- The paper demonstrates that adapted LLMs, using in-context learning and QLoRA, surpass medical experts in clinical summarization tasks.
- It employs metrics like BLEU, ROUGE-L, and MEDCON to quantitatively assess LLM performance across diverse datasets.
- The study indicates that integrating LLM-generated summaries can reduce documentation burdens and improve patient care workflows.
Adapted LLMs Can Outperform Medical Experts in Clinical Text Summarization
Introduction
This paper, titled "Adapted LLMs Can Outperform Medical Experts in Clinical Text Summarization" (2309.07430), investigates the potential of adapted LLMs in clinical text summarization tasks. These tasks are crucial for reducing the documentation burden faced by healthcare professionals, thereby allowing them to focus more on patient care.
The study evaluates the effectiveness of various LLMs using adaptation methods across distinct summarization tasks that include radiology reports, patient questions, progress notes, and doctor-patient dialogues. It employs a combination of quantitative assessments and clinical reader studies, revealing that LLM-generated summaries often match or surpass those created by medical experts.
Methods
LLMs and Adaptation Techniques
The paper introduces eight LLMs, categorized into open-source and proprietary models. The open-source seq2seq models (FLAN-T5 and FLAN-UL2) are evaluated alongside open-source autoregressive models (Alpaca, Med-Alpaca, Vicuna, and Llama-2). Proprietary autoregressive models like GPT-3.5 and GPT-4 complete the lineup, offering larger context lengths and parameter counts.
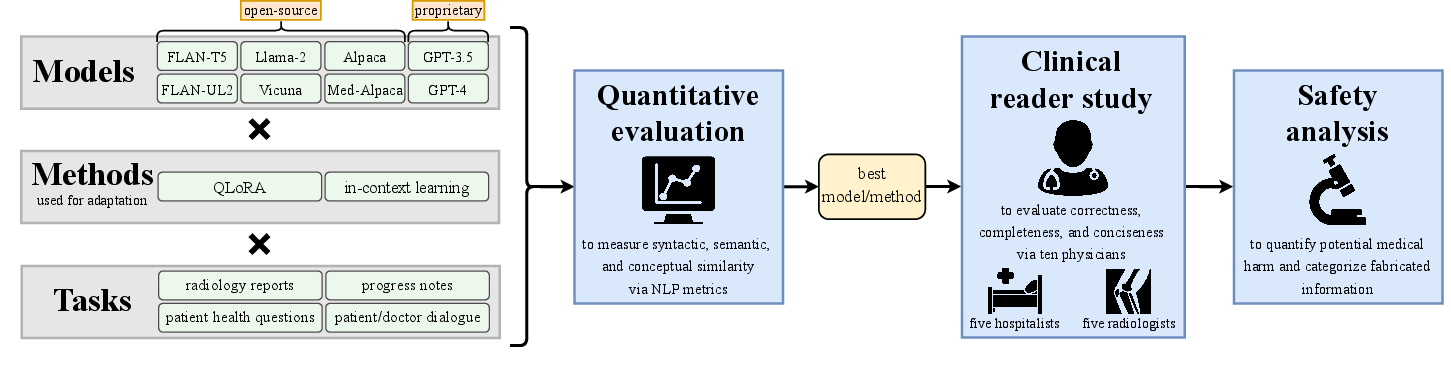
Figure 1: Framework overview. First, we quantitatively evaluate each valid combination (times) of LLM and adaptation method across four distinct summarization tasks comprising six datasets.
Adaptation techniques include In-Context Learning (ICL) and Quantized Low-Rank Adaptation (QLoRA). ICL involves incorporating task-specific examples within the model prompts, while QLoRA enables efficient fine-tuning with less computational demand by altering a small subset of model weights.
Datasets
The evaluation leverages six open-source datasets covering diverse summarization tasks. These datasets vary in sample count, token length, and lexical variance, challenging the LLMs to perform across different contexts and complexities.
Quantitative Metrics
The study deploys summarization metrics like BLEU, ROUGE-L, BERTScore, and MEDCON to assess the quality of generated summaries. These metrics offer a syntactic, semantic, and conceptual evaluation of the LLM performance against human-generated reference summaries.
Results
Quantitative Evaluation
The assessment of domain-specific fine-tuning revealed that task adaptation significantly impacts performance, highlighting the importance of aligning LLMs with specific clinical tasks rather than general domain adaptation.

Figure 2: Alpaca vs. Med-Alpaca. Given that most data points are below the dashed lines denoting equivalence, we conclude that Med-Alpaca's fine-tuning with medical Q{additional_guidance}A data results in worse performance for our clinical summarization tasks.
Figure 2 illustrates the comparative performance between Alpaca and Med-Alpaca, showing the latter's decline despite its medical domain tuning. Additionally, comparison of adaptation methods indicated that the proprietary models, especially GPT-4, excel with sufficient in-context examples due to their superior capacity and context length.
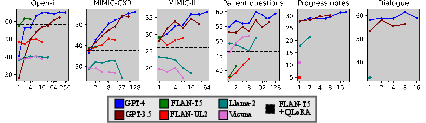
Figure 3: MEDCON scores vs. number of in-context examples across models and datasets. We also include the best model fine-tuned with QLoRA (FLAN-T5) as a horizontal dashed line for valid datasets.
Clinical Reader Study
A clinical reader study involving ten physicians concluded that adapted LLM summaries generally exhibited higher completeness and correctness than those created by medical experts. Qualitative analyses pinpointed specific strengths, such as accurate identification of clinical conditions and avoidance of common errors like laterality mistakes.
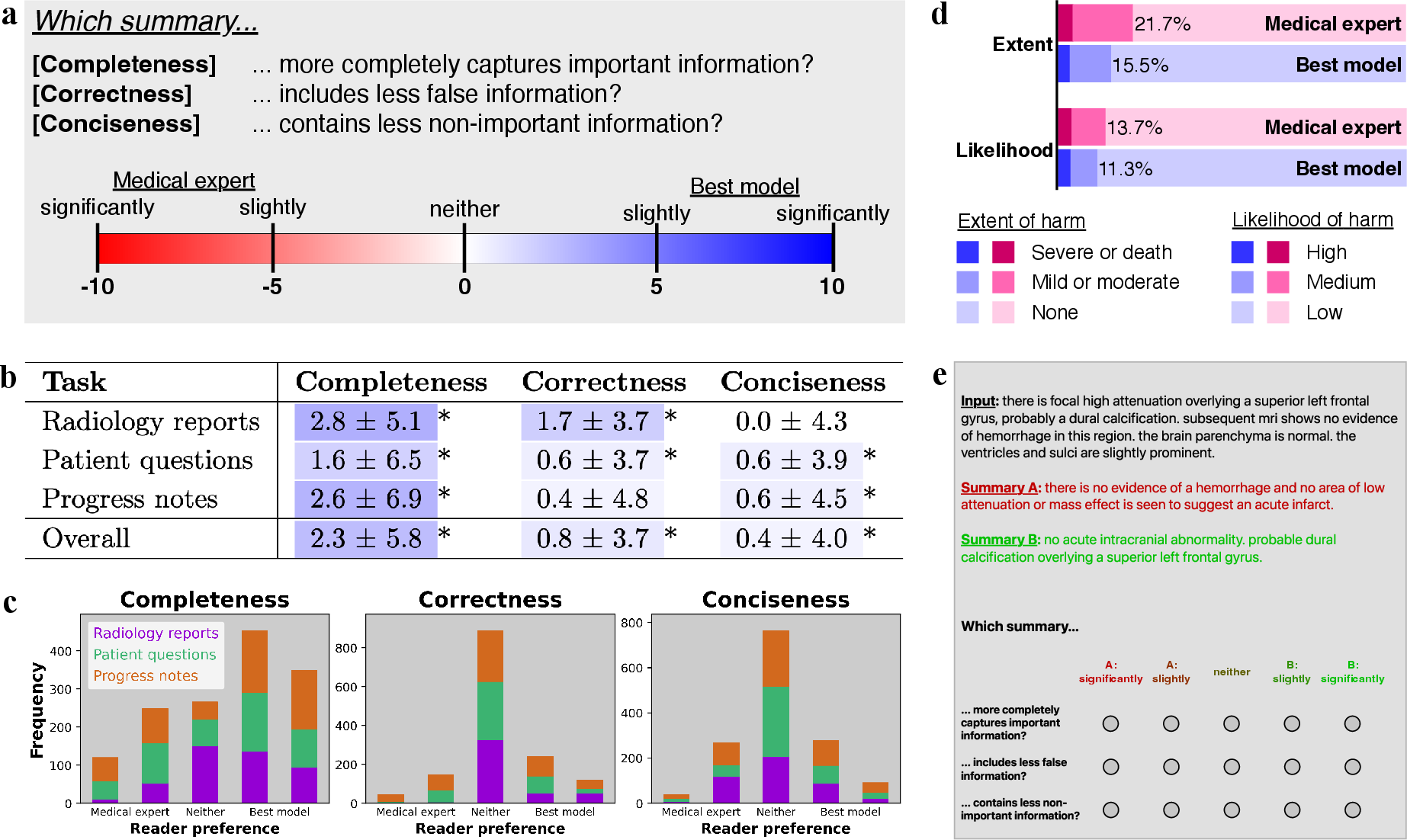
Figure 4: Clinical reader study. (a) Study design comparing the summaries from the best model versus that of medical experts...
Conciseness remained a challenge, particularly in radiology report summarization where LLMs generated longer summaries with occasionally extraneous information. However, prompt engineering and temperature tuning offer paths for improving this attribute.
Discussion
The implications of integrating LLMs into clinical workflows are profound, potentially easing documentation burdens and enhancing healthcare delivery. The study foresees these models being adapted further for specific clinical contexts through specialized prompts and examples. Moreover, the safety analysis suggested that the potential for medical harm from fabricated information could be mitigated with LLMs, proposing that their inclusion might enhance overall clinical accuracy.
Security considerations center on data governance, particularly with proprietary models, proposing open-source alternatives where possible. Future research should expand to more extensive datasets and broader clinical contexts to solidify these preliminary findings.
Conclusion
This study presents compelling evidence that adapted LLMs can outperform medical experts in clinical text summarization across diverse tasks, offering a strategic advantage in clinical documentation. Incorporating LLM-generated summaries into healthcare could significantly improve the focus and quality of patient care. Continued research and deployment in clinical settings are necessary to fully realize these benefits and ensure safety and efficacy.