Collaborating Foundation Models for Domain Generalized Semantic Segmentation
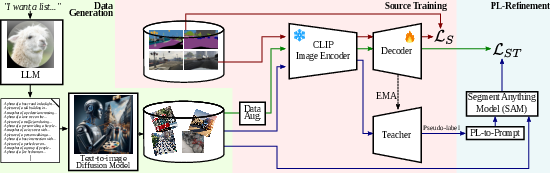
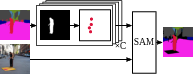
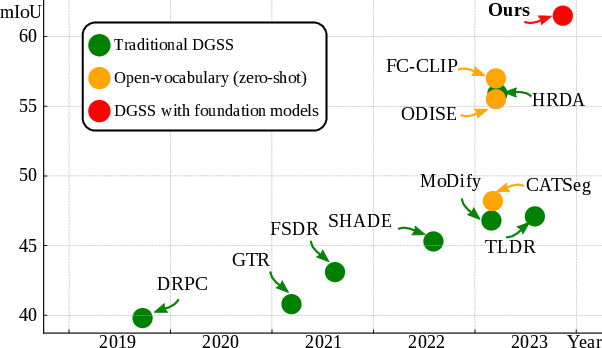
Abstract: Domain Generalized Semantic Segmentation (DGSS) deals with training a model on a labeled source domain with the aim of generalizing to unseen domains during inference. Existing DGSS methods typically effectuate robust features by means of Domain Randomization (DR). Such an approach is often limited as it can only account for style diversification and not content. In this work, we take an orthogonal approach to DGSS and propose to use an assembly of CoLlaborative FOUndation models for Domain Generalized Semantic Segmentation (CLOUDS). In detail, CLOUDS is a framework that integrates FMs of various kinds: (i) CLIP backbone for its robust feature representation, (ii) generative models to diversify the content, thereby covering various modes of the possible target distribution, and (iii) Segment Anything Model (SAM) for iteratively refining the predictions of the segmentation model. Extensive experiments show that our CLOUDS excels in adapting from synthetic to real DGSS benchmarks and under varying weather conditions, notably outperforming prior methods by 5.6% and 6.7% on averaged miou, respectively. The code is available at : https://github.com/yasserben/CLOUDS
- On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021.
- Instructpix2pix: Learning to follow image editing instructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18392–18402, 2023.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Coco-stuff: Thing and stuff classes in context. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1209–1218, 2018.
- Semantic segment anything. https://github.com/fudan-zvg/Semantic-Segment-Anything, 2023.
- Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE TPAMI, (4):834–848, 2017.
- Per-pixel classification is not all you need for semantic segmentation. Advances in Neural Information Processing Systems, 34:17864–17875, 2021.
- Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1290–1299, 2022.
- Promptstyler: Prompt-driven style generation for source-free domain generalization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15702–15712, 2023a.
- Cat-seg: Cost aggregation for open-vocabulary semantic segmentation. arXiv preprint arXiv:2303.11797, 2023b.
- Robustnet: Improving domain generalization in urban-scene segmentation via instance selective whitening. In CVPR, pages 11580–11590, 2021.
- The cityscapes dataset for semantic urban scene understanding. In CVPR, pages 3213–3223, 2016.
- Generative adversarial networks: An overview. IEEE signal processing magazine, 35(1):53–65, 2018.
- Maskclip: Masked self-distillation advances contrastive language-image pretraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10995–11005, 2023.
- An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- Poda: Prompt-driven zero-shot domain adaptation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 18623–18633, 2023.
- Deep learning universal crater detection using segment anything model (sam). arXiv preprint arXiv:2304.07764, 2023.
- Prompting diffusion representations for cross-domain semantic segmentation. arXiv preprint arXiv:2307.02138, 2023.
- Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- Accuracy of segment-anything model (sam) in medical image segmentation tasks. arXiv preprint arXiv:2304.09324, 2023.
- Percolation and cluster distribution. i. cluster multiple labeling technique and critical concentration algorithm. Physical Review B, 14:3438–3445, 1976.
- Daformer: Improving network architectures and training strategies for domain-adaptive semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9924–9935, 2022a.
- Hrda: Context-aware high-resolution domain-adaptive semantic segmentation. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXX, pages 372–391. Springer, 2022b.
- Domain adaptive and generalizable network architectures and training strategies for semantic image segmentation. T-PAMI, 2023.
- Fsdr: Frequency space domain randomization for domain generalization. In CVPR, pages 6891–6902, 2021.
- Iterative normalization: Beyond standardization towards efficient whitening. In CVPR, pages 4874–4883, 2019.
- Openclip. Zenodo, 4:5, 2021.
- Scaling up visual and vision-language representation learning with noisy text supervision. In International conference on machine learning, pages 4904–4916. PMLR, 2021.
- Domain generalization via balancing training difficulty and model capability. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 18993–19003, 2023.
- Diffusion models for zero-shot open-vocabulary segmentation. arXiv preprint arXiv:2306.09316, 2023.
- Texture learning domain randomization for domain generalized segmentation. arXiv preprint arXiv:2303.11546, 2023.
- A method for stochastic optimization. In International conference on learning representations (ICLR), page 6. San Diego, California;, 2015.
- Segment anything. arXiv preprint arXiv:2304.02643, 2023.
- Clipstyler: Image style transfer with a single text condition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18062–18071, 2022.
- Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
- Semantic-sam: Segment and recognize anything at any granularity. arXiv preprint arXiv:2307.04767, 2023.
- Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014.
- Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2117–2125, 2017.
- Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499, 2023.
- A convnet for the 2020s. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11976–11986, 2022.
- Taking a closer look at domain shift: Category-level adversaries for semantics consistent domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2507–2516, 2019.
- Segment anything in medical images. arXiv preprint arXiv:2304.12306, 2023.
- Verbs in action: Improving verb understanding in video-language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15579–15591, 2023.
- Few-shot adversarial domain adaptation. Advances in neural information processing systems, 30, 2017.
- Domain generalization via invariant feature representation. In International conference on machine learning, pages 10–18. PMLR, 2013.
- The mapillary vistas dataset for semantic understanding of street scenes. In ICCV, pages 4990–4999, 2017.
- Two at once: Enhancing learning and generalization capacities via ibn-net. In Proceedings of the European Conference on Computer Vision (ECCV), pages 464–479, 2018.
- Switchable whitening for deep representation learning. In ICCV, pages 1863–1871, 2019.
- Global and local texture randomization for synthetic-to-real semantic segmentation. IEEE TIP, pages 6594–6608, 2021.
- Semantic-aware domain generalized segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2594–2605, 2022.
- What does a platypus look like? generating customized prompts for zero-shot image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15691–15701, 2023.
- Learning to learn single domain generalization. In CVPR, pages 12556–12565, 2020.
- Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022.
- Playing for data: Ground truth from computer games. In ECCV, pages 102–118. Springer, 2016.
- Compvis/stable-diffusion-v1-4. https://huggingface.co/CompVis/stable-diffusion-v1-4, 2023. Accessed on March 20, 2023.
- High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022.
- The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In CVPR, pages 3234–3243, 2016.
- Adapting visual category models to new domains. In Computer Vision–ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Crete, Greece, September 5-11, 2010, Proceedings, Part IV 11, pages 213–226. Springer, 2010.
- Acdc: The adverse conditions dataset with correspondences for semantic driving scene understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10765–10775, 2021.
- Fake it till you make it: Learning transferable representations from synthetic imagenet clones. In CVPR 2023–IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023.
- Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in Neural Information Processing Systems, 35:25278–25294, 2022.
- Selfnorm and crossnorm for out-of-distribution robustness. 2020.
- Unbiased look at dataset bias. In CVPR 2011, pages 1521–1528. IEEE, 2011.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Generalizing to unseen domains via adversarial data augmentation. Advances in neural information processing systems, 31, 2018.
- Continual adaptation of visual representations via domain randomization and meta-learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4443–4453, 2021.
- Deep high-resolution representation learning for visual recognition. IEEE transactions on pattern analysis and machine intelligence, 43(10):3349–3364, 2020.
- Medical sam adapter: Adapting segment anything model for medical image segmentation. arXiv preprint arXiv:2304.12620, 2023.
- SegFormer: Simple and efficient design for semantic segmentation with transformers. NeurIPS, pages 12077–12090, 2021.
- Open-vocabulary panoptic segmentation with text-to-image diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2955–2966, 2023.
- A fourier-based framework for domain generalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14383–14392, 2021.
- Language in a bottle: Language model guided concept bottlenecks for interpretable image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19187–19197, 2023.
- Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In CVPR, pages 2636–2645, 2020.
- Convolutions die hard: Open-vocabulary segmentation with single frozen convolutional clip. arXiv preprint arXiv:2308.02487, 2023.
- Domain randomization and pyramid consistency: Simulation-to-real generalization without accessing target domain data. In ICCV, pages 2100–2110, 2019.
- The unreasonable effectiveness of large language-vision models for source-free video domain adaptation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10307–10317, 2023.
- Prototypical pseudo label denoising and target structure learning for domain adaptive semantic segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12414–12424, 2021.
- Source-free open compound domain adaptation in semantic segmentation. IEEE Transactions on Circuits and Systems for Video Technology, 32(10):7019–7032, 2022a.
- Style-hallucinated dual consistency learning for domain generalized semantic segmentation. In ECCV, pages 535–552. Springer, 2022b.
- Adversarial style augmentation for domain generalized urban-scene segmentation. Advances in Neural Information Processing Systems, 35:338–350, 2022.
- Unsupervised domain adaptation for semantic segmentation via class-balanced self-training. In Proceedings of the European conference on computer vision (ECCV), pages 289–305, 2018.
- Confidence regularized self-training. In Proceedings of the IEEE/CVF international conference on computer vision, pages 5982–5991, 2019.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

