- The paper introduces Adaptive Weight Decay, a dynamic strategy that adjusts the weight decay parameter to balance cross-entropy and regularization gradients.
- It achieves up to 20% relative improvements in robust accuracy on datasets such as CIFAR-10, CIFAR-100, and Tiny ImageNet by mitigating adversarial overfitting.
- The approach reduces weight norms, indicating potential benefits for model pruning and enhanced robustness against noisy labels.
Improving Robustness with Adaptive Weight Decay
Introduction
The paper introduces Adaptive Weight Decay (AWD), a novel method aimed at enhancing the robustness of Deep Neural Networks (DNNs). The approach dynamically adjusts the weight decay hyper-parameter during training, targeting improvements in adversarial robustness without necessitating additional data. The method leverages the balance between classification loss updates and regularization term strength, specifically impacting tasks vulnerable to robust overfitting, such as adversarial training.
Adversarial Training and Robust Overfitting
Adversarial training is a cornerstone strategy for defending against adversarial attacks. It involves augmenting the training dataset with adversarial examples, generated dynamically, to fortify the model's resistance. However, this process often encounters robust overfitting, where models perform well on training adversarial examples but degrade on unseen data.
Weight decay is typically utilized to mitigate overfitting by penalizing large weight values. Yet, its impact is highly sensitive to the chosen hyper-parameter λwd. Small λwd values can lead to robust overfitting, while larger values can hinder the model's ability to fit data accurately.
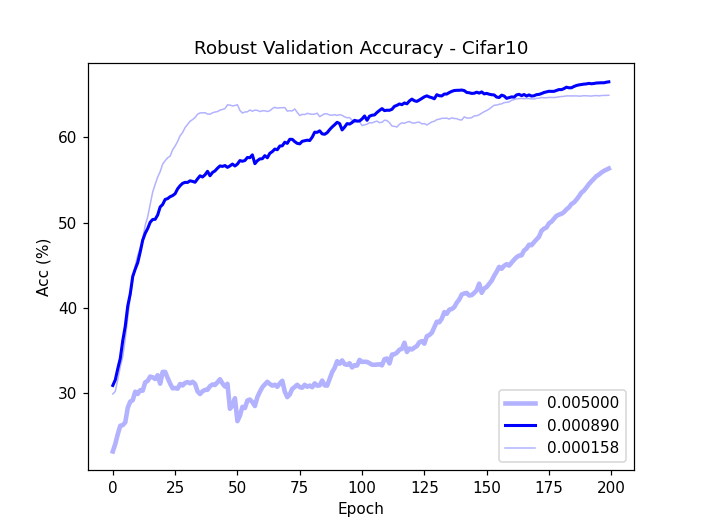
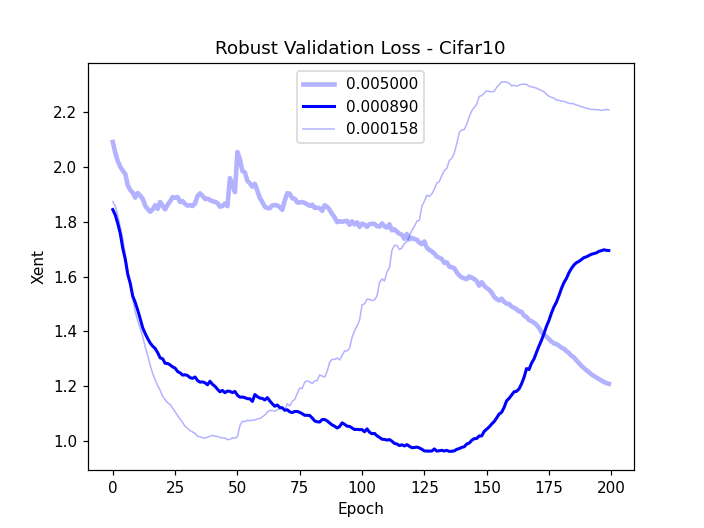
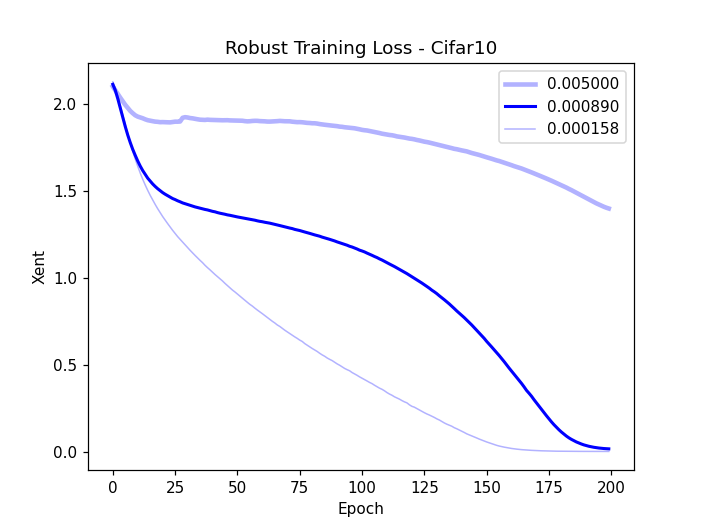
Figure 1: Robust validation accuracy (a) and validation loss (b) and training loss (c) on CIFAR-10 subsets, highlighting robust overfitting issues.
Adaptive Weight Decay
AWD seeks to dynamically adjust the weight decay parameter λwd to balance the effects of cross-entropy and weight decay gradients during training. This adaptive mechanism ensures that the regularization strength is modulated according to the gradient magnitudes, preventing premature convergence to poor minimums or narrowing excessively.
The key innovation here is the calculation of λawd, which maintains a constant ratio between weight decay and gradient magnitudes. This balance allows AWD to naturally navigate the trade-off between minimizing loss and controlling weight growth, thereby enhancing robustness.
Experimental Results
The experiments demonstrate significant improvements in robustness across various datasets, such as CIFAR-10, CIFAR-100, and Tiny ImageNet. AWD consistently surpasses traditional weight decay methods, achieving up to 20% relative improvements in robust accuracy.
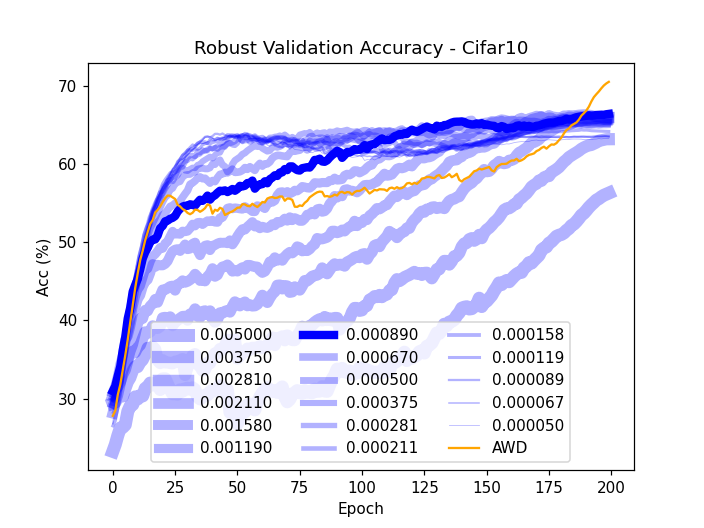
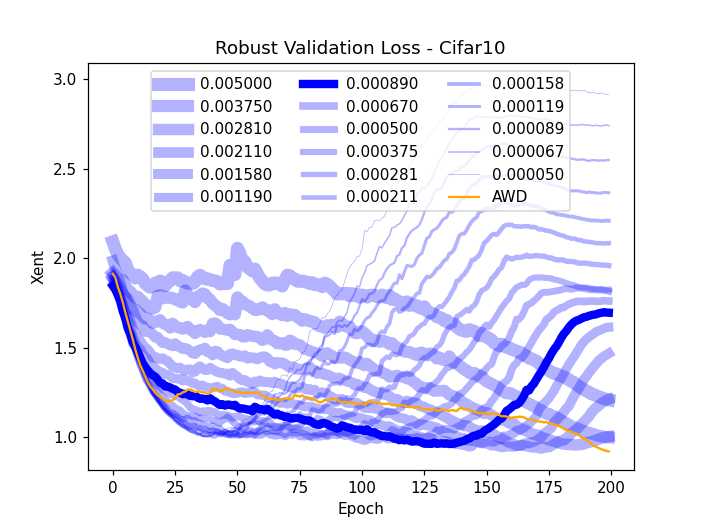
Figure 2: Robust accuracy (a) and loss (b) on CIFAR-10 validation subset, showing superior performance using AWD.
Furthermore, AWD-trained models exhibit smaller weight norms, suggesting potential benefits for model pruning and robustness to noisy labels. These findings indicate that AWD not only improves adversarial robustness but also enhances generalization on natural data.
Practical Implications and Future Directions
AWD's results underline its effectiveness in scenarios where tuning and balancing regularization parameters are paramount. Its applications are promising in real-world tasks involving noise and adversarial perturbations. Future work may explore AWD's integration with other optimization techniques and its potential for large-scale models, like those used in language processing.
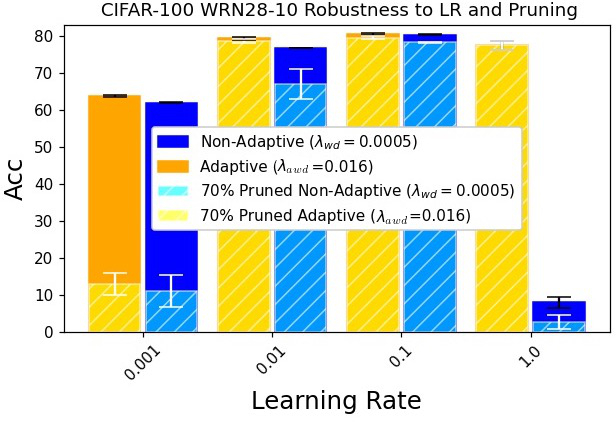
Figure 3: Illustration of the effects of AWD on model sensitivity to learning rates and pruning strategies.
Conclusion
Adaptive Weight Decay marks a substantial advancement in training robust DNNs. Its ability to dynamically modulate weight regularization provides a robust foundation for defending against adversarial threats while maintaining model performance on clean data. This approach is a notable step towards enhancing the reliability and stability of AI systems in adversarial environments.