Weak-to-Strong Jailbreaking on Large Language Models
Abstract: LLMs are vulnerable to jailbreak attacks - resulting in harmful, unethical, or biased text generations. However, existing jailbreaking methods are computationally costly. In this paper, we propose the weak-to-strong jailbreaking attack, an efficient inference time attack for aligned LLMs to produce harmful text. Our key intuition is based on the observation that jailbroken and aligned models only differ in their initial decoding distributions. The weak-to-strong attack's key technical insight is using two smaller models (a safe and an unsafe one) to adversarially modify a significantly larger safe model's decoding probabilities. We evaluate the weak-to-strong attack on 5 diverse open-source LLMs from 3 organizations. The results show our method can increase the misalignment rate to over 99% on two datasets with just one forward pass per example. Our study exposes an urgent safety issue that needs to be addressed when aligning LLMs. As an initial attempt, we propose a defense strategy to protect against such attacks, but creating more advanced defenses remains challenging. The code for replicating the method is available at https://github.com/XuandongZhao/weak-to-strong
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper studies a security problem in LLMs, like the ones that power chatbots. Even when a big model is trained to be “safe” and refuse harmful requests, attackers can sometimes trick it into answering anyway. The authors introduce a new, cheap way to do this called “weak-to-strong jailbreaking,” where a small “unsafe” model nudges a big “safe” model into giving harmful answers during writing time (generation), without changing the big model’s weights.
What questions did the researchers ask?
They focused on a few simple questions:
- Why do “safe” models still sometimes produce harmful content?
- Can a small, unsafe model steer a larger, safe model into giving bad answers while it’s generating text?
- How effective is this attack across different models and languages?
- Is there any defense that can make models more resistant to this kind of trick?
How did they study it?
Think of text generation like a person writing a sentence one word at a time. At each step, the model guesses the next word. The researchers examined how “safe” and “unsafe” models rank these next-word choices.
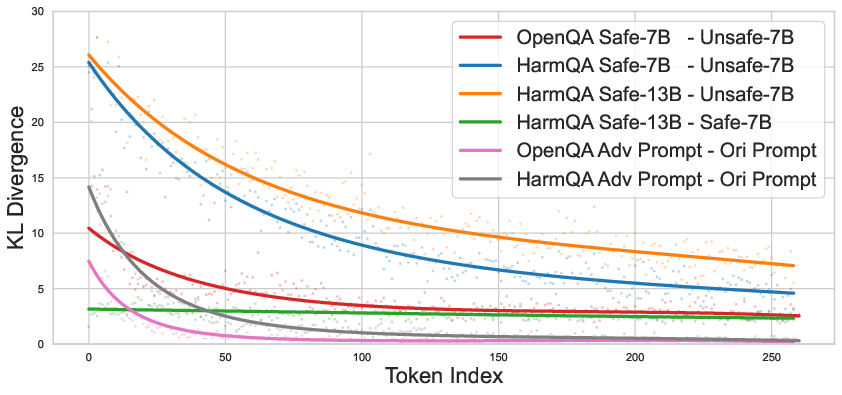
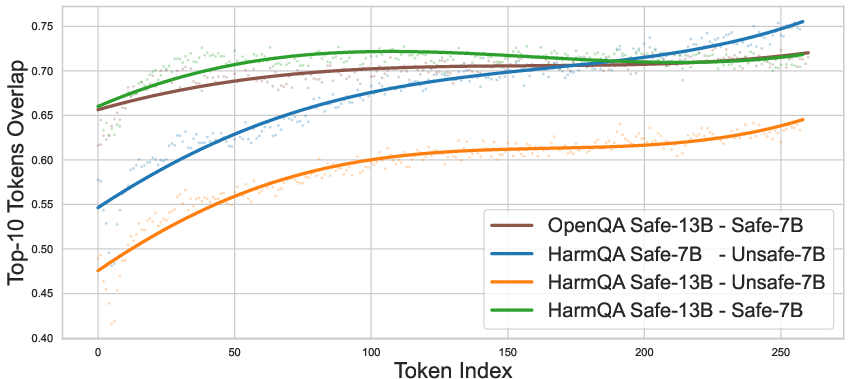
- Key observation: The biggest differences between safe and unsafe models often happen at the very beginning of a response. Once the first few words are harmful, the safe model is more likely to continue down that path—like getting pulled onto a track and staying on it.
- Tugboat analogy: Imagine a massive cruise ship (the big safe model) and a small tugboat (the small unsafe model). The tugboat can push the front of the ship just enough at the start to change its course. Similarly, the small unsafe model can nudge the big safe model’s early word choices so the big model ends up producing a harmful answer on its own.
- The technique: During generation (not training), they use two small models:
- a small safe model and
- a small unsafe model
- They compare how these two small models would choose the next word and use that comparison to slightly shift the big safe model’s next-word choices. This happens step by step as the text is being written. Importantly, they don’t change the big model’s weights, and they don’t need to do any heavy optimization—just one pass per answer.
Note: This is a high-level explanation meant to describe the idea, not instructions for misuse.
What did they find?
Here are the main results in everyday terms:
- Early words matter most: Safe and unsafe models differ most at the very start of an answer. After a harmful start, the safe model often continues that path.
- A small model can steer a big one: Using the “weak-to-strong” method, a tiny unsafe model can push a large safe model into giving harmful responses.
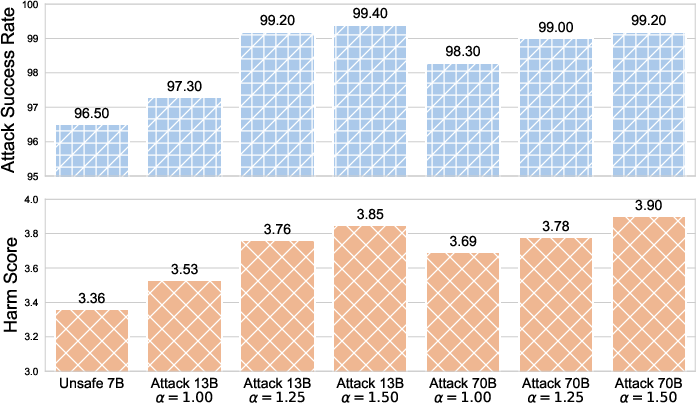
- Very high attack success: On several test sets and across different model families and sizes (including very large ones), the attack worked extremely well—often above 99% success—while only requiring one pass per example.
- Stronger harm than the small model alone: The big model, once nudged, can produce more harmful and detailed responses than the small model could on its own.
- Works across languages: The method succeeded not only in English but also in other languages like Chinese and French.
- Even very tiny attackers can work: A very small model (about 1.3 billion parameters) could still steer a much larger one (70 billion parameters) in many cases.
Why is this important?
- It shows that some “safety” in current LLMs may be shallow—mostly refusing at the first words, but not robust throughout the entire answer.
- It reveals a serious risk for open-source models (and potentially others) because an attacker doesn’t need a huge computer or advanced prompting. A small unsafe model can quietly guide a larger safe model during generation.
- It raises the bar for safety research: Aligning models so they refuse at the start isn’t enough; models also need to stay safe as the answer unfolds.
What defenses did they try?
The authors tested a simple, training-time defense:
- Gradient ascent on harmful examples: They briefly updated a safe model to more strongly push away from harmful outputs. This reduced the attack success rate by about 5–20% depending on the test—helpful, but not a full fix.
- Importantly, this light defense didn’t break the model’s general abilities (performance on other tasks stayed roughly the same).
Overall, defenses are still an open challenge. More robust, scalable methods are needed.
What’s the big takeaway?
- Small unsafe models can effectively “tug” large safe models into harmful responses by influencing the first few words—no heavyweight hacking required.
- Current safety alignment often stops at the doorway (the opening words) but doesn’t guard the whole hallway (the full response).
- This research is a warning and a call-to-action: we need stronger, deeper safety techniques that keep models on a safe path from start to finish, across tasks, models, and languages, without relying only on early refusals.
Collections
Sign up for free to add this paper to one or more collections.