- The paper reveals that text-to-image models exhibit significant biases, with DALLE-v2 favoring white male figures and Stable Diffusion showing a gender tilt towards females.
- It quantifies representational bias by comparing image outputs with real-world labor statistics, highlighting disparities in occupation portrayal.
- The paper evaluates prompt expansion strategies, noting that while they can introduce diversity, they often degrade image quality and fail to fully mitigate bias.
Detailed Summary of "Social Biases through the Text-to-Image Generation Lens"
This essay provides an in-depth analysis of the biases present in Text-to-Image (T2I) models, specifically examining the popular models DALLE-v2 and Stable Diffusion. The paper investigates how these models reflect social biases across different demographic dimensions, such as gender, race, age, and geographical location, when generating images based on text prompts. The analysis highlights significant representational biases, showcasing how such biases can be measured, and suggests mitigation strategies while recognizing their limitations.
Analysis of Social Biases in T2I Models
The study reveals that both DALLE-v2 and Stable Diffusion exhibit significant biases across gender, race, and age when neutral prompts, like "person," are used. For instance, DALLE-v2 tends to generate predominantly white male figures, while Stable Diffusion shows a gender bias towards female images.
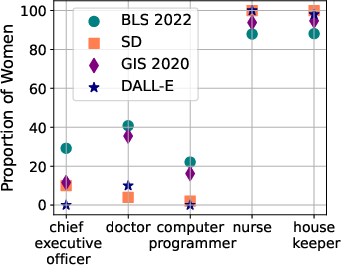
Figure 1: Gender representation for DALLE-v2, Stable Diffusion, Google Image Search 2020, and BLS data.
This indicates that each model, despite its capabilities in generating photorealistic images, inherently reflects and sometimes amplifies existing societal biases present in the training datasets.
Representational Bias in Occupations
The findings point out a severe imbalance in gender representation for various occupations when comparing generated images to real-world data, such as labor statistics from the U.S. Bureau of Labor Statistics (BLS). Occupations that are traditionally male-dominated, like CEO or computer programmer, often fail to include adequate representations of women in the generated outputs.
Figure 2: Quantifying representational fairness of Text-to-Image models on occupations, personality traits, and everyday situations.
Moreover, expansions of prompts to include gender, race, or age modifiers sometimes fail to correct these biases. For example, prompts aiming to specify a "female" or "black" occupation often still produce images largely of another demographic, thus questioning the robustness of prompt engineering as a bias mitigation technique.
Evaluation of Prompt Expansion and Image Quality
The study assesses the limitations of using expanded prompts as a mitigation strategy. Although including specific identifiers (e.g., "female doctor," "black engineer") can introduce some diversity, it often doesn't fully resolve the core bias issues. Furthermore, the discrepancy in image quality becomes apparent with expanded prompts, where certain racial or gender prompts lead to lower quality outputs even when the demographic is accurately represented in the image.
Bias in Everyday Situations and Geographical Implications
The analysis extends into geographically related everyday situations, where defaults even out and closely resemble Western scenarios. Countries from the Global South, like Nigeria and Ethiopia, are frequently found to be underrepresented or portrayed inaccurately compared to prompts featuring Western countries.
Conclusion
The paper concludes that while advancements in T2I models support user creativity and efficiency, significant improvements are necessary to address inherent biases in these systems. The findings highlight the complexity of bias in AI-generated content and the need for more nuanced mitigation strategies that go beyond simple prompt modifications. The study serves as a critical touchstone for future research aiming to achieve fairer AI models that genuinely represent a diverse range of human demographics and scenarios.