among samples while maintaining separability from dissimilar ones. The proposed puCL is unbiased and consistently outperforms both fully unsupervised (ssCL) and naive supervised (sCL-PU) methods in scenarios with limited supervision.
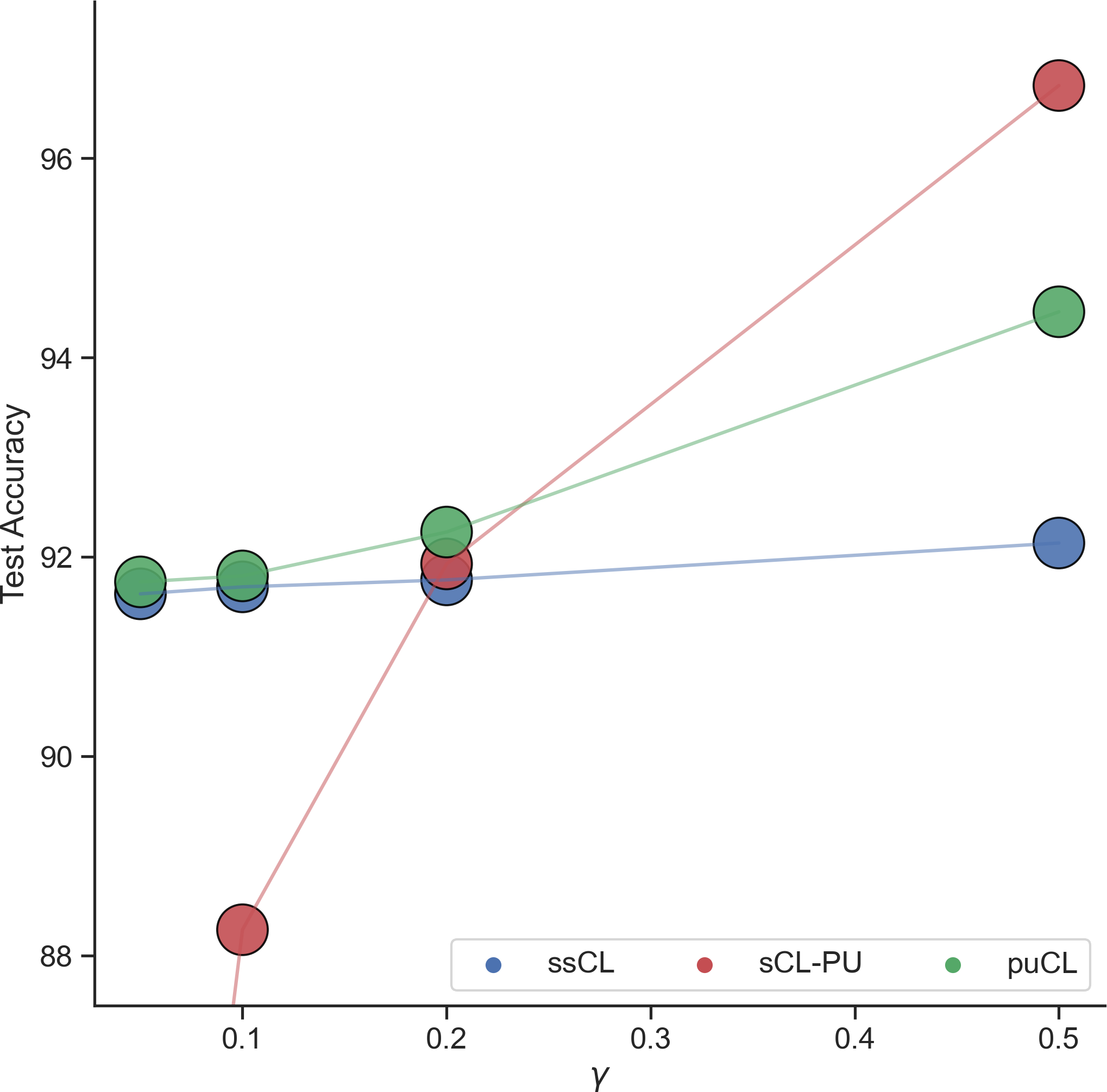
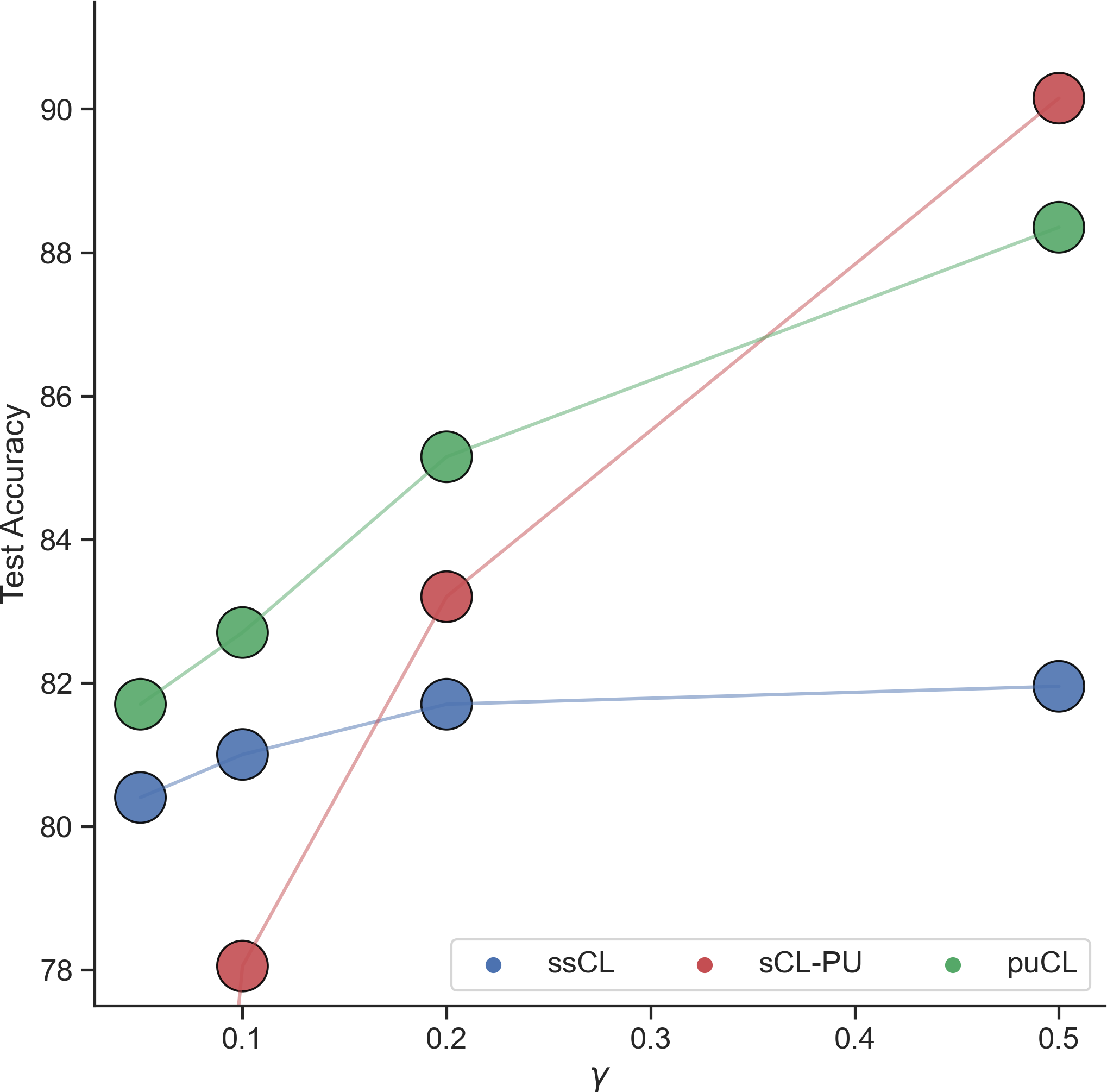
Figure 1: Generalization benefits of incorporating weak supervision in puCL compared to ssCL and sCL-PU.
- Pseudo-labeling Mechanism (puPL):
- Leveraging the geometric properties of the learned representation space, puPL assigns pseudo-labels to unlabeled examples based on clustering techniques similar to k-means++ but initialized with labeled positive samples.
- This approach ensures high-quality pseudo-labels that significantly improve downstream binary classification without relying on class prior knowledge.
Technical Contributions
- Unbiased Estimation: Both puCL and puPL provide unbiased estimates for learning from the PU dataset, avoiding the pitfalls of variance and bias in class prior assumptions.
- Generalization Guarantees: The learned representation space and pseudo-labeling mechanism together offer strong performance even with minimal labeled data, highlighted by theoretical generalization guarantees.
- Implementation Efficiency: The approach circumvents the need for class prior estimation, reducing computational overhead and improving practical deployment scenarios.
Experimental Validation
The authors conduct extensive evaluations across multiple datasets, including standard benchmarks for PU learning and settings involving low supervision. The proposed method, particularly puCL coupled with puPL, consistently outperforms existing state-of-the-art PU learning algorithms, achieving up to 2% improvement. This performance is robust across varying levels of supervision and different dataset priors.
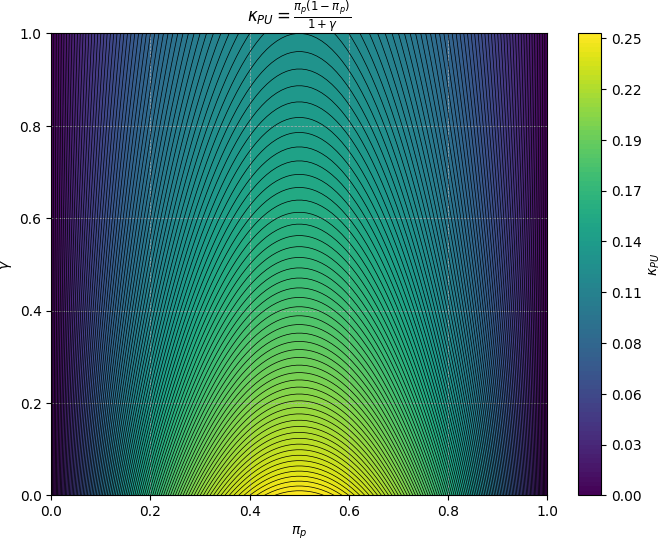
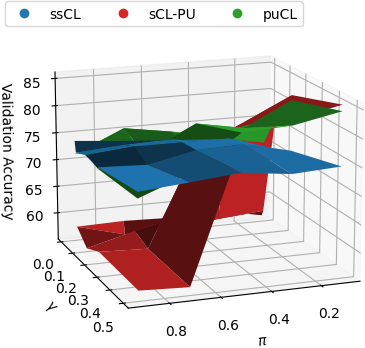
Figure 2: Embedding quality and convergence benefits demonstrated by puPL over traditional PU learning methods.
Conclusion
Overall, the proposed PU learning framework shows significant promise in overcoming existing challenges in the domain, such as dependency on class prior estimation and limited generalization in low-supervision settings. The paper's method demonstrates strong empirical performance and holds valuable implications for future research in PU learning scenarios.
Figure 3: Sensitivity analysis showcasing robustness to varying class prior estimates, emphasizing the practicality of puPL.
The insights and methodologies outlined in this paper suggest directions for further exploration, particularly in extending contrastive learning paradigms to other weakly supervised learning tasks.