- The paper introduces least-to-most prompting that decomposes complex semantic parsing tasks into manageable subproblems.
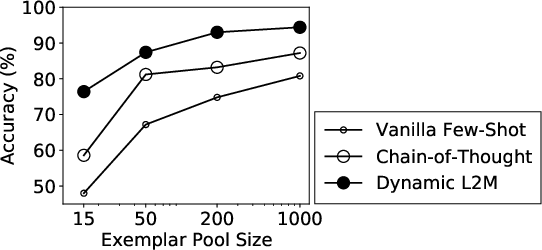
- It leverages dynamic exemplar selection to achieve state-of-the-art accuracies of 95% on CFQ and 99.2% on COGS using only 1% of training data.
- The approach significantly enhances compositional generalization in LLMs, promising applications in legal document analysis and complex query interpretation.
Compositional Semantic Parsing with LLMs
Introduction
The paper "Compositional Semantic Parsing with LLMs" (2209.15003) addresses the challenge of compositional generalization in semantic parsing by leveraging LLMs. Compositionality allows humans to understand infinite novel combinations of known components, a skill that standard neural models struggle with. The authors refine prompting techniques to enable LLMs to perform better on realistic semantic parsing tasks, particularly with a larger vocabulary and more complex grammars compared to previously simplified benchmarks like SCAN.
Methodology
Least-to-Most Prompting
The authors propose least-to-most prompting, a strategy that decomposes complex problems into sequences of simpler subproblems that can be solved incrementally:
Implementation Steps
- Syntactic Parsing: Using LLMs to predict phrase and clause structures that allow input decomposition. This step is crucial for enabling least-to-most prompting to handle natural language's syntactic complexity.
- Exemplar Pool Construction: By sampling around 1% of available data, a relevant subset is curated, ensuring diversity and coverage across potential decomposed structures.
- Subproblem Solution: By leveraging the decomposition, LLMs predict sequential solutions, supported by exemplars, yielding the final parse through an iterative, context-aware resolution.
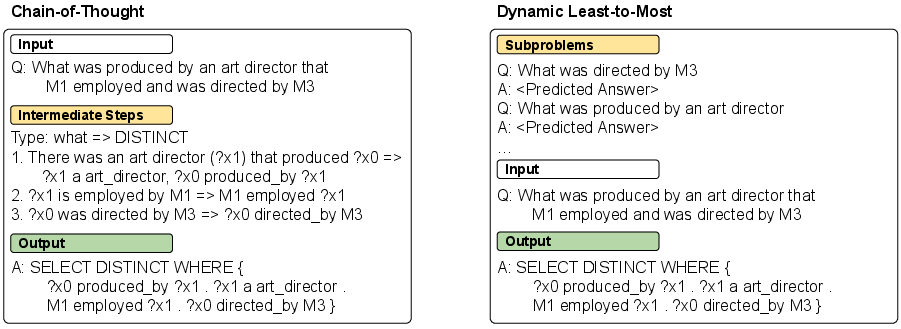
Figure 2: Prompt designs for semantic parsing. Chain-of-thought (left) generates intermediate steps before the final output. Dynamic least-to-most (right) first sequentially predicts solutions to subproblems before generating the final output.
Results
The approach achieves significant improvements on both the CFQ and COGS benchmarks:
Discussion
The dynamic least-to-most prompting method demonstrates that LLMs can excel at compositional tasks with minimal data by breaking down complex input and leveraging structured exemplar-driven prompting. This approach affirms that LLMs, when guided appropriately, can surpass specialized models that require extensive training.
The implications for real-world applications are significant, particularly for tasks demanding high precision in language parsing, such as legal document analysis or complex query interpretation. Future directions might explore integrating this approach with other domains requiring systematic generalization beyond language processing.
Conclusion
The paper successfully extends the applicability of LLMs for realistic semantic parsing tasks by introducing a hybrid approach that combines syntactic parsing with strategic exemplar selection. This advance demonstrates substantial gains in both performance and data efficiency, paving the way for broader deployments of LLMs in tasks necessitating compositional generalization.