When Large Language Models Meet Vector Databases: A Survey
Abstract: This survey explores the synergistic potential of LLMs and Vector Databases (VecDBs), a burgeoning but rapidly evolving research area. With the proliferation of LLMs comes a host of challenges, including hallucinations, outdated knowledge, prohibitive commercial application costs, and memory issues. VecDBs emerge as a compelling solution to these issues by offering an efficient means to store, retrieve, and manage the high-dimensional vector representations intrinsic to LLM operations. Through this nuanced review, we delineate the foundational principles of LLMs and VecDBs and critically analyze their integration's impact on enhancing LLM functionalities. This discourse extends into a discussion on the speculative future developments in this domain, aiming to catalyze further research into optimizing the confluence of LLMs and VecDBs for advanced data handling and knowledge extraction capabilities.
- Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Cm3: A causal masked multimodal model of the internet, 2022.
- Flamingo: a visual language model for few-shot learning, 2022.
- Near-Optimal Hashing Algorithms for Approximate Nearest Neighbor in High Dimensions. Communications of the ACM, 51(1):117–122, 2008.
- Acl 2023 tutorial: Retrieval-based language models and applications. ACL 2023, 2023.
- On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’21, page 610–623, New York, NY, USA, 2021. Association for Computing Machinery.
- Semantic parsing on freebase from question-answer pairs. In Proc. 2013 Conf. on Empirical Methods in Natural Language Processing, pages 1533–1544, 2013.
- Language models are few-shot learners. Advances in Neural Information Processing Systems, 33:1877–1901, 2020.
- Lift yourself up: Retrieval-augmented text generation with self memory, 2023.
- Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113, 2023.
- Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555, 2014.
- Electra: Pre-training text encoders as discriminators rather than generators. arXiv preprint arXiv:2003.10555, 2020.
- Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Measuring the carbon intensity of ai in cloud instances, 2022.
- Variational autoencoder for anti-cancer drug response prediction, 2021.
- Glam: Efficient scaling of language models with mixture-of-experts. In Int. Conf. on Machine Learning, pages 5547–5569. PMLR, 2022.
- Fool me twice: Entailment from wikipedia gamification. arXiv preprint arXiv:2104.04725, 2021.
- Beyond english-centric multilingual machine translation. Journal of Machine Learning Research, 22(107):1–48, 2021.
- Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned, 2022.
- Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies. Transactions of the Association for Computational Linguistics, 9:346–361, 2021.
- A comprehensive survey on vector database: Storage and retrieval technique, challenge, 2023.
- Deep residual learning for image recognition. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, pages 770–778, 2016.
- Deberta: Decoding-enhanced bert with disentangled attention. arXiv preprint arXiv:2006.03654, 2020.
- Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
- Xanh Ho and Anh-Khoa Duong Nguyen et al. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. arXiv preprint arXiv:2011.01060, 2020.
- Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
- A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions, 2023.
- Atlas: Few-shot learning with retrieval augmented language models, 2022.
- Product Quantization for Nearest Neighbor Search. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 33(1):117–128, 2011.
- Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38, 2023.
- Active retrieval augmented generation, 2023.
- Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. arXiv preprint arXiv:1705.03551, 2017.
- Knowledge graph-augmented language models for knowledge-grounded dialogue generation, 2023.
- Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- Generalization through memorization: Nearest neighbor language models, 2020.
- Grounding language models to images for multimodal inputs and outputs. 2023.
- Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:453–466, 2019.
- Cross-lingual language model pretraining. arXiv preprint arXiv:1901.07291, 2019.
- Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942, 2019.
- Deduplicating training data makes language models better, 2022.
- Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461, 2019.
- A survey on fairness in large language models. arXiv preprint arXiv:2308.10149, 2023.
- Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models, 2023.
- A community detection and graph-neural-network-based link prediction approach for scientific literature. Mathematics, 12(3):369, 2024.
- Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 42(4):824–836, 2018.
- When not to trust language models: Investigating effectiveness and limitations of parametric and non-parametric memories. arXiv preprint arXiv:2212.10511, 7, 2022.
- Ret-llm: Towards a general read-write memory for large language models, 2023.
- Fast Approximate Nearest Neighbors with Automatic Algorithm Configuration. VISAPP, 2(331-340):2, 2009.
- Micah Musser. A cost analysis of generative language models and influence operations, 2023.
- Ms marco: A human generated machine reading comprehension dataset. Choice, 2640:660, 2016.
- EASE: Entity-aware contrastive learning of sentence embedding. In Marine Carpuat, Marie-Catherine de Marneffe, and Ivan Vladimir Meza Ruiz, editors, Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3870–3885, Seattle, United States, July 2022. Association for Computational Linguistics.
- Entity cloze by date: What LMs know about unseen entities. In Marine Carpuat, Marie-Catherine de Marneffe, and Ivan Vladimir Meza Ruiz, editors, Findings of the Association for Computational Linguistics: NAACL 2022, pages 693–702, Seattle, United States, July 2022. Association for Computational Linguistics.
- Survey of vector database management systems. arXiv preprint arXiv:2310.14021, 2023.
- The refinedweb dataset for falcon llm: Outperforming curated corpora with web data, and web data only, 2023.
- Language models are unsupervised multitask learners. OpenAI Blog, 1(8):9, 2019.
- Scaling language models: Methods, analysis and insights from training gopher. arXiv preprint arXiv:2112.11446, 2021.
- Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551, 2020.
- Squad: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250, 2016.
- In-context retrieval-augmented language models. Transactions of the Association for Computational Linguistics, 11:1316–1331, 2023.
- Rylan Schaeffer. Pretraining on the test set is all you need. arXiv preprint arXiv:2309.08632, 2023.
- Convolutional lstm network: A machine learning approach for precipitation nowcasting. Advances in neural information processing systems, 28, 2015.
- Llasm: Large language and speech model, 2023.
- Using deepspeed and megatron to train megatron-turing nlg 530b, a large-scale generative language model. arXiv preprint arXiv:2201.11990, 2022.
- Energy and policy considerations for deep learning in nlp. arXiv preprint arXiv:1906.02243, 2019.
- Yolo-logo: A transformer-based yolo segmentation model for breast mass detection and segmentation in digital mammograms. Computer Methods and Programs in Biomedicine, 221:106903, 2022.
- Commonsenseqa: A question answering challenge targeting commonsense knowledge. arXiv preprint arXiv:1811.00937, 2018.
- Quality and efficiency in high dimensional nearest neighbor search. In Proceedings of the International Conference on Management of Data (SIGMOD), SIGMOD ’09, page 563–576, New York, NY, USA, 2009. Association for Computing Machinery.
- Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models. arXiv preprint arXiv:2104.08663, 2021.
- Romal Thoppilan and Daniel De Freitas et al. Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239, 2022.
- Fever: a large-scale dataset for fact extraction and verification. arXiv preprint arXiv:1803.05355, 2018.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Musique: Multihop questions via single-hop question composition. Transactions of the Association for Computational Linguistics, 10:539–554, 2022.
- Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Nationality bias in text generation, 2023.
- Milvus: A purpose-built vector data management system. In Proc. of the 2021 Int. Conf. on Management of Data, pages 2614–2627, 2021.
- Must: An effective and scalable framework for multimodal search of target modality. arXiv preprint arXiv:2312.06397, 2023.
- Emergent abilities of large language models. arXiv preprint arXiv:2206.07682, 2022.
- BigScience Workshop and Teven Le Scao et al. Bloom: A 176b-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100, 2022.
- Bloomberggpt: A large language model for finance. arXiv preprint arXiv:2303.17564, 2023.
- Wav2seq: Pre-training speech-to-text encoder-decoder models using pseudo languages, 2022.
- C-pack: Packaged resources to advance general chinese embedding. arXiv preprint arXiv:2309.07597, 2023.
- mt5: A massively multilingual pre-trained text-to-text transformer. arXiv preprint arXiv:2010.11934, 2020.
- Hotpotqa: A dataset for diverse, explainable multi-hop question answering. arXiv preprint arXiv:1809.09600, 2018.
- Vid2seq: Large-scale pretraining of a visual language model for dense video captioning, 2023.
- A survey on large language model (llm) security and privacy: The good, the bad, and the ugly, 2024.
- How transferable are features in deep neural networks? Advances in Neural Information Processing Systems, 27, 2014.
- Generate rather than retrieve: Large language models are strong context generators, 2023.
- Big bird: Transformers for longer sequences. Advances in Neural Information Processing Systems, 33:17283–17297, 2020.
- Recurrent neural network regularization. arXiv preprint arXiv:1409.2329, 2014.
- Glm-130b: An open bilingual pre-trained model. arXiv preprint arXiv:2210.02414, 2022.
- Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
- Yi Zhang and Zhongyang Yu et al. Long-term memory for large language models through topic-based vector database. In 2023 International Conference on Asian Language Processing (IALP), pages 258–264, 2023.
- Text-to-image diffusion models in generative ai: A survey, 2023.
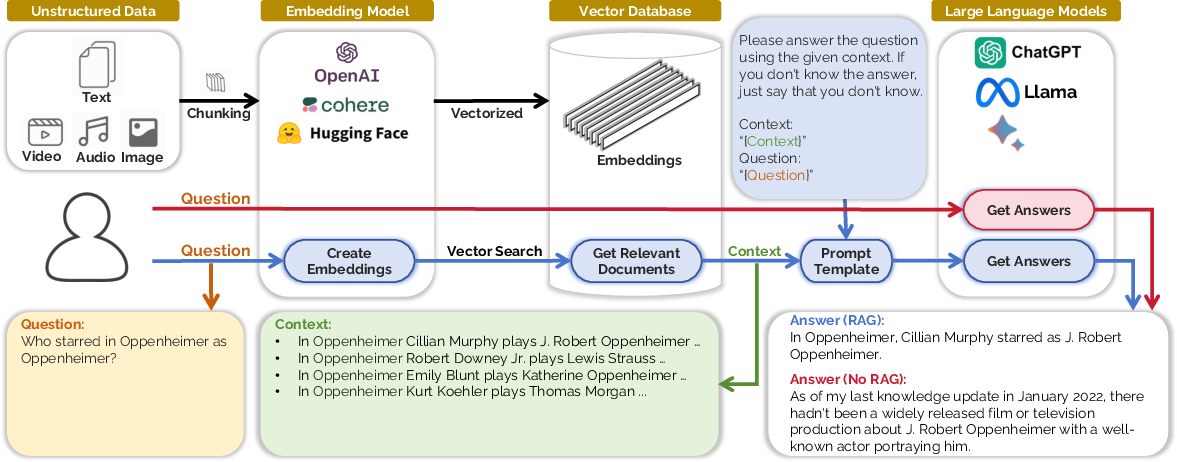
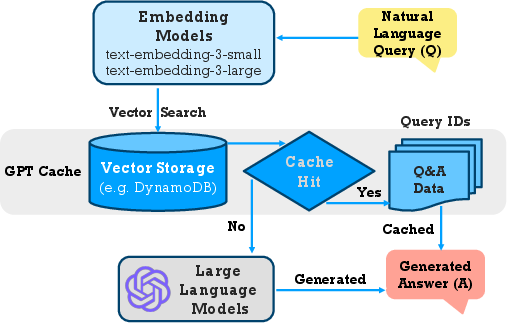
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

