- The paper introduces a novel LM-cor module that refines large language models' outputs by rewriting multiple candidate responses.
- It leverages few-shot prompting and candidate ranking to merge and optimize outputs for tasks like summarization and translation.
- Experiments show that even a 250M parameter model can effectively enhance a 62B LLM, achieving robust improvements across diverse datasets.
Small LLMs Improve Giants by Rewriting Their Outputs
Introduction
The paper "Small LLMs Improve Giants by Rewriting Their Outputs" explores a novel approach to enhance the performance of LLMs without traditional fine-tuning. The authors introduce a compact model, the LM-corrector (LMCor), which operates by refining the outputs of LLMs through rewriting rather than requiring direct access to the model's weights. This method provides a resource-efficient solution to improve LLMs' outputs across several tasks, offering a versatile plug-and-play enhancement to existing LLMs.
Methodology: Leveraging LLM Outputs
The LM-cor module is designed to improve the outputs of LLMs by merging and correcting the multiple candidate outputs generated through few-shot prompting. The process involves few-shot prompting an LLM to generate several candidate outputs for a given input. These candidates are then processed by LM-cor, which is trained to optimally rank, combine, and refine these candidates to produce a superior target sentence.
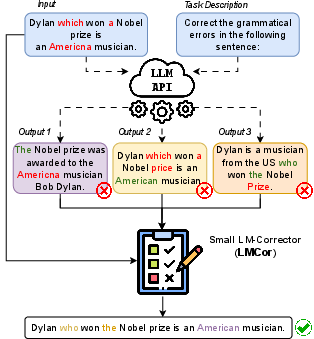
Figure 1: An illustration of the approach for grammatical error correction, highlighting the process of generating and refining outputs through the LM-corrector.
A crucial insight of this work is the observation that LLMs often produce a diverse array of plausible outputs for a given input. By exploiting this diversity, LM-cor can synthesize a more accurate and higher-quality result by selecting and improving upon the best candidate spans generated by the LLM.
Experiments and Results
The effectiveness of LMCor was validated across four natural language generation tasks: grammatical error correction, data-to-text generation, summarization, and machine translation. Experiments demonstrate that even a 250M parameter LM-cor can significantly enhance the performance of a 62B parameter LLM, often surpassing standard fine-tuning methods without requiring model weight access.
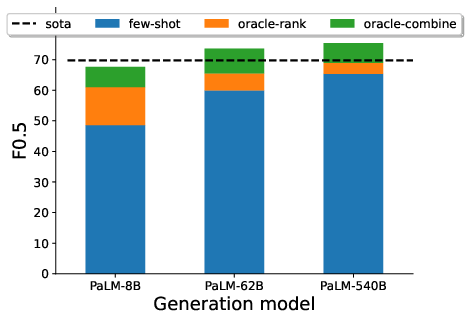
Figure 2: Potential of ranking and combining sampled candidates from PaLM models of different scales for grammatical error correction.
One notable result is the robustness of LMCor to different prompts, reducing the need for extensive prompt engineering. The corrector consistently improved task performance, indicating that it effectively compensates for variation in the quality of candidates due to different prompt designs.
Impact of LMCor on Model Scaling and Dataset Size
The study further explores scaling effects, demonstrating that LMCor's benefits are consistent across various dataset sizes and model scales. The enhanced performance with larger datasets underscores the corrector's ability to leverage available data effectively, providing substantial improvements even when training data is limited.
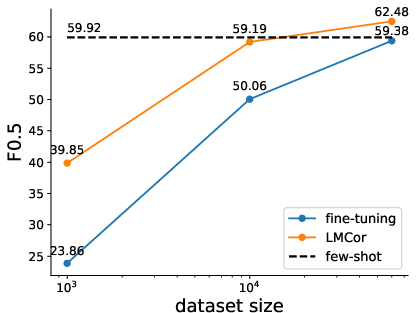
Figure 3: The effect of dataset size for standard fine-tuning and LMCor, showing robust improvements in grammatical error correction tasks.
Additionally, LMCor's ability to integrate seamlessly with different LLMs reflects its general applicability and potential utility in diverse real-world scenarios. This interoperability suggests that LMCor can serve as a universal performance booster across different LLMs.
Implications and Future Directions
The introduction of LMCor represents a significant shift in how LLMs can be optimized for task performance without direct model manipulation. This paradigm enables more accessible and efficient model improvements, making advanced language processing capabilities feasible even in resource-constrained environments.
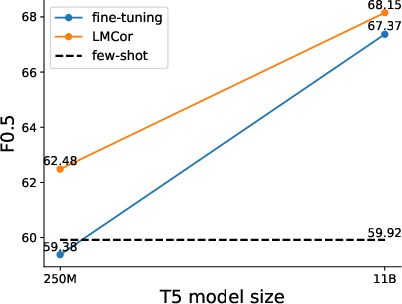
Figure 4: The effect of scaling for LMCor and fine-tuning, illustrating continued performance gains with increased model size.
The proposed method opens up several avenues for future research, including the extension of LMCor to other types of generative tasks, exploration of adapting LMCor to non-LLM architectures, and further optimization of the corrector model itself.
Conclusion
Overall, "Small LLMs Improve Giants by Rewriting Their Outputs" offers a compelling approach to enhancing LLM performance through a novel integration of a small correction model. This research illustrates that significant performance gains can be achieved by refining LLM outputs, paving the way for more efficient and versatile LLM applications. The versatility and minimal resource requirements of LMCor provide a foundation for advancing LLM capabilities in practical, real-world contexts.