Fast Kronecker Matrix-Matrix Multiplication on GPUs
Abstract: Kronecker Matrix-Matrix Multiplication (Kron-Matmul) is the multiplication of a matrix with the Kronecker Product of several smaller matrices. Kron-Matmul is a core operation for many scientific and machine learning computations. State-of-the-art Kron-Matmul implementations utilize existing tensor algebra operations, such as matrix multiplication, transpose, and tensor matrix multiplication. However, this design choice prevents several Kron-Matmul specific optimizations, thus, leaving significant performance on the table. To address this issue, we present FastKron, an efficient technique for Kron-Matmul on single and multiple GPUs. FastKron is independent of linear algebra operations enabling several new optimizations for Kron-Matmul. Thus, it performs up to 40.7x and 7.85x faster than existing implementations on 1 and 16 GPUs respectively.
- Accessed: 2022-07-30. NVIDIA cuBLAS. https://developer.nvidia.com/cublas.
- Accessed: 2023-07-30. NVIDIA cuTLASS: CUDA Templates for Linear Algebra Subroutines. https://github.com/NVIDIA/cutlass.
- Accessed: 2023-07-30. NVIDIA NCCL: Optimized primitives for collective multi-GPU communication. https://github.com/NVIDIA/nccl.
- Accessed: 2023-07-30. UCI ML Dataset. https://archive.ics.uci.edu/datasets.
- KBLAS: An Optimized Library for Dense Matrix-Vector Multiplication on GPU Accelerators. ACM Trans. Math. Softw., Article 18 (2016). https://doi.org/10.1145/2818311
- PyKronecker: A Python Library for the Efficient Manipulation of Kronecker Products and Related Structures. Journal of Open Source Software 8 (2023). https://doi.org/10.21105/joss.04900
- Multi-task Gaussian Process Prediction. In Advances in Neural Information Processing Systems, J. Platt, D. Koller, Y. Singer, and S. Roweis (Eds.). Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2007/file/66368270ffd51418ec58bd793f2d9b1b-Paper.pdf
- Lynn Elliot Cannon. 1969. A Cellular Computer to Implement the Kalman Filter Algorithm. Ph. D. Dissertation. USA.
- Rong Chen Chencheng Cai and Han Xiao. 2023. Hybrid Kronecker Product Decomposition and Approximation. Journal of Computational and Graphical Statistics 32 (2023). https://doi.org/10.1080/10618600.2022.2134873
- Marc Davio. 1981. Kronecker products and shuffle algebra. IEEE Trans. Comput. C-30 (1981). https://doi.org/10.1109/TC.1981.6312174
- Tuǧrul Dayar and M. Can Orhan. 2015. On Vector-Kronecker Product Multiplication with Rectangular Factors. SIAM Journal on Scientific Computing 37, 5 (2015). https://doi.org/10.1137/140980326
- Communication-Optimal Parallel Recursive Rectangular Matrix Multiplication. In 2013 IEEE 27th International Symposium on Parallel and Distributed Processing. https://doi.org/10.1109/IPDPS.2013.80
- Distributed Halide. In Proceedings of the 21st ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. https://doi.org/10.1145/2851141.2851157
- Product Kernel Interpolation for Scalable Gaussian Processes. In Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics (Proceedings of Machine Learning Research, Vol. 84). PMLR. https://proceedings.mlr.press/v84/gardner18a.html
- GPyTorch: Blackbox Matrix-Matrix Gaussian Process Inference with GPU Acceleration. In Proceedings of the 32nd International Conference on Neural Information Processing Systems (Montréal, Canada) (NIPS’18).
- dCUDA: Hardware Supported Overlap of Computation and Communication. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. https://doi.org/10.1109/SC.2016.51
- Mathematical modeling of multiple pathways in colorectal carcinogenesis using dynamical systems with Kronecker structure. PLOS Computational Biology (2021). https://doi.org/10.1371/journal.pcbi.1008970
- Efficient dense matrix-vector multiplication on GPU. Concurrency and Computation: Practice and Experience 30 (2018). https://doi.org/10.1002/cpe.4705
- Antti-Pekka Hynninen and Dmitry I. Lyakh. 2017. cuTT: A High-Performance Tensor Transpose Library for CUDA Compatible GPUs. CoRR abs/1705.01598 (2017). arXiv:1705.01598
- Abhinav Jangda. 2023. (Artifact) Fast Kronecker Matrix Multiplication on GPUs. (12 2023). https://doi.org/10.6084/m9.figshare.24803229.v1
- Breaking the Computation and Communication Abstraction Barrier in Distributed Machine Learning Workloads. In Proceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (Lausanne, Switzerland) (ASPLOS ’22). https://doi.org/10.1145/3503222.3507778
- Kronecker Recurrent Units. CoRR abs/1705.10142 (2017). http://arxiv.org/abs/1705.10142
- Optimizing Tensor Contractions in CCSD(T) for Efficient Execution on GPUs. In Proceedings of the 2018 International Conference on Supercomputing (Beijing, China) (ICS ’18). https://doi.org/10.1145/3205289.3205296
- A Code Generator for High-Performance Tensor Contractions on GPUs. In 2019 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). https://doi.org/10.1109/CGO.2019.8661182
- Red-Blue Pebbling Revisited: Near Optimal Parallel Matrix-Matrix Multiplication. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (Denver, Colorado) (SC ’19). https://doi.org/10.1145/3295500.3356181
- Amy N. Langville and William J. Stewart. 2004. The Kronecker Product and Stochastic Automata Networks. J. Comput. Appl. Math. 167, 2 (jun 2004). https://doi.org/10.1016/j.cam.2003.10.010
- Generalized Cannon’s Algorithm for Parallel Matrix Multiplication. In Proceedings of the 11th International Conference on Supercomputing (Vienna, Austria) (ICS ’97). https://doi.org/10.1145/263580.263591
- Kronecker Graphs: An Approach to Modeling Networks. J. Mach. Learn. Res. 11 (2010).
- Dmitry Lyakh. 2015. An efficient tensor transpose algorithm for multicore CPU, Intel Xeon Phi, and NVidia Tesla GPU. Computer Physics Communications 189 (2015). https://doi.org/10.1016/j.cpc.2014.12.013
- Optimizing tensor contraction expressions for hybrid CPU-GPU execution. Cluster Computing 16 (Mar 2013). https://doi.org/10.1007/s10586-011-0179-2
- Devin A. Matthews. 2018. High-Performance Tensor Contraction without Transposition. SIAM Journal on Scientific Computing 40 (2018). https://doi.org/10.1137/16M108968X
- Generating Efficient Tensor Contractions for GPUs. In 2015 44th International Conference on Parallel Processing. https://doi.org/10.1109/ICPP.2015.106
- Predictive Data Locality Optimization for Higher-Order Tensor Computations. In Proceedings of the 5th ACM SIGPLAN International Symposium on Machine Programming (Virtual, Canada) (MAPS 2021). https://doi.org/10.1145/3460945.3464955
- Constant-Time Predictive Distributions for Gaussian Processes. In Proceedings of the 35th International Conference on Machine Learning (Proceedings of Machine Learning Research). PMLR. https://proceedings.mlr.press/v80/pleiss18a.html
- A Communication-Optimal Framework for Contracting Distributed Tensors. In SC ’14: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. https://doi.org/10.1109/SC.2014.36
- Carl Edward Rasmussen and Christopher K. I. Williams. 2005. Gaussian Processes for Machine Learning. The MIT Press. https://doi.org/10.7551/mitpress/3206.001.0001
- Carl Edward Rasmussen and Christopher K. I. Williams. 2006. Gaussian processes for machine learning. MIT Press.
- TSM2X: High-performance tall-and-skinny matrix-matrix multiplication on GPUs. J. Parallel and Distrib. Comput. 151 (2021). https://doi.org/10.1016/j.jpdc.2021.02.013
- Tensor Contractions with Extended BLAS Kernels on CPU and GPU. In 2016 IEEE 23rd International Conference on High Performance Computing (HiPC). https://doi.org/10.1109/HiPC.2016.031
- Edgar Solomonik and James Demmel. 2011. Communication-Optimal Parallel 2.5D Matrix Multiplication and LU Factorization Algorithms. In Euro-Par 2011 Parallel Processing. https://doi.org/10.1007/978-3-642-23397-5_10
- A Massively Parallel Tensor Contraction Framework for Coupled-Cluster Computations. J. Parallel Distrib. Comput. 74 (2014). https://doi.org/10.1016/j.jpdc.2014.06.002
- Paul Springer and Paolo Bientinesi. 2018. Design of a High-Performance GEMM-like Tensor-Tensor Multiplication. ACM Trans. Math. Softw. 44 (2018). https://doi.org/10.1145/3157733
- TTC: A Tensor Transposition Compiler for Multiple Architectures. In Proceedings of the 3rd ACM SIGPLAN International Workshop on Libraries, Languages, and Compilers for Array Programming (Santa Barbara, CA, USA). https://doi.org/10.1145/2935323.2935328
- HPTT: A High-Performance Tensor Transposition C++ Library. In Proceedings of the 4th ACM SIGPLAN International Workshop on Libraries, Languages, and Compilers for Array Programming (Barcelona, Spain) (ARRAY 2017). https://doi.org/10.1145/3091966.3091968
- Doping: A technique for Extreme Compression of LSTM Models using Sparse Structured Additive Matrices. In Proceedings of Machine Learning and Systems 2021, MLSys 2021, Alex Smola, Alex Dimakis, and Ion Stoica (Eds.). mlsys.org.
- R. A. Van De Geijn and J. Watts. 1997. SUMMA: scalable universal matrix multiplication algorithm. Concurrency: Practice and Experience 9 (1997). https://doi.org/10.1002/(SICI)1096-9128(199704)9:4<255::AID-CPE250>3.0.CO;2-2
- Field G. Van Zee and Robert A. van de Geijn. 2015. BLIS: A Framework for Rapidly Instantiating BLAS Functionality. ACM Trans. Math. Software 41 (2015). https://doi.acm.org/10.1145/2764454
- Tensor Comprehensions: Framework-Agnostic High-Performance Machine Learning Abstractions. arXiv:1802.04730 [cs.PL]
- TTLG - An Efficient Tensor Transposition Library for GPUs. In 2018 IEEE International Parallel and Distributed Processing Symposium (IPDPS). https://doi.org/10.1109/IPDPS.2018.00067
- Generalized vec trick for fast learning of pairwise kernel models. Machine Learning 111 (2022). https://doi.org/10.1007/s10994-021-06127-y
- Thoughts on Massively Scalable Gaussian Processes. arXiv:1511.01870 [cs.LG]
- Andrew Gordon Wilson and Hannes Nickisch. 2015. Kernel Interpolation for Scalable Structured Gaussian Processes (KISS-GP). In Proceedings of the 32nd International Conference on International Conference on Machine Learning - Volume 37 (Lille, France) (ICML’15).
- DISTAL: The Distributed Tensor Algebra Compiler. In Proceedings of the 43rd ACM SIGPLAN International Conference on Programming Language Design and Implementation (San Diego, CA, USA) (PLDI 2022). https://doi.org/10.1145/3519939.3523437
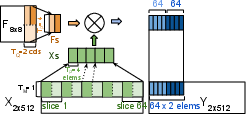
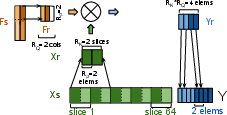
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

