- The paper introduces extensible tokenization to extend LLM context limits without the overhead of traditional fine-tuning.
- It employs a two-stream auto-regression process and a scaling factor to compress token embeddings efficiently.
- Experimental evaluations on datasets like PG19 and Books3 demonstrate improved performance, faster inference, and reduced GPU memory usage.
Extensible Tokenization for Scaling Contexts in LLMs
The paper "Flexibly Scaling LLMs Contexts Through Extensible Tokenization" introduces Extensible Tokenization as a method to extend the context length of LLMs without the traditional overheads associated with fine-tuning. The authors propose a novel approach involving the transformation of raw token embeddings into compact extensible embeddings, enabling LLMs to perceive more information within a fixed context window. This method is positioned as both flexible and compatible, allowing for the integration as a "drop-in component" into existing LLM architectures.
Motivation and Introduction
LLMs face inherent limitations due to constrained context windows that restrict the amount of input data they can efficiently process. While fine-tuning provides a mechanism to extend these windows, it incurs significant computational costs and risks degrading performance on tasks requiring shorter context lengths. Existing methods like sparse attention and stream processing approach this problem differently but still face issues such as hardware incompatibility and information loss.
Extensible Tokenization addresses these issues by increasing the information density of input embeddings, allowing LLMs to effectively manage longer contexts without altering the original model architecture.
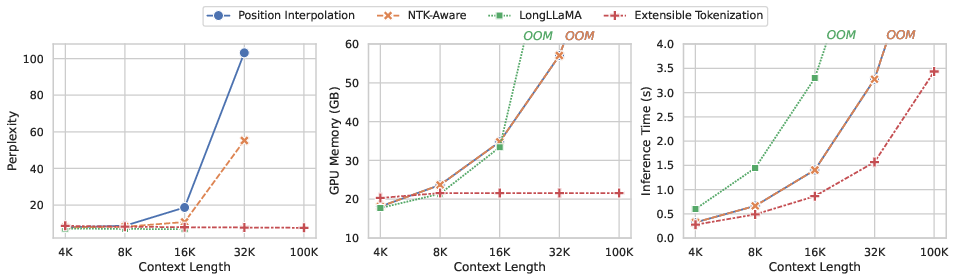
Figure 1: Comparison between Extensible Tokenization and other context extension methods.
Extensible Tokenization Mechanism
Framework Overview
The process begins by chunking input data into equal-sized sub-sequences. Each sub-sequence is transformed into extensible embeddings through a separate pre-trained LLM, termed the extensible tokenizer. The scaling factor k determines the compression rate, influencing the number of extensible embeddings generated per chunk.
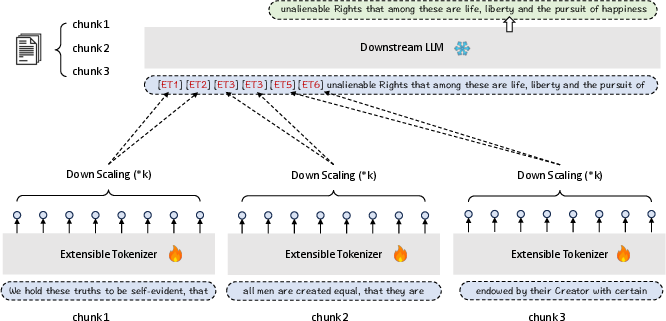
Figure 2: Extensible Tokenization transforms raw input data into extensible embeddings, predicting new tokens based on these compact representations.
Extensible Embedding and Two-Stream AR
The raw token embeddings are identified as sparse in information. To enhance their representational capacity, the authors employ a down-scaling strategy, which is simple yet effective, involving the last embedding in every k steps being selected. For training, a two-stream auto-regression (AR) process is used to optimize sample efficiency, reinforcing the informative nature of extensible embeddings by predicting the next tokens based on previous extensible embeddings and raw tokens.
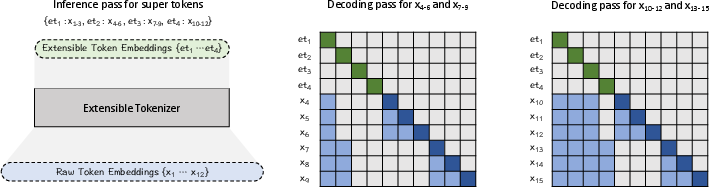
Figure 3: Two-Stream AR with an initial pass transforming tokens into extensible embeddings, followed by token prediction using these embeddings.
Experimental Evaluation
The paper's empirical evaluations underscore the efficacy of Extensible Tokenization in extending context lengths. Evaluations on datasets such as PG19 and Books3 reveal superior performance in language modeling tasks. Notably, the extensible tokenizer tested with varying scaling factors demonstrates performance advantages over conventional fine-tuning methods and baseline models without fine-tuning.
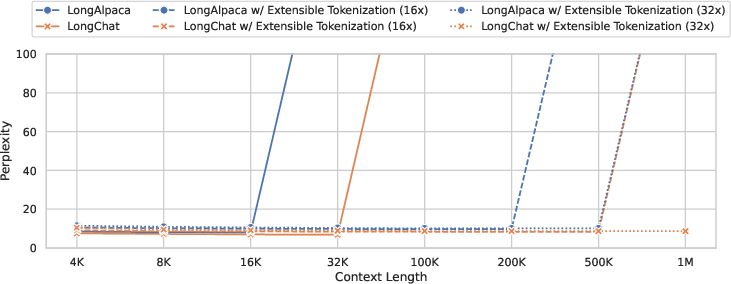
Figure 4: Extensible tokenizer's compatibility observed with LongAlpaca and LongChat, showing substantial context length scaling.
Practical Implications and Efficiency
The method notably allows for scaling factors to be dynamically adjusted at inference time, providing flexible capacity to handle diverse context lengths. As a plug-and-play module, the extensible tokenizer shows compatibility not only with the base LLM model but also with its fine-tuned variants like LongAlpaca and LongChat.
Efficiency metrics indicate Extensible Tokenization optimizes both GPU memory usage and inference time, as the preprocessing of extensible embeddings can significantly reduce computational demands during inference.
Conclusion
The research introduces Extensible Tokenization as a strategic innovation for extending LLM context capacities efficiently and flexibly. Through comprehensive evaluations, the method proves to preserve, or even enhance, task performance while maintaining cost-effectiveness and compatibility across model variants. Further research may explore its integration with other context scaling methods to enhance system effectiveness, highlighting potential future directions in LLM scalability and efficiency in AI applications.