- The paper reveals that emergent abilities in LLMs are primarily driven by in-context learning rather than inherent reasoning.
- It analyzes over 1,000 experiments on 18 models across 22 tasks to clearly differentiate in-context learning from instruction-following techniques.
- The study emphasizes improving prompt designs and instruction tuning as safer, more effective strategies for advancing LLM capabilities.
Are Emergent Abilities in LLMs Just In-Context Learning?
Introduction
The paper "Are Emergent Abilities in LLMs Just In-Context Learning?" explores the examination of emergent abilities in the context of LLMs and posits that these abilities are primarily a manifestation of in-context learning. The study investigates over 1,000 experiments using 18 diverse models, scaling from 60M to 175B parameters, across 22 tasks to dissect the underpinnings of emergent abilities, aiming to clarify misconceptions around the reasoning capacities of LLMs.
Emergence of Abilities in LLMs
The growing documentation of unexpected abilities in LLMs introduces potential implications for future NLP research. However, such abilities often arise from large-scale models rather than through native reasoning skills. This study meticulously examines tasks linked to emergent abilities for bias-inducing elements like in-context learning and evaluates their influence. Notably, it challenges prior claims suggesting the emergence of true reasoning, advocating instead for in-context learning as the primary driver, without evidence pointing towards complex reasoning capabilities.
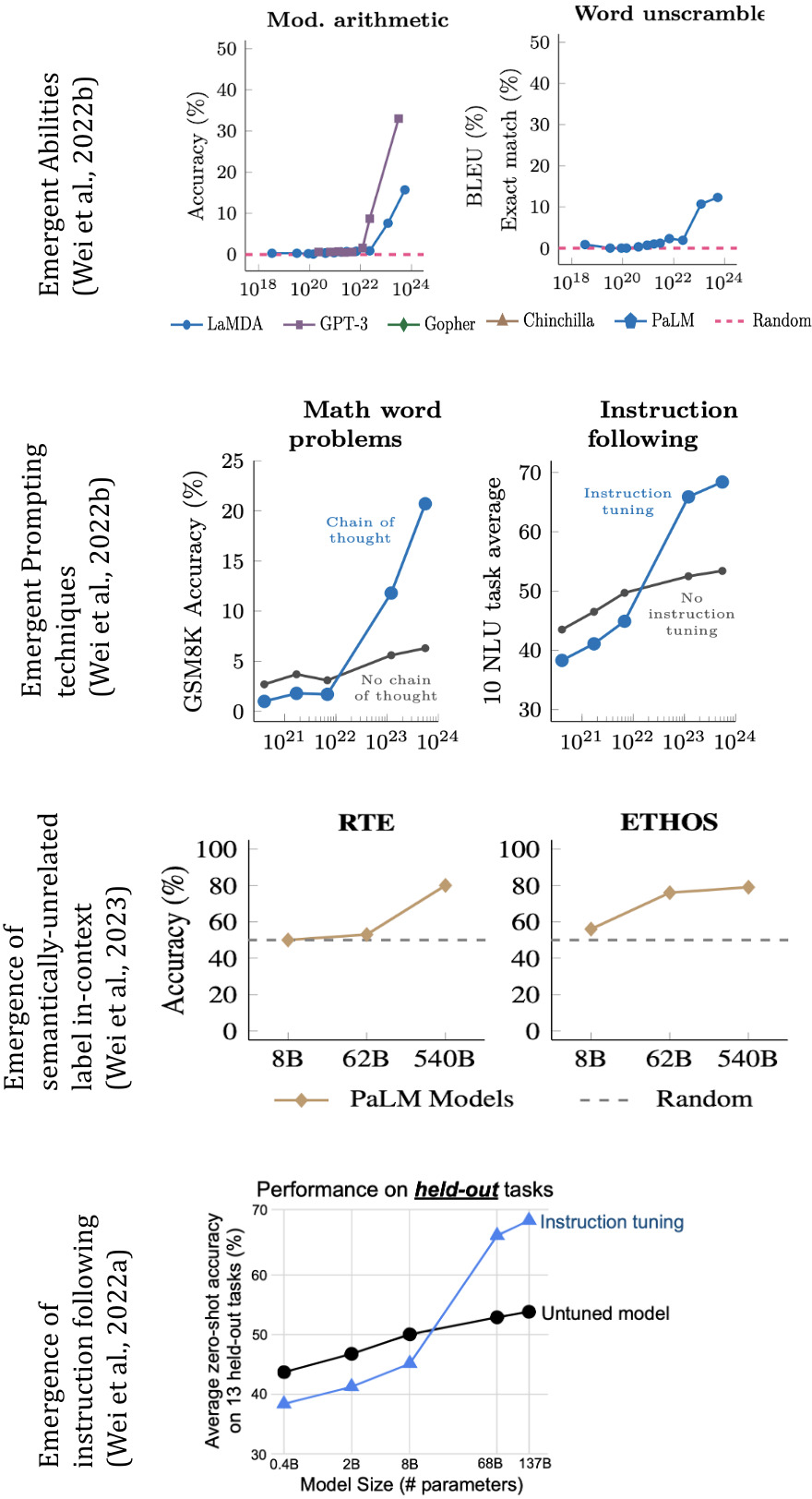
Figure 1: Emergence of various abilities correlated with training parameters, illustrating the role of emergence as influenced by prompting techniques.
In-Context Learning vs. Reasoning
The paper scrutinizes distinctions between prompting techniques, such as in-context learning and instruction-following, versus emergent reasoning skills. In-context learning imitates fine-tuning by acquiring task-specific learning from contextual examples without explicit training. Instruction tuning, often conjoined with explicit examples, fuses the model’s ability to interpret and act on instructions effectively, raising questions about reality versus perception in task solving.
Methodological Approaches
Investigating these phenomena involves restricting confounding factors by examining LLMs absent of in-context learning and instruction execution. A segregated evaluation of abilities independent of these techniques allows an exploration of true emergent qualities. This methodology reveals no evidence for emergent reasoning absent of these factors, suggesting safety in using current LLMs, as perceived emergent abilities are products of training dynamics, not autonomous reasoning.
Implications for Future Developments
The notion that instruction tuning leverages in-context learning rather than fostering innate reasoning suggests focused future paths, emphasizing enhancing model interactions via improved instruction strategies and prompt designs. Aligning these with scalable architectures could yield models better attuned to nuanced task-specific requirements without assuming emergent dangers.
Conclusion
The comprehensive analysis points to in-context learning as a pivotal element in the perceived emergence of abilities in LLMs. The paper posits that large-scale LLMs do not inherently develop complex reasoning capabilities but rather demonstrate emergent-like performance primarily due to in-context mechanisms and instruction efficiencies. This delineation assists in demystifying LLM behaviors and aligns safety expectations with practical capabilities, paving the way for transparent, nuanced AI advancements.

Figure 2: The comparative framework for instruction tuning processes illustrating the translation of instructions into pragmatic exemplars.
By dismantling the myth of reasoning emergence and aligning observed capabilities with theoretical foundations of learning efficiency, this study redirects focus towards sustainable, safe expansions in LLM applications.