- The paper demonstrates that integrating multiple instance learning with a self-guided attention mechanism significantly improves anomaly detection accuracy.
- It introduces a pseudo label generator using sparse continuous sampling to mitigate noisy video-level labels.
- Experiments on benchmarks show a frame-level AUC of 94.83% on ShanghaiTech, highlighting enhanced model robustness and efficiency.
Introduction
The paper "MIST: Multiple Instance Self-Training Framework for Video Anomaly Detection" introduces the MIST framework aimed at addressing the challenges of video anomaly detection (VAD) in surveillance settings. VAD is a critical component of intelligent surveillance systems, particularly as the deployment of surveillance cameras continues to increase. The framework leverages weakly supervised learning to efficiently produce discriminative representations using only video-level annotations.
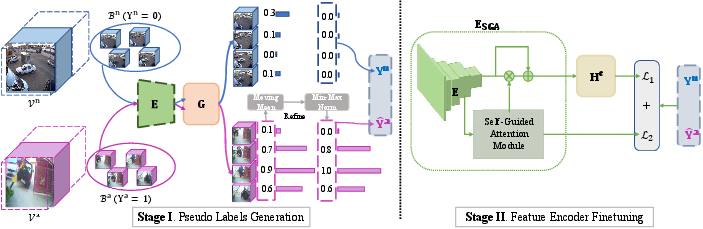
Figure 1: Illustration of our proposed MIST framework. MIST includes a multiple instance pseudo label generator G and self-guided attention boosted feature encoder ESGA.
Technical Approach
Multiple Instance Learning (MIL)
MIST deploys a multiple instance learning approach through a novel pseudo label generator designed to enhance the reliability of clip-level annotations in video data. The generator uses sparse continuous sampling to focus attention on contextually significant anomalous parts rather than isolated frames, mitigating the label noise common in methods that naively assign video-level labels to clips.
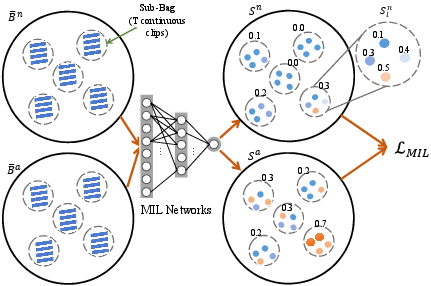
Figure 2: The workflow of our multiple instance pseudo label generator.
Self-Guided Attention Mechanism
The framework incorporates a self-guided attention mechanism within a feature encoder, ESGA. This module autonomously emphasizes anomalous regions in videos, allowing the encoder to focus on extracting relevant task-specific features without external annotations. The benefit of such an attention mechanism is highlighted by its ability to adaptively refine the anomaly detection process in complex surveillance video data.
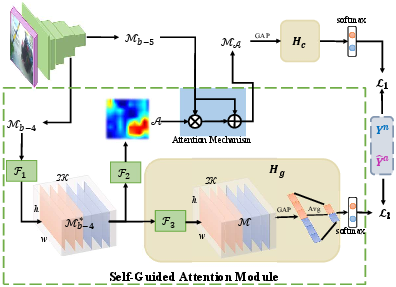
Figure 3: The structure of self-guided attention boosted feature encoder $E_{SGA}.
Experiments and Results
The efficiency and efficacy of the MIST framework are validated with extensive experiments on benchmark datasets, including UCF-Crime and ShanghaiTech. In particular, MIST achieves a frame-level AUC of 94.83% on the ShanghaiTech dataset, demonstrating its superiority over existing methods, both supervised and weakly supervised.
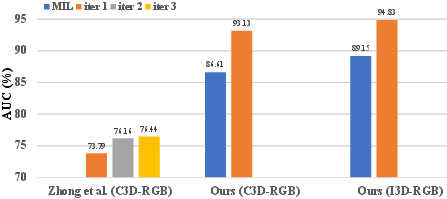
Figure 4: Comparisons with the state-of-the-art encoder-based method Zhong et al.
Feature Visualizations
To better understand the discriminative representation learning, feature space visualizations using t-SNE are conducted. These visualizations illustrate the refinements in feature encoding achieved through MIST's self-guided attention system compared to traditional encoder approaches.
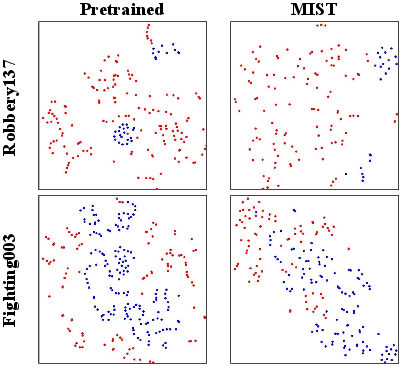
Figure 5: Feature space visualization of pretrained vanilla feature encoder I3D and the MIST fine-tuned encoder via t-SNE.
Ablation Studies
Ablation studies further corroborate the importance of each component of the MIST framework. Removing the pseudo label generator or self-guided attention module significantly degrades performance, underscoring their critical roles in enhancing anomaly detection capabilities. Experiments also reveal the improved model robustness provided by the sparse continuous sampling strategy within the MIL framework.
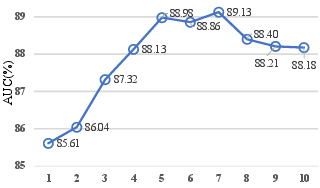
Figure 6: The effect of T for a fixed number of sub-bag 32 on ShanghaiTech dataset with $I3D{RGB}.
Conclusion
The MIST framework represents an important advancement in the field of video anomaly detection by successfully integrating self-training with MIL to train task-specific encoders. This combination leads to more accurate and reliable anomaly detection in video data using weak supervision. Future developments are likely to focus on refining pseudo label generation processes and optimizing encoder methods to further improve the efficiency and applicability of anomaly detection in various real-world scenarios.