- The paper introduces KEAR, a method that integrates external attention with self-attention to enhance commonsense reasoning and achieve human parity on CommonsenseQA.
- KEAR combines knowledge from ConceptNet, Wiktionary, and training data by concatenating external knowledge with input text to improve model performance.
- The approach achieves 89.4% accuracy on CommonsenseQA and demonstrates improvements across various Transformer-based encoders, indicating its broad applicability.
Achieving Human Parity on CommonsenseQA with External Knowledge Integration
This paper (2112.03254) introduces Knowledgeable External Attention for commonsense Reasoning (KEAR), a novel approach to enhance the performance of Transformer models in commonsense reasoning tasks. By augmenting the self-attention mechanism with external attention, KEAR leverages external knowledge sources to improve reasoning capabilities. The paper demonstrates that KEAR achieves human parity on the CommonsenseQA benchmark, surpassing previous state-of-the-art models.
Methodology: External Attention and Knowledge Integration
The KEAR framework enhances the self-attention mechanism of Transformer models by incorporating external knowledge. Instead of relying solely on the input data, KEAR retrieves related context and knowledge from external sources and integrates it into the model. This approach mimics human intelligence by utilizing external resources like search engines and dictionaries to navigate the world. The process involves concatenating relevant knowledge from external sources with the input text and feeding it into the Transformer model.
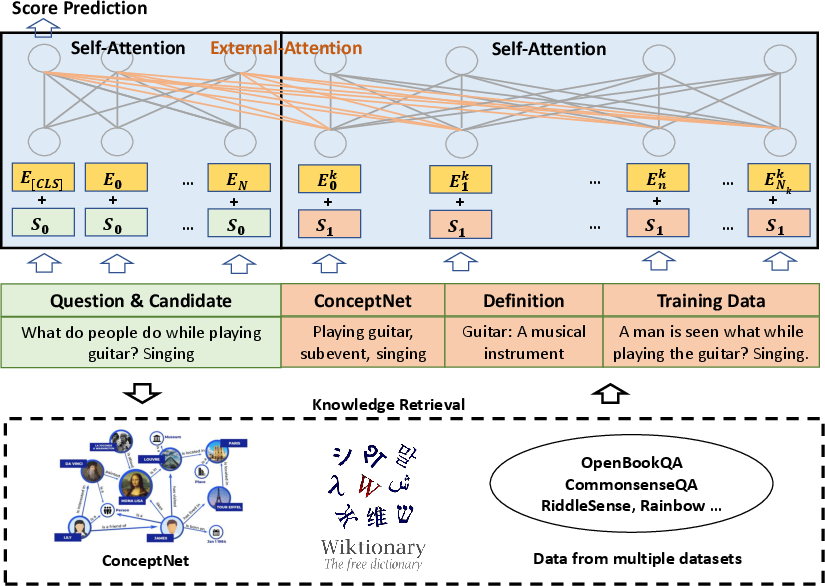
Figure 1: KEAR integrates retrieved knowledge from external sources with the input, leveraging text-level concatenation without altering the model architecture.
Specifically, the input to the first Transformer layer is modified as follows:
H0=[X;K]=[x1,...,xN,x1K,...,xNkK]
where X represents the input text, and K represents the external knowledge in text format. This concatenation allows the model to perform self-attention across both the input and the external knowledge, enhancing its reasoning capacity.
External Knowledge Sources: ConceptNet, Wiktionary, and Training Data
KEAR leverages three external knowledge sources to complement the input questions and choices.
- Knowledge Graph (ConceptNet): Relevant relation triples are retrieved from ConceptNet to provide curated facts for commonsense reasoning.
- Dictionary (Wiktionary): Definitions of key concepts from Wiktionary are used to provide accurate semantic explanations, especially for less frequent words.
- Training Data: Relevant questions and answers are retrieved from the training data to provide additional context and information.
The knowledge from these sources is concatenated to form a final knowledge input:
K=[KKG;Kdict;Ktrain]
where KKG, Kdict, and Ktrain represent the knowledge retrieved from the knowledge graph, dictionary, and training data, respectively.
Experimental Results: Achieving Human Parity
The paper presents empirical results on the CommonsenseQA benchmark, demonstrating that KEAR achieves human parity with an accuracy of 89.4\% on the test set, compared to human accuracy of 88.9\%. The results also show that each of the three external knowledge sources contributes to the performance improvement.
The authors experiment with various encoders, including ELECTRA, DeBERTa, and DeBERTaV3, and find that KEAR consistently improves the performance of these models. The best single model (DeBERTaV3-large + KEAR) achieves 91.2\% accuracy on the dev set. Furthermore, an ensemble of 39 models with KEAR reaches 93.4\% accuracy on the dev set.
Implications and Future Directions
The KEAR framework offers several practical benefits, including reduced dependence on large-scale models, computationally efficient knowledge retrieval methods, and easy adoption by existing systems. The success of KEAR suggests that integrating external knowledge is a promising direction for improving the reasoning capabilities of AI systems. Future research could explore other NLP tasks to improve LLM performance with external knowledge.

