Graph Partitioning and Sparse Matrix Ordering using Reinforcement Learning and Graph Neural Networks
Abstract: We present a novel method for graph partitioning, based on reinforcement learning and graph convolutional neural networks. Our approach is to recursively partition coarser representations of a given graph. The neural network is implemented using SAGE graph convolution layers, and trained using an advantage actor critic (A2C) agent. We present two variants, one for finding an edge separator that minimizes the normalized cut or quotient cut, and one that finds a small vertex separator. The vertex separators are then used to construct a nested dissection ordering to permute a sparse matrix so that its triangular factorization will incur less fill-in. The partitioning quality is compared with partitions obtained using METIS and SCOTCH, and the nested dissection ordering is evaluated in the sparse solver SuperLU. Our results show that the proposed method achieves similar partitioning quality as METIS and SCOTCH. Furthermore, the method generalizes across different classes of graphs, and works well on a variety of graphs from the SuiteSparse sparse matrix collection.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about a smarter way to split a big network (called a graph) into two balanced parts with as few connections between them as possible. The authors use machine learning—specifically reinforcement learning and graph neural networks—to do this. They also show how a related idea can help reorder large, sparse matrices so computers can solve them faster.
Key Questions
The paper asks:
- How can we divide a graph into two balanced groups while cutting the smallest number of connections between them?
- Can a learning “agent” figure out good splits by trying moves and getting rewards, instead of following fixed rules?
- Can this method work across different kinds of graphs, not just ones it trained on?
- Can we find special sets of nodes (vertex separators) that help reorder sparse matrices to speed up scientific computing?
Methods and Approach
Think of a graph like a social network: nodes are people and edges are friendships. Splitting the graph is like forming two teams:
- We want the teams to be about the same size.
- We want as few friendships as possible crossing between teams (to reduce “cut” edges).
Here’s how their method works:
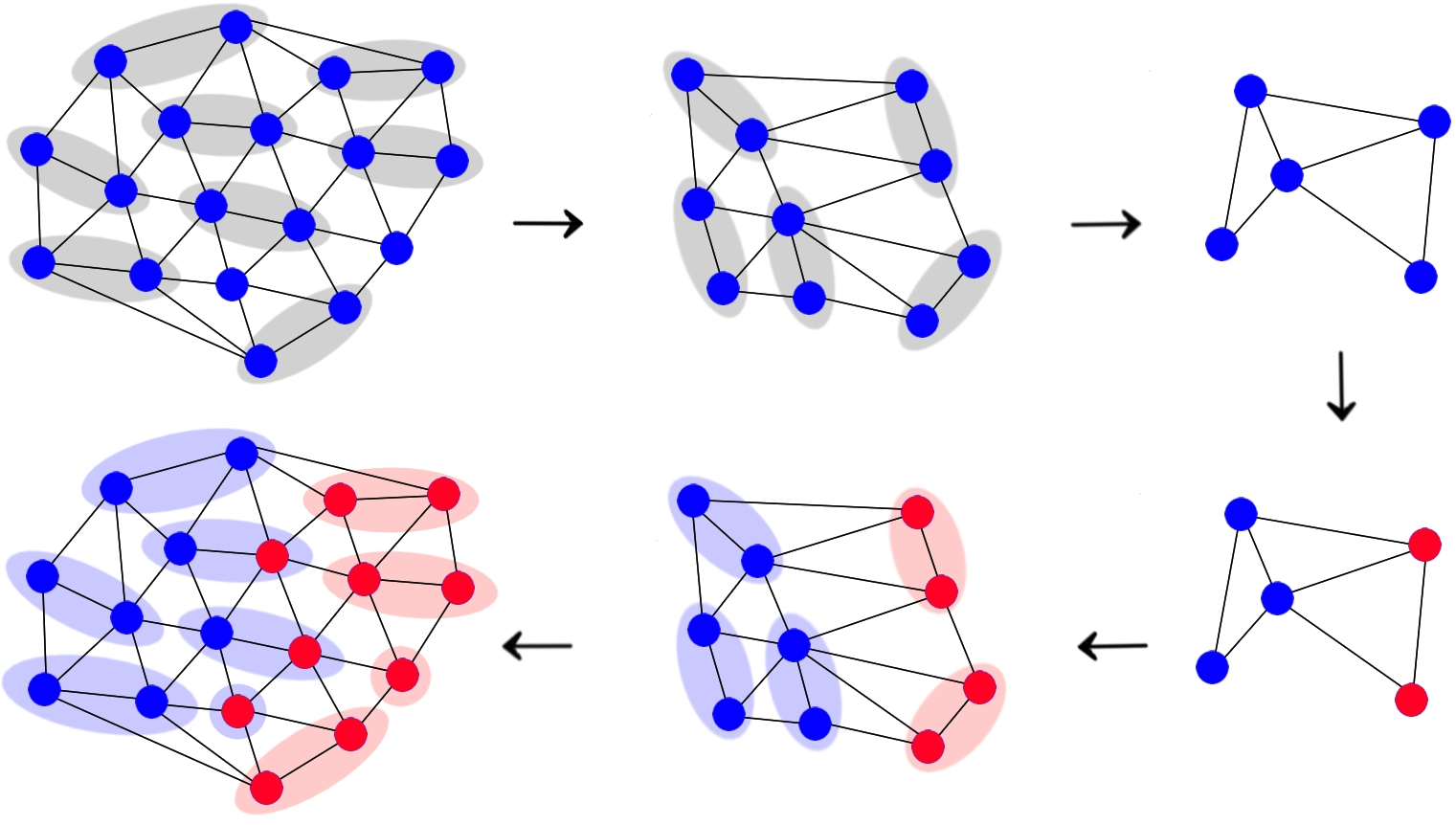
The multilevel idea: zoom out, split, then refine
- Coarsening: First, they make a simpler version of the graph by grouping nearby nodes together (imagine zooming out on a map so cities become regions). This reduces the number of nodes.
- Initial split: They split the simplest (coarsest) graph into two parts.
- Interpolation: They bring that split back to the original graph (zoom back in).
- Refinement: They adjust the border between the two parts near where the split happens to make it better.
Reinforcement learning (RL): learning by rewards
- An “agent” tries moving one node from one side to the other.
- After each move, it gets a reward based on whether the split improves.
- Over many tries, it learns which moves tend to help.
This is like teaching a player in a game to make good decisions by giving points for helpful moves. The agent uses an approach called A2C (Advantage Actor-Critic), which has:
- An “actor” that chooses actions (which node to move).
- A “critic” that estimates how good the current situation is.
Graph neural networks (GNNs): understanding connections
- The agent’s brain is a graph neural network with SAGEConv layers. These are designed for graphs and help the agent learn from both each node and its neighbors (like reading not just one person’s info, but also their friends’ info).
- The network learns to focus on the border (cut) area to save time, because that’s where small changes matter most.
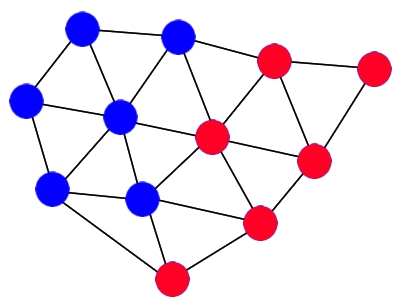
Edge separator vs. vertex separator
- Edge separator: Split the graph into two parts with few edges crossing between them (this is what most graph partitioners do).
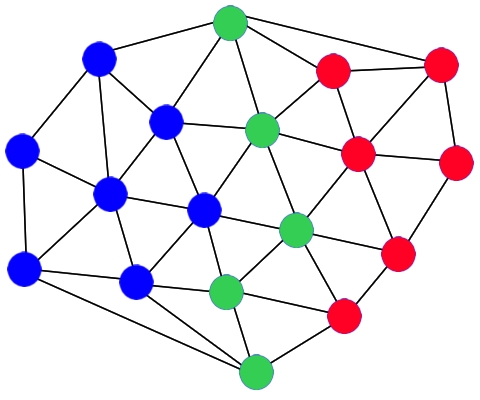
- Vertex separator: Remove a small set of nodes so the graph falls into two parts. This helps with “nested dissection,” a way to reorder rows/columns in a sparse matrix.
Nested dissection and sparse matrices
- Sparse matrices are big grids of numbers with lots of zeros. When solving them (for science and engineering simulations), the order of rows/columns matters.
- “Fill-in” means new non-zero entries appear during factorization (like LU). Too much fill-in makes solving slower.
- Using vertex separators to order the matrix reduces fill-in, speeding up solvers like SuperLU.
Main Findings
- Partition quality: Their method finds graph partitions that are about as good as two popular tools (METIS and SCOTCH) in terms of:
- Keeping parts balanced.
- Keeping the number of cut edges small.
- Minimizing “normalized cut” (a measure that balances cut size with how large each part is).
- Generalization: The learned model works well on different kinds of graphs, not just the ones it was trained on.
- Sparse matrix ordering: Using their vertex separators for nested dissection results in good orderings that reduce fill-in in the SuperLU solver.
- Efficiency: The approach suits modern hardware (like GPUs) because neural networks run efficiently there, and the refinement focuses only where it matters (near the cut).
Why This Matters
- Faster scientific computing: Better graph partitions and matrix orderings can make large simulations and data processing faster and more efficient, especially on supercomputers.
- Learning-based tools: Instead of relying only on hand-crafted rules, we can use learning agents to adapt to different graphs automatically.
- Scales to modern hardware: Deep learning methods can leverage GPUs and parallelism, which is useful for today’s high-performance computing.
- Potential for broader use: The same ideas might help solve other graph problems (like routing, scheduling, or network design) by teaching agents to make smart choices in complex systems.
In short, this paper shows that a well-trained learning agent, powered by graph neural networks, can match traditional graph partitioners and help speed up solving big scientific problems, all while being flexible across many kinds of graphs.
Collections
Sign up for free to add this paper to one or more collections.

