- The paper demonstrates that VALL-E redefines TTS synthesis by leveraging neural codec language models for zero-shot capabilities, outperforming existing systems.
- It employs an autoregressive model for initial acoustic token prediction followed by a non-autoregressive decoder for efficient multi-layer token generation.
- VALL-E nearly matches ground-truth quality on CMOS and SMOS metrics, evidencing its potential for personalized and robust speech synthesis.
Neural Codec LLMs for Zero-Shot Text to Speech
Introduction
The paper "Neural Codec LLMs are Zero-Shot Text to Speech Synthesizers" presents VALL-E, a novel approach to text-to-speech (TTS) synthesis that leverages neural codec LLMs to achieve zero-shot TTS capabilities. This approach treats TTS as a conditional language modeling task by utilizing discrete codes from a neural audio codec model, significantly differing from the traditional method of relying on continuous signal regression via mel spectrograms. Aiming to overcome the challenges of generalization in TTS, particularly for unseen speakers, the paper explores a large-scale data-driven method inspired by advancements in text synthesis.
VALL-E Architecture
VALL-E is a conditional codec LLM built upon neural audio codecs. The architecture consists of two main components: an autoregressive (AR) LLM for the first layer of acoustic tokens and a non-autoregressive (NAR) LLM for the subsequent layers. The codec models transform input phonemes into discrete acoustic tokens, with the model learning from a varied dataset of approximately 60,000 hours of English speech.
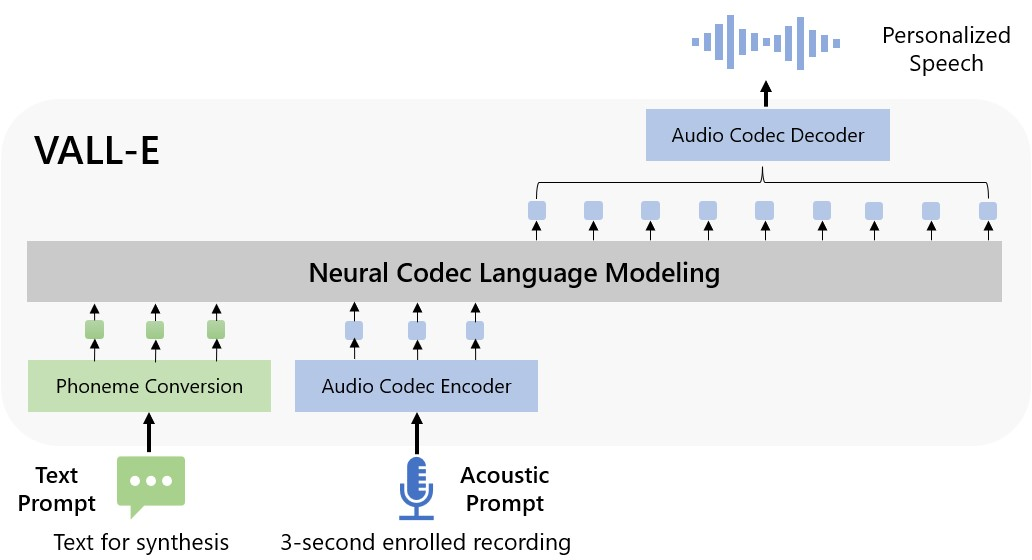
Figure 1: The overview of VALL-E. Unlike the previous pipeline (e.g., phoneme → mel-spectrogram → waveform), the pipeline of VALL-E is phoneme → discrete code → waveform.
Conditional Codec Language Modeling
Autoregressive and Non-Autoregressive Components
The AR component handles the prediction of the first layer of quantized acoustic tokens, conditioned on both phoneme sequences and a brief acoustic prompt. This section is crucial for determining phoneme-to-acoustic code alignment. The NAR component relies on the AR output to predict subsequent layers of acoustic tokens, improving efficiency and reducing computational complexity. The embedding of both components provides a hierarchical representation of acoustic tokens, enhancing model output quality.
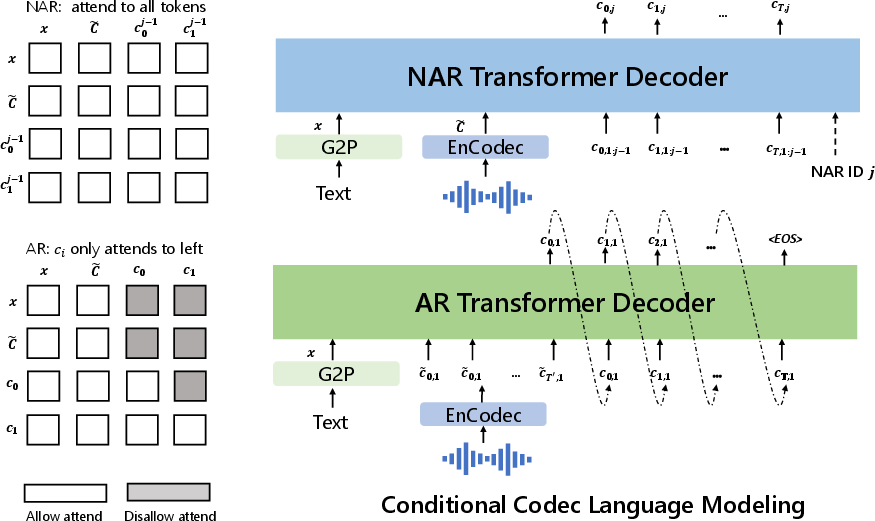
Figure 2: The structure of the conditional codec language modeling, which is built in a hierarchical manner. In practice, the NAR decoder will be called seven times to generate codes in seven quantizers.
Experimentation and Evaluation
The comparative performance of VALL-E against existing TTS systems is evaluated on LibriSpeech and VCTK datasets. VALL-E demonstrates superior speech naturalness and speaker similarity, reflected by higher CMOS and SMOS scores compared to YourTTS, the state-of-the-art zero-shot TTS system. Furthermore, VALL-E nearly matches ground truth in these metrics on unseen speakers, emphasizing its robust zero-shot learning capability.
In-Context Learning via Prompting
VALL-E exhibits strong in-context learning by effectively synthesizing speech from a short acoustic prompt. It maintains speaker-specific nuances like emotion and acoustic environment without additional fine-tuning or structural modifications. This achievement is particularly significant in TTS research, as it provides diverse outputs from the same input and maintains speaker individuality even in challenging scenarios.
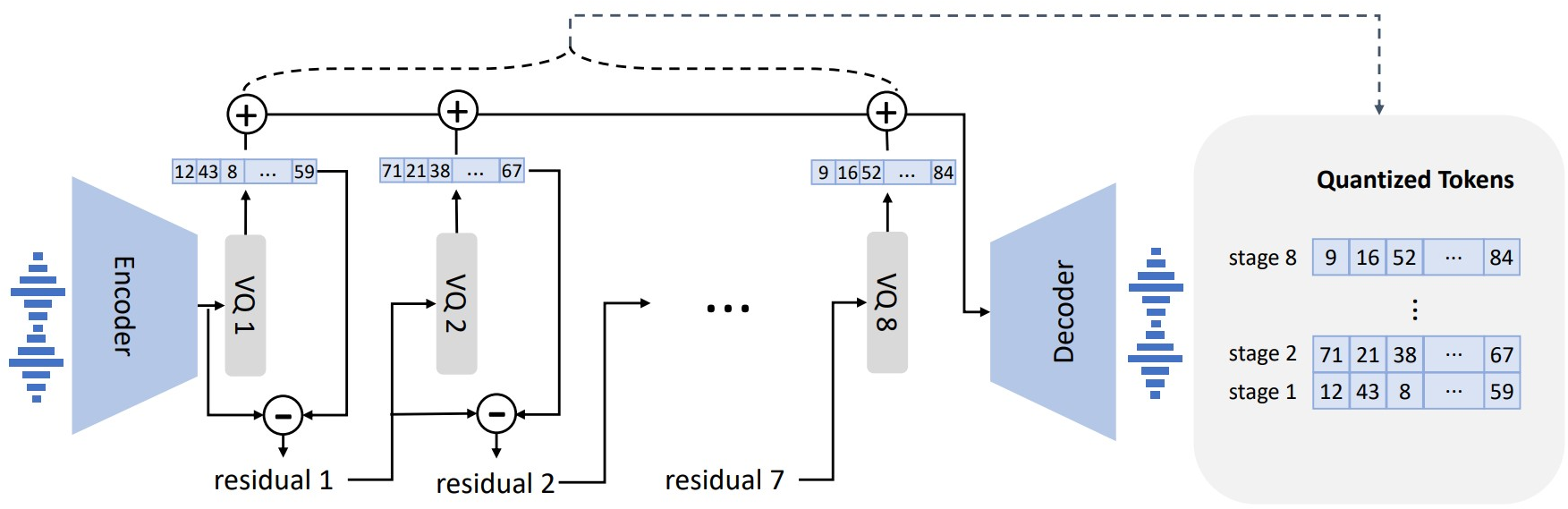
Figure 3: The neural audio codec model revisit. Because RVQ is employed, the first quantizer plays the most important role in reconstruction, and the impact from others gradually decreases.
Implications and Future Directions
The implications of VALL-E extend to various speech synthesis applications, including personalized TTS systems, voice cloning, and audio content creation. Future directions include addressing robustness issues in word articulation during synthesis, enhancing data diversity, and exploring a full-scale non-autoregressive model approach.
Conclusion
VALL-E introduces a transformative method for TTS by redefining traditional paradigms with neural codec LLMs. It capitalizes on large-scale datasets and in-context learning to achieve impressively high-quality synthesis in zero-shot scenarios, strongly outperforming previous methods. Continued improvements and extensions of this work hold promising potential for the future of speech synthesis research and application development.