- The paper demonstrates that in-context learning is achieved via kernel regression, where Transformer attention weights aggregate label information from prompt examples.
- It introduces a theoretical framework linking Bayesian inference and kernel regression, validated by both formal derivations and empirical analysis with GPT-J 6B.
- Empirical results on sentiment and classification tasks show up to 89.2% accuracy in reconstructing model outputs, guiding practical design for improved ICL.
Kernel Regression as an Explanatory Mechanism for Emergent In-Context Learning in LLMs
Introduction
The emergent in-context learning (ICL) capabilities in LLMs constitute a central phenomenon in contemporary natural language processing. ICL allows LLMs to learn input-output mappings from few-shot prompt demonstrations on-the-fly, without any explicit parameter updates. Despite increasing empirical characterization, the algorithmic underpinning of ICL in Transformer-based architectures remains opaque, particularly when deployed on realistic, linguistically complex tasks rather than synthetic settings.
This paper advances the theoretical understanding of ICL by establishing a rigorous connection between ICL and kernel regression in the context of LLMs. Specifically, it demonstrates that Transformers, when handling in-context demonstrations, closely approximate kernel regression behavior, both under a Bayesian probabilistic model and empirically through attention patterns and hidden state analysis.
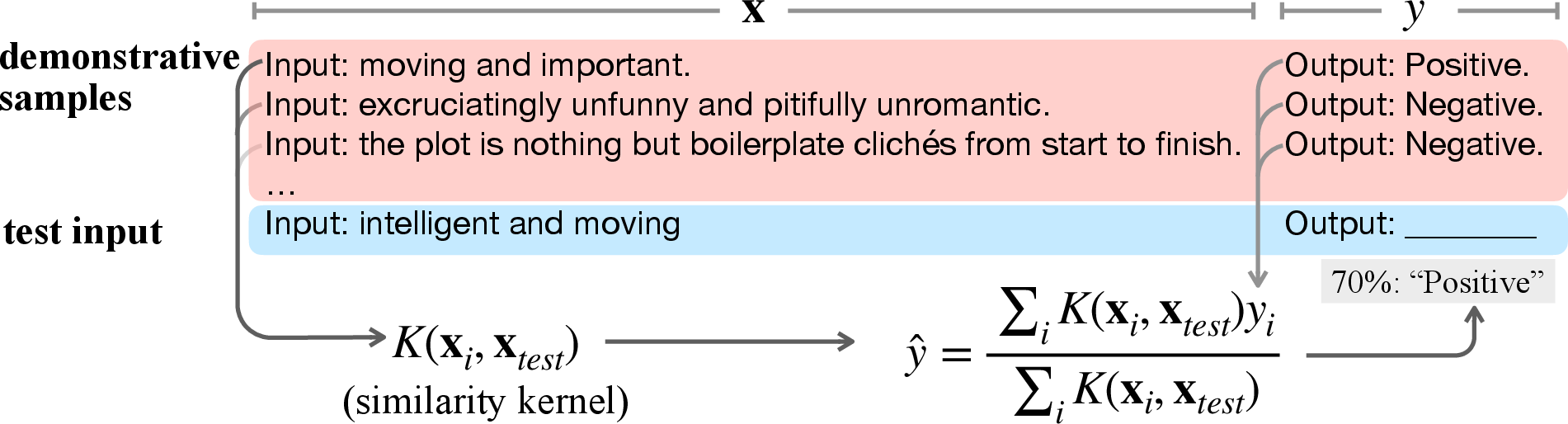
Figure 1: Our results suggests that LLMs might be conducting kernel regression on ICL prompts.
Theoretical Framework: ICL as Kernel Regression
The analysis situates LLM pretraining as occurring over a mixture of Hidden Markov Models (HMMs), encapsulating a diverse set of tasks. In-context learning prompts are parsed as sequences of demonstration examples followed by a query, formatted as [x1,y1,x2,y2,…,xn,yn,x]. Under mild assumptions—presence of sufficient delimiter tokens and distinguishability of tasks via KL divergence—the authors derive a central result: as the number of demonstrations increases, Bayesian inference over the prompt asymptotically converges to a kernel regression estimate,
y^=∑iK(x,xi)∑iyiK(x,xi),
where K(x,xi) is a data-dependent similarity kernel computed over intermediate representations. This kernel form matches the inductive bias of ICL: predictions for the test input x aggregate label information from similar in-context demonstrations. Notably, the derivation accounts for practical constraints of Transformer depth, as the attention mechanism efficiently implements the required weighted average (unlike recursive matrix products required for direct HMM inference).
Crucially, the derived kernel form aligns with the Transformer’s softmax attention equation (modulo the choice of kernel), suggesting that, during ICL, specific attention heads act as kernel regressors over internal representations.
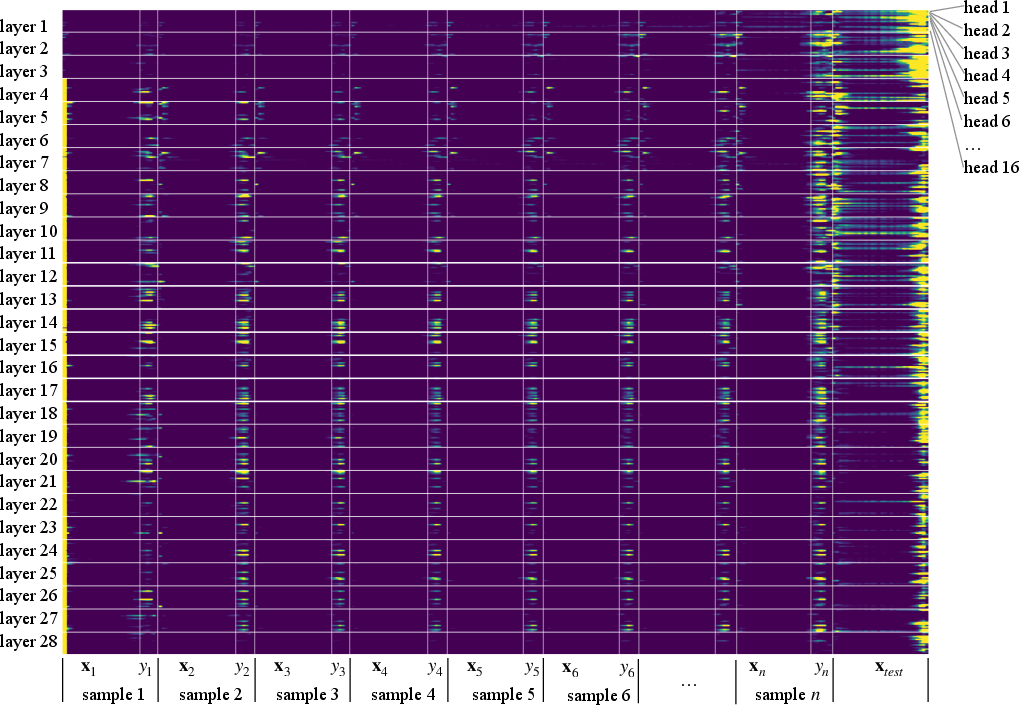
Figure 2: Averaged attention map over GLUE-sst2 test set, revealing consistent focus on label positions yi during in-context prediction, as predicted by the kernel regression hypothesis.
Empirical Validation
Empirical analysis is performed on the GPT-J 6B model, using benchmark sentiment and classification datasets. The investigation proceeds along four axes:
- Attention Distribution: Visualization and quantification of attention maps during ICL consistently show non-trivial attention mass concentrated on the label tokens of in-context demonstrations. This evidences aggregation of label information, supporting the kernel regression view.
- Prediction Reconstruction: The study reconstructs model predictions by using attention weights to average demonstration labels, in the spirit of kernel regression. This method achieves up to 89.2% accuracy in predicting GPT-J 6B’s own outputs on SST2, and 86.4% relative to ground truth labels.
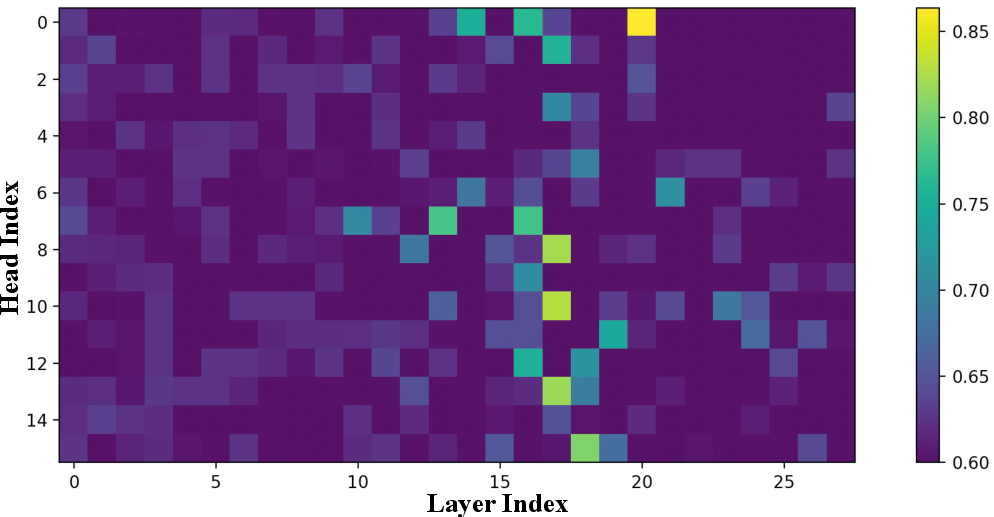
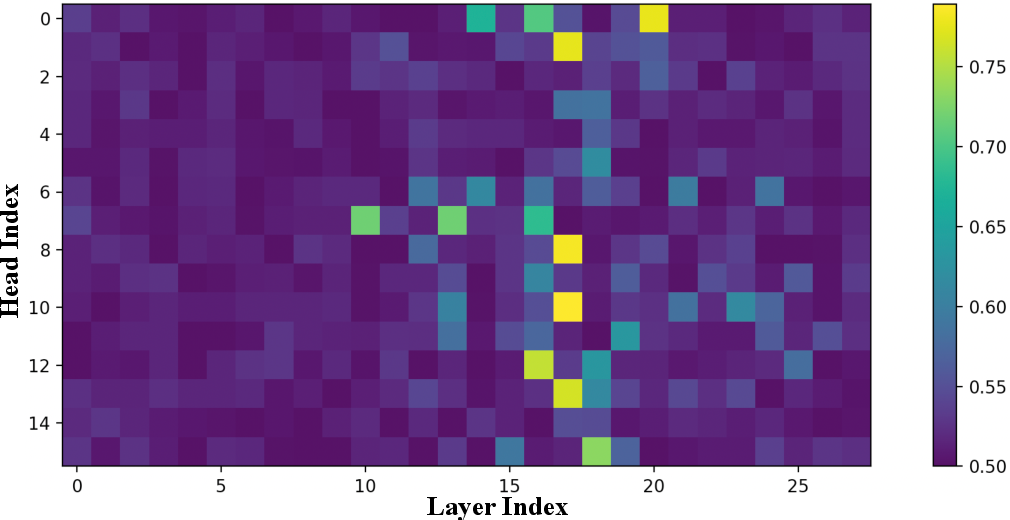
Figure 3: Accuracy compared with model output y^ using the reconstructed kernel regression prediction from attention weights.
- Interpretability of Attention Weights: Investigation of the correlation between attention values and prediction similarity (cosine similarity of P(o∣x) vectors) reveals that heads with high reconstruction accuracy attend more strongly to demonstrations with similar predicted output distributions, as required by a similarity kernel.
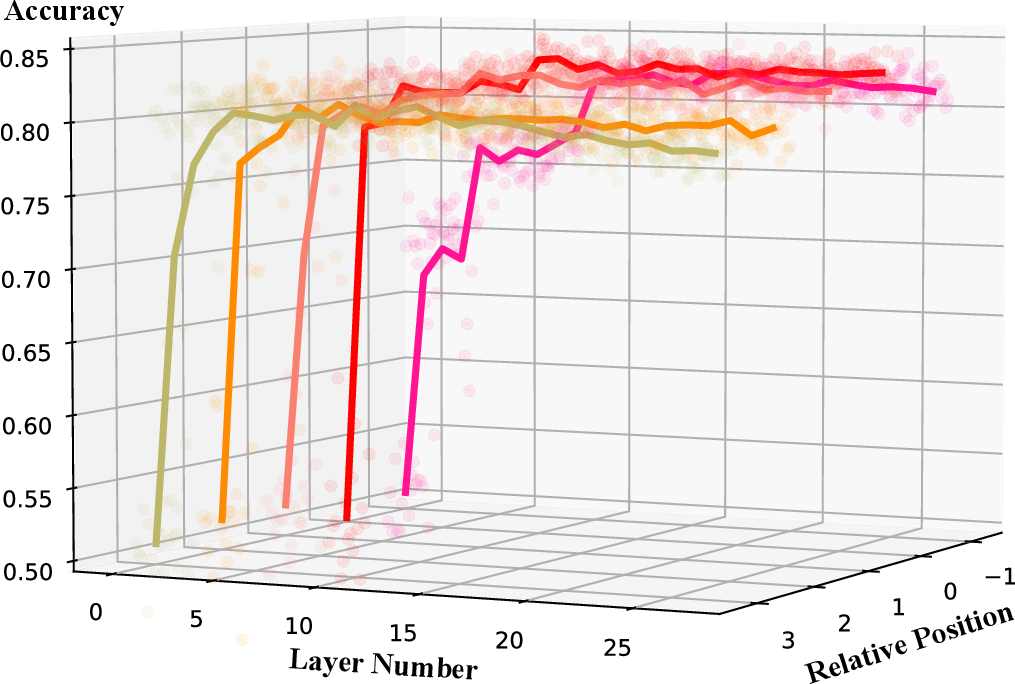
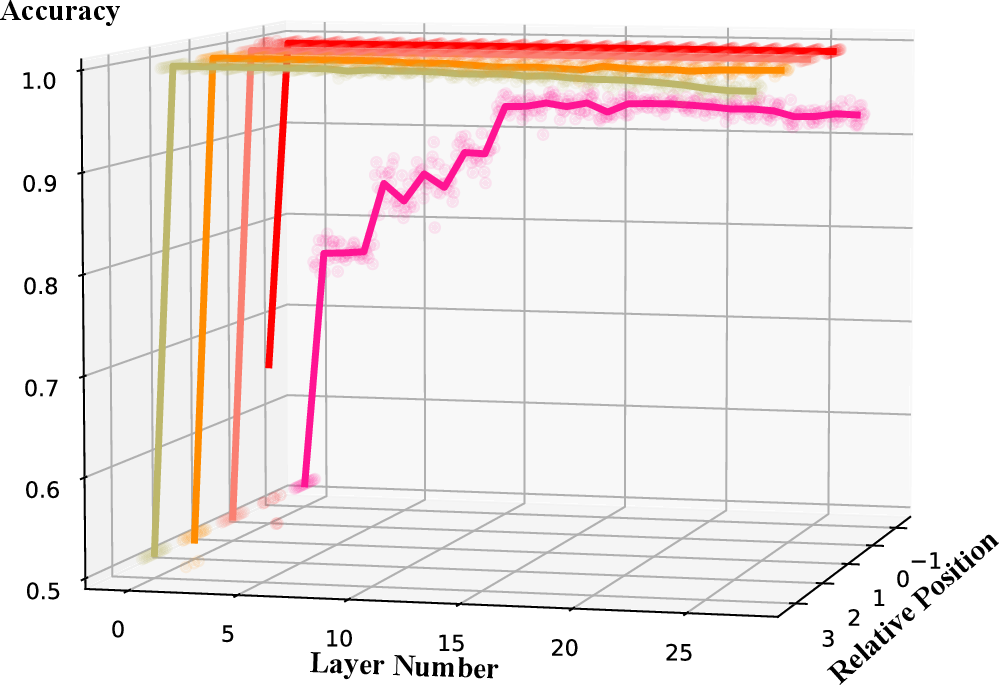
Figure 4: Predicting argmaxoP(o∣xi) with key vectors further highlights the interpretive alignment between intermediate representations and the kernel regression formalism.
- Feature Localization: Ridge regression analyses of key and value vectors indicate that at high-attention positions, value vectors accurately encode label information (yi), while key vectors capture sufficient information to reconstruct LLM predictions for xi. This operationalizes the analogy between kernel regression components and attention mechanisms.
Insights into ICL Phenomena
The kernel regression framework explains several empirical phenomena in ICL:
- Sample Retrieval: The boost in ICL performance from retrieving demonstrations similar to the query is mapped to the principle of local averaging in kernel regression, where a narrow bandwidth yields improved, unbiased estimates.
- Format Sensitivity: Sensitivity of ICL to output/label formats is attributed to the reliance on label token aggregation. If formats misalign, the prototype aggregation in kernel regression is corrupted.
- Distributional Effects: The necessity for demonstrative samples to be in-distribution and representative is quantitatively explained by the convergence error term, which grows if demonstrations are drawn from irrelevant or out-of-distribution tasks.
However, some phenomena—notably, ordering effects and robustness to random/perturbed labels—remain unaccounted for in the present framework, indicating that additional algorithmic or linguistic mechanisms are also at play in LLMs.
Task-Generalization and Explicit Regression Comparison
Explicit kernel regression using internal LLM features outperforms classic sentence encoder kernels and, on selected tasks, even matches or surpasses the original ICL accuracy. This implies that the emergent representations in LLMs are well-suited for non-parametric aggregation, and that the inductive bias imposed by architectures such as Transformers naturally supports kernel-like learning modalities during inference.
Implications for LLM Understanding and Future Research
This theoretical advance offers a partial but formal mechanistic understanding of in-context learning as kernel regression performed implicitly by pretrained attention heads over prompt-derived features. The implications are twofold:
- Practical: Enhancements in ICL (e.g., selecting or synthesizing prompt examples, controlling output format) can be guided by the behavior of kernel regression estimators, including sample similarity and representativeness criteria.
- Theoretical: The empirical congruency between attention and kernel regression substantiates a functional abstraction for reasoning about prompt-based learning in LLMs and bridges prior work on Bayesian and algorithmic explanations for ICL. Conversely, the framework’s limitations point toward open research problems concerning reordering sensitivity and meta-cognitive aspects of LLMs.
Conclusion
This work elucidates a kernel regression view of in-context learning in LLMs, supported both by formal derivation and rigorous empirical study of attention and hidden state dynamics. While the kernel regression framework captures a significant mode of emergent ICL behavior, further research is warranted to fully account for unmodeled aspects such as sensitivity to demonstration order and robustness to label perturbations. Overall, the kernel regression lens enhances interpretability and guides both practical deployment and theoretical development in foundation model research.