- The paper demonstrates that including victim community targets in prompts yields a 20–30% improvement in macro F1 scores across datasets.
- The study finds that integrating rationales enhances performance by 10–20%, while adding definitions leads to mixed results depending on the model and dataset.
- Combined prompt strategies can introduce diminishing returns, highlighting challenges in optimizing scalable hate speech detection using LLMs.
Probing LLMs for Hate Speech Detection: A Technical Analysis of Strengths and Vulnerabilities
Problem Context and Motivation
The escalation of hate and toxic speech on digital platforms necessitates robust, scalable detection frameworks. Manual annotation is resource-intensive, exposes annotators to harmful material, and typically fails to scale. While LLMs have been leveraged for hate speech classification, prior work overlooked leveraging auxiliary inputs—such as explanations (rationales), definitions, and explicit victim community targets—for augmenting detection performance. This paper systematically investigates the impact of diverse prompt strategies, combining such contextual information, in zero-shot mode across three representative LLMs (GPT-3.5, text-davinci-003, Flan-T5-large) and three hate speech datasets (HateXplain, Implicit Hate, ToxicSpans), with rigorous quantitative and qualitative analyses (2310.12860).
Experimental Setup and Prompt Variations
The research utilizes three datasets—each offering structured annotations, different hate/offensive/toxic speech definitions, and, where available, rationales or target community information:
- HateXplain: Provides detailed classes (normal, offensive, hate speech), rationales, and target communities.
- Implicit Hate: Distinguishes explicit/implicit/non-hate, with implied statements and target annotations for implicit hate only.
- ToxicSpans: Focuses on toxic/non-toxic labeling and extractive rationales (spans).
LLMs are evaluated in zero-shot mode with a series of prompt variations, isolated and combined:
- Vanilla: Base prompt with only the content for classification.
- Definition: Adds task/class definitions to the prompt.
- Rationale/Explanation: Incorporates rationales/implied statements as input or requires explanation as output.
- Target: Includes victim group information as input or requests target identification.
- Combination: Joins definitions with rationales/targets at input/output.
The input and output prompt templates are meticulously designed to probe both label prediction and explanation/target extraction.
Comprehensive evaluation (macro F1, accuracy, precision, recall, BLEU/BERTScore for explanations) reveals several consistent findings:
- Target Information as Input: Inclusion of target community information yields the most substantial performance increase, with macro F1 improvements of ~20–30% over vanilla prompts across datasets and LLMs.
- Rationales/Explanations: Supplying explicit rationales/implied statements as input provides ~10–20% gains.
- Definitions: Effects are dataset/model-dependent; sometimes improving, sometimes degrading performance, with largest gains in ToxicSpans.
- Prompt Combinations: Combining strategies (e.g., target plus explanation plus definition) does not further enhance performance; in some cases, performance worsens.
- Model Comparisons: Flan-T5-large performs best for HateXplain and Implicit Hate with vanilla prompts; text-davinci-003 consistently outperforms gpt-3.5-turbo-0301, highlighting that newer LLM versions do not necessarily yield better results in hate speech detection.
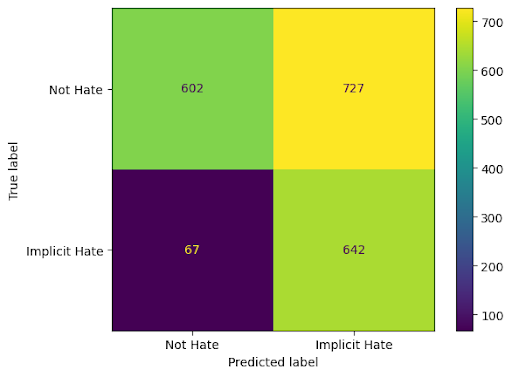
Figure 1: Vanilla + target_input for implicit hate, highlighting confusion between non-hate and implicit hate classes when target information is included.
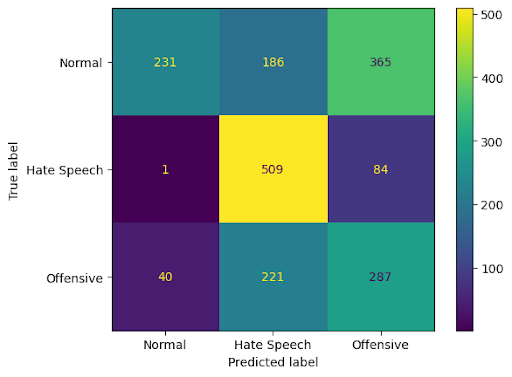
Figure 2: Vanilla + target_input for HateXplain, illustrating improved separation between hate/offensive/normal when target information is available.
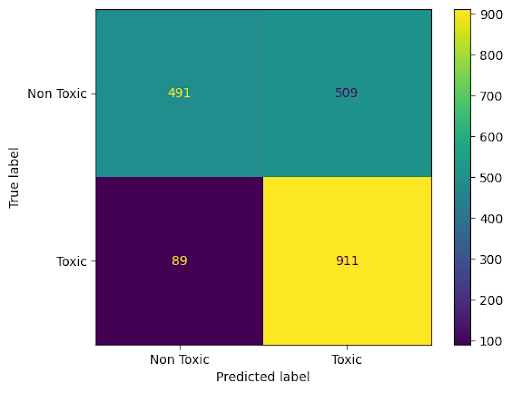
Figure 3: Vanilla + explanation_input for ToxicSpans, reflecting the boost in toxic/non-toxic discrimination with rationale input.
Error Analysis and Vulnerability Typology
Systematic error analysis identifies dominant misclassification patterns and typologies:
- Implicit Hate: Models frequently misclassify non-hate as implicit hate, especially in presence of ‘racist’ or ‘pro-white’ tokens and ideological content.
- HateXplain: Confusion prevails between normal and offensive classes; negation, vocabulary gap (e.g., slang/unknown terms), and polysemy contribute heavily.
- ToxicSpans: Ideological statements and fact-checking posts are falsely labeled toxic, while implicitly toxic remarks are sometimes missed.
Manual coding via topic modeling (LDA) exposes these weaknesses. Sensitive terminology, negation words, explicit statements of support, and fact-check/news-related content are frequent sources of error. These constitute potential ‘jailbreak’ prompts, underscoring the need for robust defense mechanisms in deployed systems.
Model Robustness, Statistical Significance, and Explanation Quality
Statistical hypothesis testing (Mann-Whitney U) confirms significant performance increases for best prompt-model combinations over vanilla setups (p-values < 0.01 for most configurations). Explanation generation is quantitatively assessable via BERTScore and sentence-BLEU, but quality varies non-monotonically with prompt complexity.
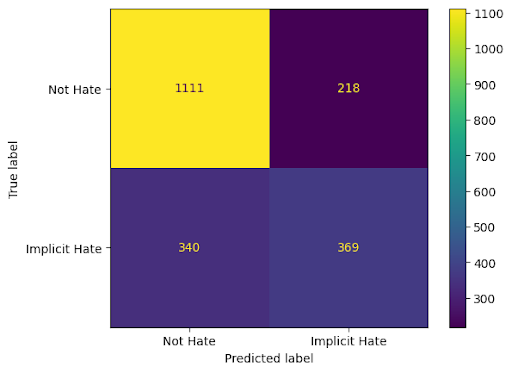
Figure 4: Vanilla + target_input for implicit hate, demonstrating improvement yet new confusion patterns.
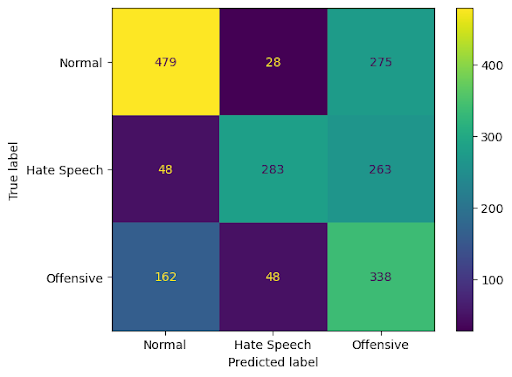
Figure 5: Vanilla + target_input for HateXplain, further evidencing the residual misclassification between normal and offensive classes.
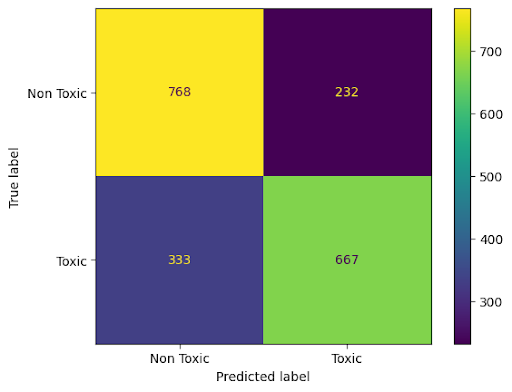
Figure 6: Vanilla + definition_input for ToxicSpans, showing definition-based prompt impact on toxic span detection.
Practical and Theoretical Implications
The results indicate that fine-grained prompt engineering—specifically, augmenting LLM inputs with explicit context such as victim community information and rationales—substantially enhances hate speech detection accuracy. However, additive prompt strategies do not synergistically benefit classification, suggesting diminishing returns with prompt complexity. Explanations and target outputs improve transparency but are not uniformly reliable; explanation quality is inconsistent in low-score scenarios.
These findings direct practitioners toward design of annotation pipelines emphasizing target/victim metadata and articulated rationales. From a theoretical perspective, the granularity and conditional dependency structure of prompts manifest as a non-trivial factor in downstream performance, independent of underlying model scale or architecture.
Limitations and Ethical Considerations
Experiments are limited to English datasets. Models are treated as black boxes; internal state or attention mechanisms are not analyzed. Prompt variations, though comprehensive, are not exhaustive. Caution is advised in real-world deployment, as empirical vulnerabilities may risk inadvertent mislabeling or exploit via adversarial prompts.
Future Directions
- Multilingual Generalization: Extending the prompt engineering schema to cross-lingual data with culturally adaptive definitions and rationales.
- Defensive Prompt Engineering: Systematic identification and mitigation of ‘jailbreak’ vulnerabilities via adversarial test cases.
- Stable Explanation Generation: Model-side architectural interventions (e.g., rationalization layers) for reliable and consistent explanatory output.
- Annotation Protocols: Inclusion of structured target information and rationales in annotation guidelines for hate speech datasets.
Conclusion
The study demonstrates clear performance and robustness gains in hate speech detection by incorporating contextual prompt engineering for LLMs. Individual strategies, notably target information input, deliver large accuracy improvements, while combination strategies lack synergy. Persistent vulnerabilities necessitate rigorous safeguards. The results mandate increased attention to prompt design and dataset annotation protocols for scalable, reliable hate speech moderation in deployed NLP systems (2310.12860).

