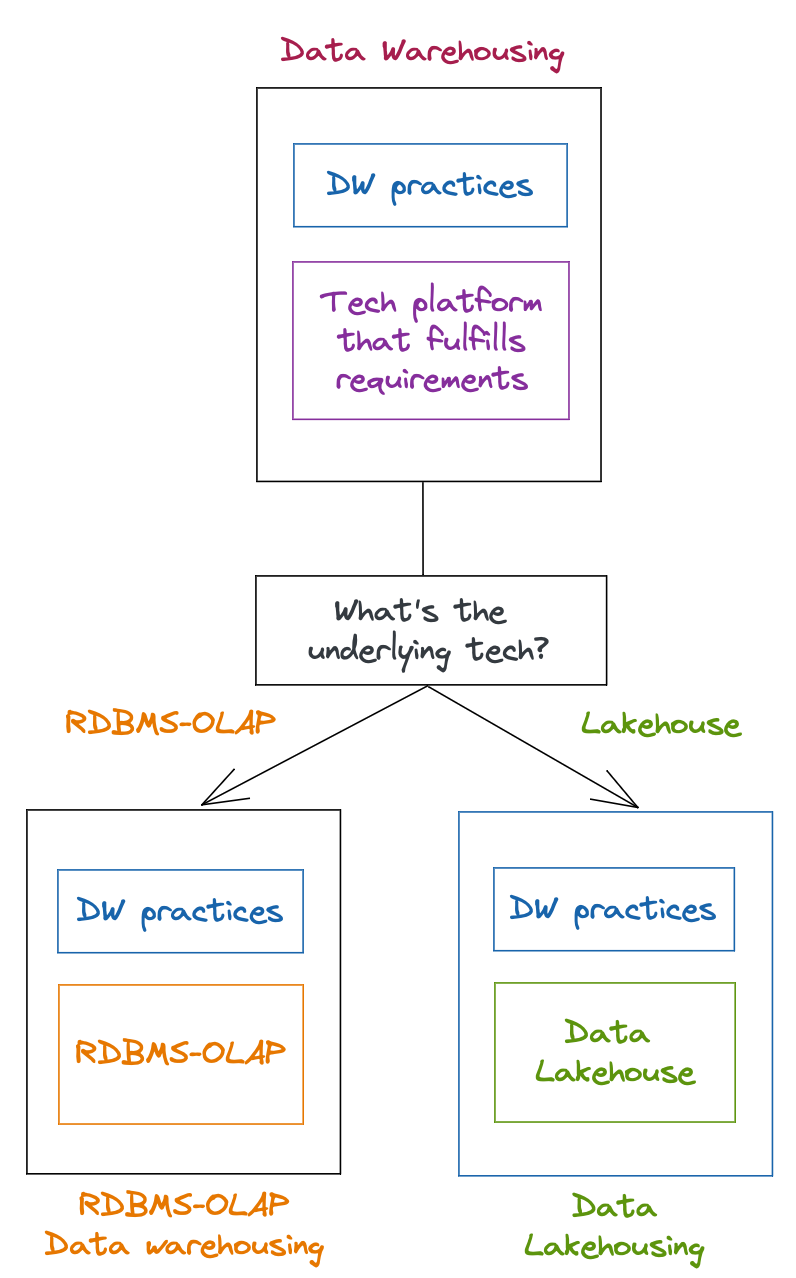
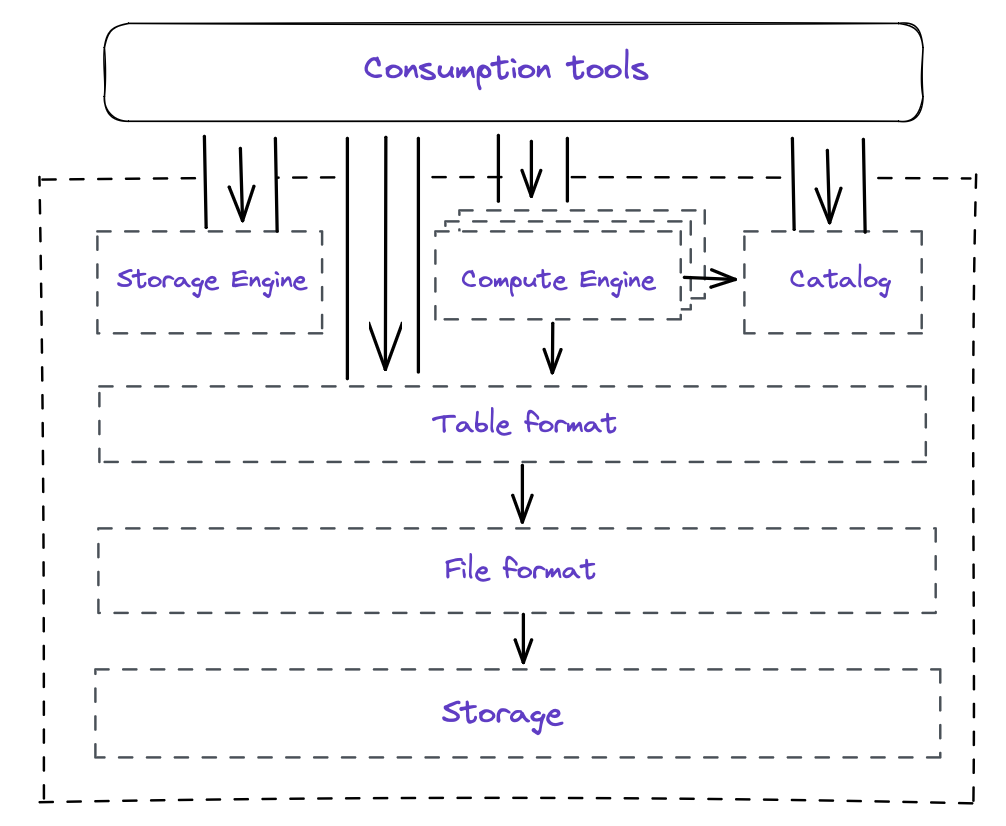
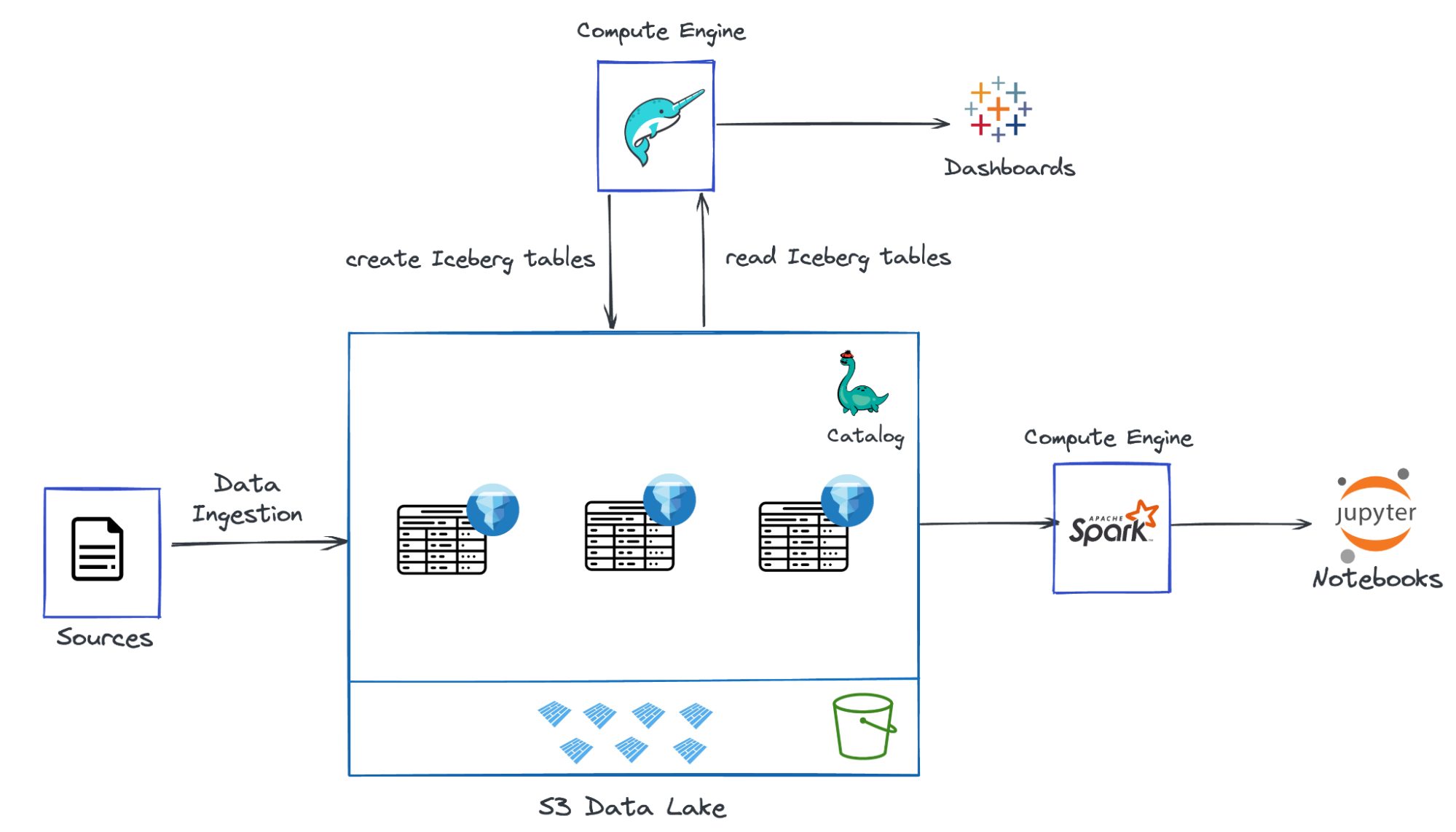
The Data Lakehouse: Data Warehousing and More
Abstract: Relational Database Management Systems designed for Online Analytical Processing (RDBMS-OLAP) have been foundational to democratizing data and enabling analytical use cases such as business intelligence and reporting for many years. However, RDBMS-OLAP systems present some well-known challenges. They are primarily optimized only for relational workloads, lead to proliferation of data copies which can become unmanageable, and since the data is stored in proprietary formats, it can lead to vendor lock-in, restricting access to engines, tools, and capabilities beyond what the vendor offers. As the demand for data-driven decision making surges, the need for a more robust data architecture to address these challenges becomes ever more critical. Cloud data lakes have addressed some of the shortcomings of RDBMS-OLAP systems, but they present their own set of challenges. More recently, organizations have often followed a two-tier architectural approach to take advantage of both these platforms, leveraging both cloud data lakes and RDBMS-OLAP systems. However, this approach brings additional challenges, complexities, and overhead. This paper discusses how a data lakehouse, a new architectural approach, achieves the same benefits of an RDBMS-OLAP and cloud data lake combined, while also providing additional advantages. We take today's data warehousing and break it down into implementation independent components, capabilities, and practices. We then take these aspects and show how a lakehouse architecture satisfies them. Then, we go a step further and discuss what additional capabilities and benefits a lakehouse architecture provides over an RDBMS-OLAP.
- Apache Hudi. https://hudi.apache.org.
- Apache Iceberg Hidden Partitioning. https://iceberg.apache.org/docs/latest/partitioning/.
- Apache Iceberg: The open table format for analytic datasets. https://iceberg.apache.org.
- Apache Ranger. https://ranger.apache.org.
- Blue-green deployment in Software Engineering. https://en.wikipedia.org/wiki/Blue-green_deployment.
- Delta Lake. https://delta.io.
- Dremio Arctic. https://www.dremio.com/platform/arctic/.
- Dremio Sonar. https://www.dremio.com/platform/sonar/.
- Git: Version control. https://git-scm.com.
- IBM PureData System for Analytics Architecture. https://www.redbooks.ibm.com/redpapers/pdfs/redp4725.pdf.
- LakeFS. https://lakefs.io.
- Multi-statement transactions: BigQuery.
- Optimistic Concurrency Control. https://en.wikipedia.org/wiki/Optimistic_concurrency_control.
- Project Nessie. https://projectnessie.org.
- Scikit-learn: Machine Learning in Python. https://scikit-learn.org/stable/.
- Symmetric Multiprocessor Architecture. https://www.sciencedirect.com/science/article/abs/pii/B978012420158300006X.
- Tabular. https://tabular.io.
- Teradata Vantage Engine Architecture and Concepts. https://quickstarts.teradata.com/teradata-vantage-engine-architecture-and-concepts.html.
- Dremio Cloud Under the Hood. https://www.dremio.com/blog/dremio-cloud-under-the-hood/.
- Column-Stores vs. Row-Stores: How Different Are They Really?. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data (Vancouver, Canada) (SIGMOD ’08). Association for Computing Machinery, New York, NY, USA, 967–980. https://doi.org/10.1145/1376616.1376712
- BlinkDB: Queries with Bounded Errors and Bounded Response Times on Very Large Data. In Proceedings of the 8th ACM European Conference on Computer Systems (Prague, Czech Republic) (EuroSys ’13). Association for Computing Machinery, New York, NY, USA, 29–42. https://doi.org/10.1145/2465351.2465355
- Automated Selection of Materialized Views and Indexes in SQL Databases. In VLDB 2000, Proceedings of 26th International Conference on Very Large Data Bases, September 10-14, 2000, Cairo, Egypt, Amr El Abbadi, Michael L. Brodie, Sharma Chakravarthy, Umeshwar Dayal, Nabil Kamel, Gunter Schlageter, and Kyu-Young Whang (Eds.). Morgan Kaufmann, 496–505. http://www.vldb.org/conf/2000/P496.pdf
- Amazon Redshift Re-Invented. In Proceedings of the 2022 International Conference on Management of Data (Philadelphia, PA, USA) (SIGMOD ’22). Association for Computing Machinery, New York, NY, USA, 2205–2217. https://doi.org/10.1145/3514221.3526045
- A High-Performance Distributed Relational Database System for Scalable OLAP Processing. In 2019 IEEE International Parallel and Distributed Processing Symposium (IPDPS). 738–748. https://doi.org/10.1109/IPDPS.2019.00083
- What can partitioning do for your data warehouses and data marts?. In Proceedings 2000 International Database Engineering and Applications Symposium (Cat. No.PR00789). 437–445. https://doi.org/10.1109/IDEAS.2000.880634
- Philip A. Bernstein and Nathan Goodman. 1981. Concurrency Control in Distributed Database Systems. ACM Comput. Surv. 13, 2 (jun 1981), 185–221. https://doi.org/10.1145/356842.356846
- A. Berson and L. Dubov. 2011. Master Data Management and Data Governance, Second Edition. McGraw-Hill/Osborne. https://books.google.ca/books?id=SnS8wgEACAAJ
- Li Cai and Yangyong Zhu. 2015. The Challenges of Data Quality and Data Quality Assessment in the Big Data Era. Data Science Journal (May 2015). https://doi.org/10.5334/dsj-2015-002
- Design and Selection of Materialized Views in a Data Warehousing Environment: A Case Study. In Proceedings of the 2nd ACM International Workshop on Data Warehousing and OLAP (Kansas City, Missouri, USA) (DOLAP ’99). Association for Computing Machinery, New York, NY, USA, 42–47. https://doi.org/10.1145/319757.319787
- Surajit Chaudhuri and Umeshwar Dayal. 1997. An Overview of Data Warehousing and OLAP Technology. SIGMOD Rec. 26, 1 (mar 1997), 65–74. https://doi.org/10.1145/248603.248616
- The Snowflake Elastic Data Warehouse. In Proceedings of the 2016 International Conference on Management of Data (San Francisco, California, USA) (SIGMOD ’16). Association for Computing Machinery, New York, NY, USA, 215–226. https://doi.org/10.1145/2882903.2903741
- Implementation of change data capture in ETL process for data warehouse using HDFS and apache spark. In 2017 International Workshop on Big Data and Information Security (IWBIS). 49–55. https://doi.org/10.1109/IWBIS.2017.8275102
- Dynamic management of data warehouse security levels based on user profiles. In 2016 4th IEEE International Colloquium on Information Science and Technology (CiSt). 59–64. https://doi.org/10.1109/CIST.2016.7804961
- Sidra Faisal and Mansoor Sarwar. 2014. Handling slowly changing dimensions in data warehouses. Journal of Systems and Software 94 (2014), 151–160. https://doi.org/10.1016/j.jss.2014.03.072
- Hao Fan and Alexandra Poulovassilis. 2004. Schema Evolution in Data Warehousing Environments – A Schema Transformation-Based Approach. In Conceptual Modeling – ER 2004, Paolo Atzeni, Wesley Chu, Hongjun Lu, Shuigeng Zhou, and Tok-Wang Ling (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 639–653.
- Data Lakes: A Survey of Functions and Systems. IEEE Transactions on Knowledge & Data Engineering (2023), 1–20. https://doi.org/10.1109/TKDE.2023.3270101
- OLTP through the Looking Glass, and What We Found There. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data (Vancouver, Canada) (SIGMOD ’08). Association for Computing Machinery, New York, NY, USA, 981–992. https://doi.org/10.1145/1376616.1376713
- Jason Hughes. Apache Iceberg: An architectural look under the covers. https://www.dremio.com/resources/guides/apache-iceberg-an-architectural-look-under-the-covers/.
- W.H. Inmon and Daniel Linstedt. 2015. 2.3 - Parallel Processing. In Data Architecture: a Primer for the Data Scientist, W.H. Inmon and Daniel Linstedt (Eds.). Morgan Kaufmann, Boston, 57–62. https://doi.org/10.1016/B978-0-12-802044-9.00010-6
- Sebastian Insausti. Running a Data Warehouse on PostgreSQL.
- Data lake: a new ideology in big data era. ITM Web Conf. 17 (2018), 03025. https://doi.org/10.1051/itmconf/20181703025
- Ralph Kimball and Margy Ross. 2011. The data warehouse toolkit: the complete guide to dimensional modeling. John Wiley & Sons.
- Mark Levene and George Loizou. 2003. Why is the Snowflake Schema a Good Data Warehouse Design? Inf. Syst. 28, 3 (may 2003), 225–240. https://doi.org/10.1016/S0306-4379(02)00021-2
- James Malone. Iceberg Tables: Powering Open Standards with Snowflake Innovations. https://www.snowflake.com/blog/iceberg-tables-powering-open-standards-with-snowflake-innovations/.
- Anuradha Manchar and Ankit Chouhan. 2017. Salesforce CRM: A new way of managing customer relationship in cloud environment. In 2017 Second International Conference on Electrical, Computer and Communication Technologies (ICECCT). 1–4. https://doi.org/10.1109/ICECCT.2017.8117887
- A. Mishra. 2019. Amazon S3. John Wiley Sons Ltd, Chapter 9, 181–200. https://doi.org/10.1002/9781119556749.ch9 arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1002/9781119556749.ch9
- Finding an efficient rewriting of OLAP queries using materialized views in data warehouses. Decision Support Systems 32, 4 (2002), 379–399. https://doi.org/10.1016/S0167-9236(01)00123-3
- Usability-based caching of query results in OLAP systems. Journal of Systems and Software 68, 2 (2003), 103–119. https://doi.org/10.1016/S0164-1212(02)00142-5
- Rethinking Concurrency Control for In-Memory OLAP DBMSs. In 2018 IEEE 34th International Conference on Data Engineering (ICDE). 1453–1464. https://doi.org/10.1109/ICDE.2018.00164
- Ravindra Punuru. Four Reasons Data Lakes Are Moving to the Cloud. https://tdwi.org/articles/2019/09/03/arch-all-four-reasons-data-lakes-moving-to-cloud.aspx.
- A Comparison of Data-Driven and Data-Centric Architectures using E-Learning Solutions. In 2022 International Conference Advancement in Data Science, E-learning and Information Systems (ICADEIS). 1–6. https://doi.org/10.1109/ICADEIS56544.2022.10037358
- Seppo Sippu and Eljas Soisalon-Soininen. 2015. Transaction Processing: Management of the Logical Database and Its Underlying Physical Structure. Springer Publishing Company, Incorporated.
- C-Store: A Column-Oriented DBMS. In Proceedings of the 31st International Conference on Very Large Data Bases (Trondheim, Norway) (VLDB ’05). VLDB Endowment, 553–564.
- Building a serverless Data Lakehouse from spare parts. (2023). arXiv:2308.05368 [cs.DB]
- ANCA VADUVA and THOMAS VETTERLI. 2001. METADATA MANAGEMENT FOR DATA WAREHOUSING: AN OVERVIEW. International Journal of Cooperative Information Systems 10, 03 (2001), 273–298. https://doi.org/10.1142/S0218843001000357 arXiv:https://doi.org/10.1142/S0218843001000357
- Panos Vassiliadis. 2009. A Survey of Extract-Transform-Load Technology. Int. J. Data Warehous. Min. 5, 3 (2009), 1–27. https://doi.org/10.4018/jdwm.2009070101
- Deepak Vohra. 2016. Apache Parquet. Apress, Berkeley, CA, 325–335. https://doi.org/10.1007/978-1-4842-2199-0_8
- Adrienne Watt. 2014. Database Design. BCcampus. https://opentextbc.ca/dbdesign01/chapter/chapter-9-integrity-rules-and-constraints/
- Alex Woodie. The Cloud Is Great for Data, Except for Those Super High Costs.
- Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics. In Conference on Innovative Data Systems Research.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

