Token-Level Fitting Issues of Seq2seq Models
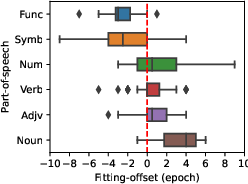
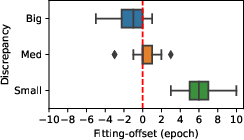
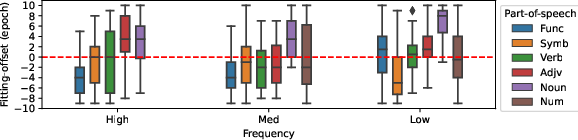
Abstract: Sequence-to-sequence (seq2seq) models have been widely used for natural language processing, computer vision, and other deep learning tasks. We find that seq2seq models trained with early-stopping suffer from issues at the token level. In particular, while some tokens in the vocabulary demonstrate overfitting, others underfit when training is stopped. Experiments show that the phenomena are pervasive in different models, even in fine-tuned large pretrained-models. We identify three major factors that influence token-level fitting, which include token frequency, parts-of-speech, and prediction discrepancy. Further, we find that external factors such as language, model size, domain, data scale, and pretraining can also influence the fitting of tokens.
- A closer look at memorization in deep networks. In Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 233–242. PMLR.
- Mohammad Mahdi Bejani and Mehdi Ghatee. 2021. A systematic review on overfitting control in shallow and deep neural networks. Artificial Intelligence Review, 54(8):6391–6438.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Jason Brownlee. 2018. Better deep learning: train faster, reduce overfitting, and make better predictions. Machine Learning Mastery.
- Satrajit Chatterjee and Piotr Zielinski. 2022. On the generalization mystery in deep learning. arXiv preprint arXiv:2203.10036.
- Wilfrid J Dixon and Alexander M Mood. 1946. The statistical sign test. Journal of the American Statistical Association, 41(236):557–566.
- Frage: Frequency-agnostic word representation. Advances in neural information processing systems, 31.
- The elements of statistical learning: data mining, inference, and prediction, volume 2. Springer.
- Joseph L Hodges. 1955. A bivariate sign test. The Annals of Mathematical Statistics, 26(3):523–527.
- Jacob Devlin Ming-Wei Chang Kenton and Lee Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL-HLT, pages 4171–4186.
- Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
- Tom Kocmi and Ondřej Bojar. 2017. Curriculum learning and minibatch bucketing in neural machine translation. In Proceedings of the International Conference Recent Advances in Natural Language Processing, RANLP 2017, pages 379–386.
- Moses: Open source toolkit for statistical machine translation. In Proceedings of the 45th annual meeting of the association for computational linguistics companion volume proceedings of the demo and poster sessions, pages 177–180.
- Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880.
- Research on overfitting of deep learning. In 2019 15th International Conference on Computational Intelligence and Security (CIS), pages 78–81. IEEE.
- Train big, then compress: Rethinking model size for efficient training and inference of transformers. In International Conference on Machine Learning, pages 5958–5968. PMLR.
- Multilingual denoising pre-training for neural machine translation. Transactions of the Association for Computational Linguistics, 8:726–742.
- Selective attention for context-aware neural machine translation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 3092–3102.
- Competence-based curriculum learning for neural machine translation. In Proceedings of NAACL-HLT, pages 1162–1172.
- David MW Powers. 1998. Applications and explanations of zipf’s law. In New methods in language processing and computational natural language learning.
- On long-tailed phenomena in neural machine translation. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3088–3095.
- Overfitting in adversarially robust deep learning. In International Conference on Machine Learning, pages 8093–8104. PMLR.
- Neural machine translation of rare words with subword units. arXiv preprint arXiv:1508.07909.
- A normalized encoder-decoder model for abstractive summarization using focal loss. In Natural Language Processing and Chinese Computing: 7th CCF International Conference, NLPCC 2018, Hohhot, China, August 26–30, 2018, Proceedings, Part II 7, pages 383–392. Springer.
- Machine translation using deep learning: An overview. In 2017 international conference on computer, communications and electronics (comptelix), pages 162–167. IEEE.
- Complex structure leads to overfitting: A structure regularization decoding method for natural language processing. arXiv preprint arXiv:1711.10331.
- Dusan Varis and Ondřej Bojar. 2021. Sequence length is a domain: Length-based overfitting in transformer models. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 8246–8257.
- Attention is all you need. Advances in neural information processing systems, 30.
- Robert Wolfe and Aylin Caliskan. 2021. Low frequency names exhibit bias and overfitting in contextualizing language models. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 518–532.
- Dynamic curriculum learning for low-resource neural machine translation. In Proceedings of the 28th International Conference on Computational Linguistics, pages 3977–3989.
- Rare tokens degenerate all tokens: Improving neural text generation via adaptive gradient gating for rare token embeddings. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 29–45.
- Understanding deep learning requires rethinking generalization. In International Conference on Learning Representations.
- Understanding deep learning (still) requires rethinking generalization. Communications of the ACM, 64(3):107–115.
- Deep neural networks in machine translation: An overview. IEEE Intell. Syst., 30(5):16–25.
- An empirical exploration of curriculum learning for neural machine translation. arXiv preprint arXiv:1811.00739.
- Uncertainty-aware curriculum learning for neural machine translation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 6934–6944.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

