- The paper demonstrates that SSL-derived discrete tokens can bridge ASR and TTS tasks, achieving competitive recognition on LibriSpeech and superior resynthesis quality in TTS.
- The methodology employs vector quantization and k-means clustering alongside tailored augmentation techniques to optimize token granularity and robustness.
- Experimental results reveal that while discrete tokens excel in English low-resource settings, challenges persist in noisy and non-English environments, suggesting avenues for further research.
Towards Universal Speech Discrete Tokens: A Case Study for ASR and TTS
Introduction to Speech Discrete Tokens
The paper "Towards Universal Speech Discrete Tokens: A Case Study for ASR and TTS" explores the challenges and potential of utilizing discrete tokens in speech processing tasks such as Automatic Speech Recognition (ASR) and Text-to-Speech (TTS). Discrete tokens allow for lower storage requirements and the application of NLP techniques. The study compares and optimizes discrete tokens generated by leading self-supervised learning (SSL) models. This research aims to uncover the universality of speech discrete tokens across different speech tasks, providing evidence for their potential comparable performance in recognition tasks and superiority in synthesis tasks.
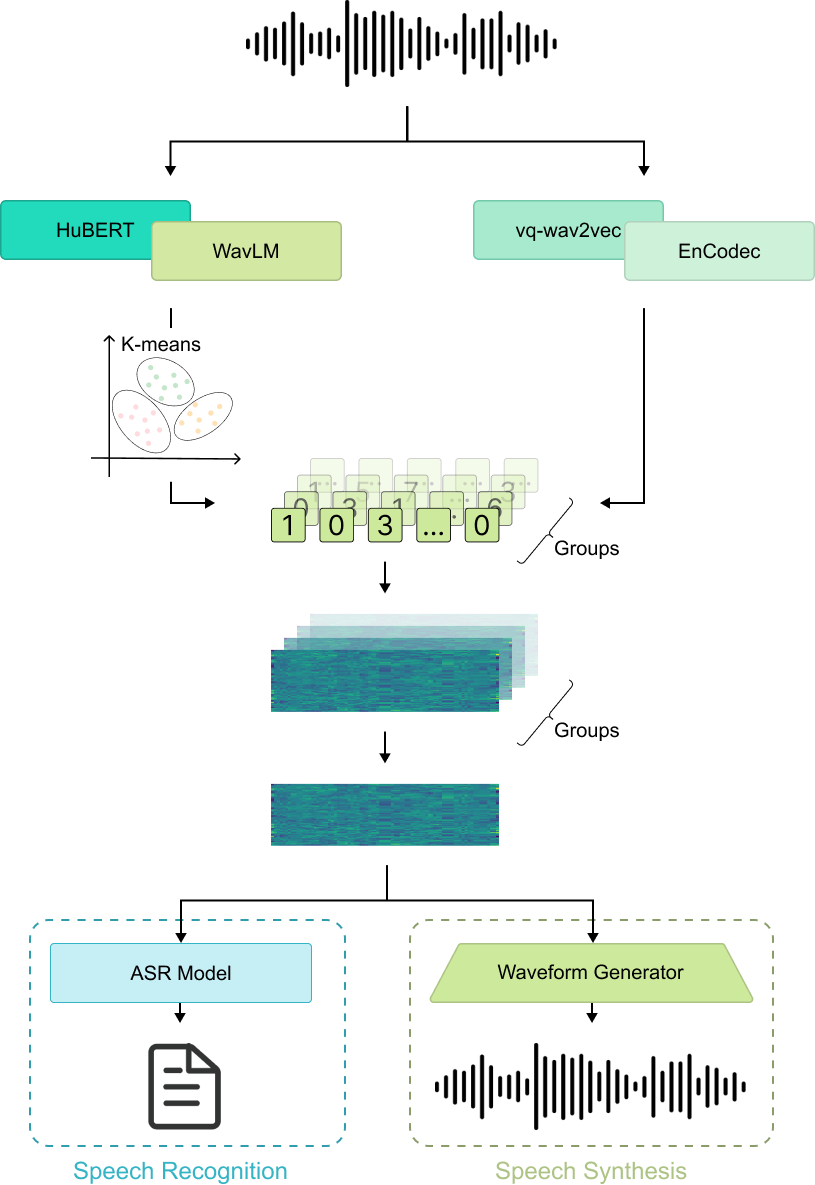
Figure 1: Illustration of the pipeline for speech discrete tokens.
Discrete Speech Tokens from SSL Models
The use of discrete tokens derived from SSL models like vq-wav2vec, HuBERT, and WavLM is central to this study. These models provide semantic tokens trained for linguistic information. Discretization can be achieved using Vector Quantization (VQ) or k-means clustering on embeddings, with the choice of clustering parameters impacting the granularity of the discretization. Discrete tokens balance semantic and acoustic features, aiming to serve a universal function across speech tasks.
Speech Recognition with Discrete Tokens
The study utilizes discrete tokens from different SSL models for training end-to-end ASR systems. Discrete tokens are embedded and processed to a uniform frame rate before input into Transducer-based ASR models. Customized augmentation techniques like time and embedding masking are employed to mitigate overfitting and enhance robustness in ASR training.
Results and Analysis
Experiments show that discrete tokens generated from WavLM and HuBERT models reveal promising ASR performance on English corpora like LibriSpeech, especially for low-resource scenarios. While discrete tokens achieve competitive results compared to traditional features on clean data, their performance lags in noisy or linguistically different settings, such as the Mandarin AISHELL-1 corpus. It highlights the challenge of generalization across varied acoustic conditions and languages.
Speech Synthesis with Discrete Tokens
In TTS tasks, discrete tokens' performance is benchmarked against conventional mel-spectrogram features through speech resynthesis experiments using CTX-vec2wav. These tokens have shown to outperform mel-spectrogram in subjective and objective evaluations, demonstrating their capability to produce high-quality audio irrespective of additional acoustic context modeling.
Experimental Insights
Comparison Across Tasks
The universality of discrete tokens is evaluated, showing their competitive performance in recognition and superiority in synthesis tasks. Discrete tokens from models like Encodec and DAC offer alternatives for efficient audio processing and compression, with variable performance in synthesis quality, revealing potential for further exploitation.
Ablation Studies
Ablation studies detail the impact of various augmentation strategies on ASR performance. Findings suggest that SpecAugment-style augmentations adapted for token sequences can significantly improve model robustness.
Conclusions
The exploration into universal discrete tokens underscores their promising adaptability across speech-related tasks. The findings support the thesis that discrete tokens could serve as a valuable bridging representation between speech and text tasks. Future research could benefit from refining token generation techniques and improving cross-linguistic generalization.
The research provides a critical step in understanding the application of SSL-derived discrete tokens and sets the stage for further explorations into bridging speech and text through a unified token representation.

