QLoRA: Efficient Finetuning of Quantized LLMs
Abstract: We present QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. QLoRA backpropagates gradients through a frozen, 4-bit quantized pretrained LLM into Low Rank Adapters~(LoRA). Our best model family, which we name Guanaco, outperforms all previous openly released models on the Vicuna benchmark, reaching 99.3% of the performance level of ChatGPT while only requiring 24 hours of finetuning on a single GPU. QLoRA introduces a number of innovations to save memory without sacrificing performance: (a) 4-bit NormalFloat (NF4), a new data type that is information theoretically optimal for normally distributed weights (b) double quantization to reduce the average memory footprint by quantizing the quantization constants, and (c) paged optimziers to manage memory spikes. We use QLoRA to finetune more than 1,000 models, providing a detailed analysis of instruction following and chatbot performance across 8 instruction datasets, multiple model types (LLaMA, T5), and model scales that would be infeasible to run with regular finetuning (e.g. 33B and 65B parameter models). Our results show that QLoRA finetuning on a small high-quality dataset leads to state-of-the-art results, even when using smaller models than the previous SoTA. We provide a detailed analysis of chatbot performance based on both human and GPT-4 evaluations showing that GPT-4 evaluations are a cheap and reasonable alternative to human evaluation. Furthermore, we find that current chatbot benchmarks are not trustworthy to accurately evaluate the performance levels of chatbots. A lemon-picked analysis demonstrates where Guanaco fails compared to ChatGPT. We release all of our models and code, including CUDA kernels for 4-bit training.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces QLoRA, a new way to fine‑tune very LLMs using much less memory and money than before. It lets researchers fine‑tune a 65‑billion‑parameter model on a single 48 GB GPU (a high‑end graphics card), while keeping the same quality you’d get from the usual, more expensive methods. Using QLoRA, the authors built a model family called Guanaco that performs almost as well as ChatGPT on a popular chatbot test, but trains in about a day on one machine.
What were they trying to find out?
In simple terms, the paper asks:
- Can we fine‑tune huge LLMs cheaply—without losing accuracy?
- Can we store model weights in a very compact way (4 bits) and still get the same results as full‑precision training?
- Which tricks actually matter to make this work in practice?
- How do different training datasets and model sizes affect real chatbot quality?
- Are automatic evaluations (like using GPT‑4 as a judge) good enough compared to human ratings?
How did they do it? (Methods explained simply)
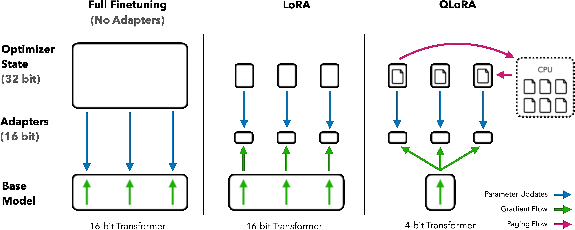
Think of a giant LLM like a massive library. Normally, to update how it behaves (fine‑tune it), you keep the whole library open and writable—which takes tons of memory. QLoRA takes a different approach: it “freezes” the big library so you don’t rewrite it directly and instead adds small “plug‑in shelves” that you adjust. Meanwhile, it stores the big frozen library in a super‑compressed form to save space.
Here are the core ideas, with everyday analogies:
- 4‑bit storage of model weights: Like compressing a high‑resolution photo to a tiny file, but in a smart way so it still looks great when viewed.
- Frozen base model + small adapters (LoRA): Imagine the main factory is locked (to save costs), and you only tweak a few small add‑on tools that sit next to the main machine to adjust its behavior.
- Compute in 16‑bit, store in 4‑bit: You store the big stuff in tiny form, but when you need it, you temporarily “unpack” it to do precise calculations, then keep training only the small add‑ons.
The three technical innovations that make this practical:
- 4‑bit NormalFloat (NF4): A new way to store numbers in just 4 bits that fits how model weights naturally look (they follow a bell‑curve). This makes compression smarter and more accurate than older 4‑bit types.
- Double Quantization: A “compression‑inside‑compression” trick. Not only do they compress the weights, they also compress the constants used to scale those weights. This squeezes memory even further without hurting quality.
- Paged Optimizers: Like swapping apps between your phone’s memory and storage when you’re low on RAM. This prevents sudden memory spikes from crashing training on long inputs.
Putting it all together (QLoRA):
- Keep the big pretrained model frozen and stored in 4‑bit NF4.
- Add small, trainable adapters (LoRA) at every layer.
- During training, temporarily “decompress” the needed parts to 16‑bit to compute, pass gradients through the frozen model into the adapters, and only update the adapters.
- Use paging so the GPU doesn’t run out of memory.
Evaluation approach:
- They fine‑tuned more than 1,000 models across different sizes and datasets.
- They tested academic skills (MMLU) and real chatbot quality (Vicuna prompts and the OpenAssistant dataset).
- They used both human judges and GPT‑4 to compare model answers head‑to‑head, turning the results into Elo ratings (a fair tournament‑style score).
What did they find, and why is it important?
Key results:
- Same quality, much less memory: QLoRA reduces memory needs to under 48 GB for a 65B model (vs. over 780 GB with the usual method), yet matches full 16‑bit fine‑tuning performance.
- NF4 works best: Their new 4‑bit number format (NF4) is more accurate than older 4‑bit types (like FP4 or Int4). It preserves model quality after compression.
- State‑of‑the‑art open chatbot: Their Guanaco models, especially Guanaco‑65B, scored about 99.3% as well as ChatGPT on the Vicuna benchmark—trained in roughly 24 hours on a single GPU.
- Small but mighty: Guanaco‑7B runs in about 5 GB of memory and still beats larger baselines like Alpaca‑13B on the same benchmark.
- Data quality > data size: A small, high‑quality dataset (like OASST1, around 9k examples) can outperform much larger ones (like a 450k subset of FLAN v2) for chatbot behavior.
- Benchmarks measure different things: Being great at MMLU (multiple‑choice academic tests) doesn’t guarantee great chatbot conversations, and vice versa. You need the right training data for the right goal.
- GPT‑4 as a judge is close—but not perfect: GPT‑4 rankings roughly agree with humans at the system level, making it a cheaper alternative for evaluation, though disagreements do happen.
Why it matters:
- This makes fine‑tuning giant models affordable and accessible to many more researchers and developers.
- It shows you don’t always need huge datasets—good data can beat big data for certain tasks.
- It opens the door to training strong, specialized chatbots on modest hardware.
What could this mean for the future?
- Democratized AI development: More people can fine‑tune top‑tier models on a single GPU (or even run strong smaller models on consumer devices), accelerating innovation outside big labs.
- Faster iteration: Because it’s cheaper and lighter, teams can try many ideas, datasets, and settings quickly.
- Better, targeted assistants: Organizations can fine‑tune models for specific domains (medicine, law, education) using smaller, carefully curated datasets.
- Smarter evaluation practices: Using Elo tournaments and mixing human and model judges can make chatbot testing fairer and cheaper, though we should still be cautious.
- Open ecosystem growth: The authors release code, kernels, and adapters, making it easier for the community to build on their work and push quality even further.
In short, QLoRA shows that with clever compression and smart training tricks, you can fine‑tune huge models efficiently without sacrificing performance—bringing high‑quality AI closer to everyone.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, drawing directly from the paper’s findings and released tooling.
- Cost-efficient finetuning of large LLMs on a single GPU for domain-specific assistants
- Sectors: healthcare, finance, legal, customer service, education
- Tools/workflows: Hugging Face Transformers integration; bitsandbytes NF4 CUDA kernels; QLoRA adapters across all transformer layers; Double Quantization; Paged Optimizers; small, high-quality datasets (e.g., OASST1)
- Assumptions/dependencies: Access to permitted base weights (e.g., LLaMA license); a single 24–48GB GPU; adherence to QLoRA hyperparameter guidance (adapters at every layer); high-quality task-aligned data; on-prem security/compliance setup if required
- On-premise, privacy-preserving customization of LLMs for regulated environments
- Sectors: healthcare (HIPAA), finance (SOX/GLBA), government, legal
- Tools/workflows: Local NF4 quantization, LoRA adapters, single-GPU training; audit-friendly data pipelines; air-gapped training if needed
- Assumptions/dependencies: Compliance-ready infrastructure; appropriate data governance; legal clearance for model weights and data
- Multi-tenant architectures with per-client adapters on a shared quantized base model
- Sectors: SaaS platforms, customer support BPOs, enterprise software vendors
- Tools/workflows: Hot-swapping LoRA adapters per tenant; adapter routing; model hosting with shared 4-bit base
- Assumptions/dependencies: Runtime support for loading/unloading multiple adapters; adapter versioning; memory budgeting
- Rapid A/B testing and model iteration via adapter swaps and tournament-style evaluation
- Sectors: product teams, applied ML research
- Tools/workflows: Pairwise GPT-4/human judging; Elo ranking; dual-order prompts to reduce ordering bias; automated CI pipelines for model evaluation
- Assumptions/dependencies: GPT-4 API access or human raters; controls for judge bias and confidence intervals; prompt standardization
- Edge and mobile deployment of 7B models for offline assistants
- Sectors: mobile software, automotive infotainment, IoT
- Tools/workflows: Guanaco-7B (≈5GB footprint); efficient inference runtimes; on-device caching; offline mode for privacy
- Assumptions/dependencies: Devices with 6–8GB RAM and supported inference backend; careful latency and thermal management; local safety filters
- Academic scaling of instruction tuning and evaluation with modest hardware
- Sectors: academia, non-profit research labs
- Tools/workflows: QLoRA training up to 33B/65B on accessible hardware; small curated datasets; Elo-style evaluations; integration in open-source stacks
- Assumptions/dependencies: Access to compatible GPUs; adherence to dataset licenses; reproducible training/eval configs
- Data curation strategies emphasizing small, high-quality instruction datasets
- Sectors: data engineering, annotation ops
- Tools/workflows: Curate OASST1-like datasets; deduplication; quality scoring; task-aligned sampling
- Assumptions/dependencies: Data quality outweighs sheer volume; representativeness for the target tasks; clear data provenance
- Infrastructure and cost optimization for ML Ops
- Sectors: cloud providers, ML platform teams
- Tools/workflows: NF4 + Double Quantization to reduce memory; Paged Optimizers to avoid OOM spikes; gradient checkpointing
- Assumptions/dependencies: Normality assumption for NF4 holds sufficiently for weights; sequence-length spikes handled via paging; careful monitoring of rare paging slowdowns
- Benchmarking improvements with tournament-style Elo rankings
- Sectors: evaluation teams, standards bodies, applied ML
- Tools/workflows: Pairwise comparisons with tie-handling; dual-order presentations; Elo aggregation across thousands of seeds
- Assumptions/dependencies: Recognition of partial disagreement between GPT-4 and human ratings; mitigation of ordering effects; transparent reporting of confidence intervals
Long-Term Applications
The following use cases require additional research, scaling, hardware/software development, or standards to become widely feasible.
- Personalized on-device LLMs via federated finetuning of adapters
- Sectors: mobile, healthcare, education
- Tools/products/workflows: Per-user LoRA adapters trained locally; secure aggregation; privacy-preserving personalization at scale
- Assumptions/dependencies: Efficient federated adapter merging; strong privacy guarantees; robust on-device training pipelines; energy constraints
- Hardware co-design for low-bit training and inference (NF4-aware accelerators)
- Sectors: semiconductor, HPC
- Tools/products/workflows: Tensor cores optimized for 4-bit dequantization; native NF4 support; hardware-accelerated paging
- Assumptions/dependencies: Industry standardization of 4-bit datatypes; compiler/runtime support; clear business case for low-bit hardware
- Adapter marketplaces and plugin ecosystems for domain specialization
- Sectors: software platforms, open-source ecosystem
- Tools/products/workflows: Public hubs for vetted adapters; adapter provenance and licensing; compatibility testing; security scanning
- Assumptions/dependencies: Interoperability standards; governance and quality signals; sustainable maintenance for community adapters
- Robust, trustworthy chatbot evaluation standards beyond model-based judging
- Sectors: policy, standards bodies, academia, industry consortia
- Tools/products/workflows: Multi-rater human protocols; bias-aware metrics; domain-specific benchmark suites; standardized reporting of uncertainty
- Assumptions/dependencies: Community consensus; funding for annotation; alignment on task definitions; mitigation of judge/model biases
- Extending QLoRA to multimodal models (vision, audio, robotics)
- Sectors: robotics, media, accessibility tech, autonomous systems
- Tools/products/workflows: Quantized finetuning for ViT/transformer-based vision/audio models; LoRA across modality-specific layers; generalized paged optimizers
- Assumptions/dependencies: Weight distribution properties compatible with NF4; custom kernels for multimodal ops; safety-critical validation for robotics
- Continuous learning in production via streaming adapter updates and safe rollback
- Sectors: MLOps, enterprise software
- Tools/products/workflows: Pipeline for incremental adapter finetuning; gated deployments using Elo/quality thresholds; automated rollback mechanisms
- Assumptions/dependencies: High-quality, well-governed feedback streams; robust monitoring; strict safety and compliance guardrails
- Low-carbon AI initiatives enabled by low-bit training and larger low-precision models
- Sectors: sustainability, cloud, enterprise ESG
- Tools/products/workflows: Emissions accounting for 4-bit vs 16-bit finetuning; energy-aware scheduling; green SLAs and reporting
- Assumptions/dependencies: Standardized measurement frameworks; reproducible energy baselines; hardware efficiency data
- Standardized protocols for model-based evaluations (addressing ordering effects and ties)
- Sectors: academia, policy, applied ML
- Tools/products/workflows: Formal judging protocols; statistical corrections for ordering and tie bias; open-source evaluation kits
- Assumptions/dependencies: Broad adoption; ongoing validation against human judgments; transparent governance
- Secure sovereign LLMs for public sector and defense
- Sectors: government, defense, critical infrastructure
- Tools/products/workflows: QLoRA training on classified/sensitive corpora; air-gapped clusters; rigorous red-teaming and auditing; secure adapter management
- Assumptions/dependencies: Licensing and export controls; strong security posture; formal certification processes for deployment
These applications collectively leverage the paper’s core contributions—QLoRA’s 4-bit NF4 quantization, Double Quantization, paged optimizers, and the empirical finding that small high-quality datasets can deliver state-of-the-art results—to unlock lower-cost finetuning, broader access, and more responsible deployment of LLMs.
Glossary
- 4-bit NormalFloat (NF4): An information-theoretically optimal 4-bit quantization data type tailored for normally distributed weights. "4-bit NormalFloat (NF4), a new data type that is information theoretically optimal for normally distributed weights"
- 5-shot evaluation: A few-shot setup where models are evaluated with five exemplars per task before answering. "We report 5-shot test accuracy."
- BFloat16 (BF16): A 16-bit floating-point format used for computation that preserves dynamic range with fewer bits than FP32. "QLoRA has one low-precision storage data type, in our case usually 4-bit, and one computation data type that is usually BFloat16."
- Block-wise k-bit Quantization: Quantizing tensors in fixed-size chunks so each block has its own scale, improving robustness to outliers. "Block-wise k-bit Quantization"
- CUDA kernels: GPU-executable routines optimized for parallel computation, here for efficient low-bit training. "We release all of our models and code, including CUDA kernels for 4-bit training."
- Cross-entropy loss: A standard supervised learning objective measuring divergence between predicted and true distributions. "we perform QLoRA finetuning with cross-entropy loss (supervised learning) without reinforcement learning"
- Dequantization: The process of mapping low-bit discrete values back to higher-precision real values. "Dequantization is the inverse:"
- Double Quantization (DQ): A memory-saving technique that quantizes both weights and the quantization constants themselves. "We introduce Double Quantization (DQ), the process of quantizing the quantization constants for additional memory savings."
- Elo rating: A paired-comparison scoring system estimating relative performance via expected win rates. "Elo rating, which is widely used in chess and other games, is a measure of the expected win-rate relative to an opponent's win rate"
- Empirical cumulative distribution function (ECDF): A nonparametric estimate of the cumulative distribution used to compute quantiles from data. "Quantile quantization works by estimating the quantile of the input tensor through the empirical cumulative distribution function."
- FLAN v2: A large instruction-tuning corpus aggregation commonly used for finetuning LLMs. "Finetuning Llama models on FLAN v2 does particularly well on MMLU, but performs worst on the Vicuna benchmark"
- Fleiss' kappa: A statistic for measuring agreement among multiple raters on categorical items. "Fleiss ."
- FP32 (32-bit floating point): Standard single-precision floating-point format used as a high-precision baseline. "For example, quantizing a 32-bit Floating Point (FP32) tensor into a Int8 tensor with range :"
- FP4 (4-bit floating point): A low-precision floating-point format used for quantization, generally less accurate than NF4. "we also note that QLoRA with FP4 lags behind the 16-bit brain float LoRA baseline by about 1 percentage point."
- FP8 (8-bit floating point): An 8-bit floating-point format used to quantize auxiliary data like scales in Double Quantization. "We use NF4 for and FP8 for ."
- GLUE: A benchmark suite for general language understanding tasks. "Our evaluations include GLUE \citep{wang2018glue} with RoBERTa-large"
- Gradient checkpointing: A memory-saving technique that recomputes activations during backpropagation instead of storing them. "With gradient checkpointing~\citep{chen2016training}, the input gradients reduce to an average of 18 MB per sequence"
- Guanaco: A family of QLoRA-finetuned models trained on instruction-following data. "Our best model family, which we name Guanaco, outperforms all previous openly released models on the Vicuna benchmark"
- HH-RLHF: The Anthropic dataset focusing on helpful and harmless behavior with human feedback. "HH-RLHF~\citep{bai2022training}"
- Instruction tuning: Finetuning LLMs on datasets of instructions and responses to improve following natural language commands. "We proceed to investigate instruction tuning at scales that would be impossible to explore with full 16-bit finetuning on academic research hardware."
- Int8 (8-bit integer quantization): An integer quantization format often used to compress model weights and activations. "For example, quantizing a 32-bit Floating Point (FP32) tensor into a Int8 tensor with range :"
- Kendall Tau: A rank correlation coefficient measuring ordinal association between two rankings. "with a Kendall Tau of and Spearman rank correlation of "
- LLaMA: A family of LLMs frequently used as base models for finetuning. "regular 16-bit finetuning of a LLaMA 65B parameter model"
- LoRA (Low-rank Adapters): A parameter-efficient finetuning method that inserts small trainable low-rank matrices while freezing the base model. "Low-rank Adapter (LoRA) finetuning \citep{hu2021lora} is a method that reduces memory requirements"
- MMLU (Massively Multitask Language Understanding): A comprehensive multi-domain benchmark for knowledge and reasoning. "We use the MMLU (Massively Multitask Language Understanding) benchmark \citep{hendrycksmeasuring}"
- Nucleus sampling: A decoding method that samples tokens from the smallest set whose cumulative probability exceeds p. "We describe below our proposed setup, using nucleus sampling with and temperature $0.7$ in all cases."
- OASST1 (OpenAssistant): A crowd-sourced, open dataset of instruction–response dialogues for assistant-style training. "a 9k sample dataset (OASST1) outperformed a 450k sample dataset (FLAN v2, subsampled)"
- Paged Optimizers: Optimizers that leverage unified memory paging to avoid out-of-memory errors during spikes. "Paged Optimizers to manage memory spikes."
- Parameter Efficient Finetuning (PEFT): Techniques that adapt large models with few additional parameters rather than updating all weights. "While LoRA was designed as a Parameter Efficient Finetuning (PEFT) method, most of the memory footprint for LLM finetuning comes from activation gradients"
- Perplexity: A language modeling metric indicating how well a probability model predicts a sample. "measure post-quantization zero-shot accuracy and perplexity across different models"
- Quantile Quantization: A scheme that allocates quantization levels to equal-probability intervals of the value distribution. "The NormalFloat (NF) data type builds on Quantile Quantization \citep{dettmers2022optimizers}"
- Quantization bins: The discrete value buckets of a quantizer to which continuous values are mapped. "then the quantization binsâcertain bit combinationsâare not utilized well"
- Quantization constant (quantization scale): The scaling factor used to map real values into the range of a low-bit representation. "where is the {\em quantization constant} or {\em quantization scale}."
- Reinforcement Learning from Human Feedback (RLHF): A training paradigm that optimizes models using preference signals from human raters. "finetuned with Reinforcement Learning from Human Feedback (RLHF) on the same OASST1 dataset"
- RougeL: A recall-oriented summarization metric based on the longest common subsequence. "RougeL for LLaMA 7B models on the Alpaca dataset."
- Spearman rank correlation: A nonparametric measure of rank correlation capturing monotonic relationships between rankings. "with a Kendall Tau of and Spearman rank correlation of "
- SRAM quantiles: Fast, approximate quantile estimation methods used to accelerate quantile-based quantization. "such as SRAM quantiles~\citep{dettmers2022optimizers}, are used to estimate them."
- Tournament-style benchmarking: An evaluation procedure where models compete in pairwise matches and rankings are derived from outcomes. "We use tournament-style benchmarking where models compete against each other in matches to produce the best response for a given prompt."
- Unified memory: A GPU–CPU memory abstraction enabling automatic page migration to handle oversubscription. "use the NVIDIA unified memory~\footnote{\tiny \url{https://docs.nvidia.com/cuda/cuda-c-programming-guide} feature wich does automatic page-to-page transfers between the CPU and GPU"
- Vicuna benchmark: A curated set of prompts and an evaluation protocol to assess chatbot-quality responses. "on the Vicuna benchmark (Table~\ref{tbl:vicuna_eval})."
- Zero-shot: An evaluation or task setting with no task-specific finetuning examples provided. "measure post-quantization zero-shot accuracy and perplexity"
- Zeropoint: The integer value corresponding to real zero in quantized representations, enabling exact encoding of zeros. "To ensure a discrete zeropoint of $0$ and to use all bits for a k-bit datatype, we create an asymmetric data type"
Collections
Sign up for free to add this paper to one or more collections.