- The paper’s main contribution is a systematic evaluation showing that most proposed Transformer modifications fail to outperform the well-calibrated baseline across tasks.
- The study employs controlled experiments with T5 transfer learning and WMT’14 translation to isolate the effects of changes like alternative activations and normalization techniques.
- It finds that deeper architectures and specialized models such as Mixture of Experts incur higher computational costs, underscoring the need for robust cross-setting validation.
The study presented in "Do Transformer Modifications Transfer Across Implementations and Applications?" explores the transferability of various architectural alterations made to the original Transformer model across different implementations and use cases. The prevailing sentiment that most proposed modifications have not been widely adopted prompted a comprehensive experimental evaluation. This essay elaborates on the methodology, results, and analytical observations from these experiments to address the inherent challenges of validating architectural improvements.
Methodology
The authors conducted systematic experiments applying numerous Transformer modifications in a unified experimental framework designed to accommodate common Transformer applications in NLP. The baseline, referred to as the "Vanilla Transformer," incorporated standard enhancements such as pre-layer normalization and relative attention with shared biases. The experiments utilized transfer learning via the T5 setup and supervised training on the WMT'14 English-German translation task to evaluate each modification's impact on performance. Notably, hyperparameters, models' parameter count, and computational budgets were conserved across the board to ensure fair comparisons.
Key Findings
The core finding of this research is that few architectural modifications provided measurable benefits over the baseline in terms of performance.
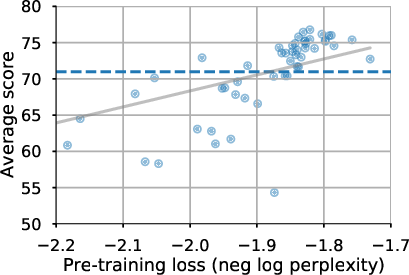
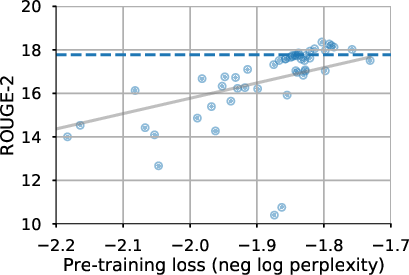
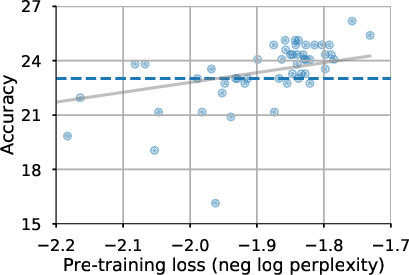
Figure 1: Relationship between perplexity and fine-tuned task quality. The x-axis measures the pre-training perplexity and the y-axis measures the score for each task, with each point representing an architecture variant. The dashed line shows baseline performance and the gray line is the line of best fit.
Activation Functions & Normalization
Alternative activations like SwiGLU and GeGLU outperformed the traditional ReLU activation across various tasks, demonstrating improvement in both pre-training and fine-tuning scenarios without additional computational load. RMS normalization emerged as a viable alternative to layer normalization, offering speed advantages alongside performance boosts.
Parameter Sharing and Layer Depth
The results indicate that deeper models generally outperform shallower counterparts at an equivalent parameter count, emphasizing the computational expense of depth increases. Notably, parameter sharing across layers diminished model performance, which aligns with observations from parameter tying experiments.
Architectural Variants
Novel architectures like Mixture of Experts and Switch Transformers demonstrated improvements but at the cost of increased parameter counts, highlighting compute vs. capacity trade-offs. Other complex modifications (e.g., dynamic convolutions, synthesizers) largely underperformed, unlike simple strategies or implementations optimized within the same codebase.
Conjectures and Recommendations
A central conjecture is that modifications often do not generalize due to implementation nuances and task-specific dependencies, suggesting that the original Transformer architecture was exceptionally well-calibrated or that proposed improvements lack robustness. This notion is underscored by the lack of broad adoption for many modifications despite claimed benefits in their respective proposals.
Recommendations for future researchers include validating architectural modifications across diverse codebases and tasks, maintaining consistent hyperparameter settings to assess true impact, and transparently reporting variability through statistical summaries. This approach will enhance the reproducibility of results and facilitate broad acceptance of potentially impactful innovations.
Conclusion
The paper concludes that while several enhancements show promise, many Transformer modifications fail to translate across varied settings due to sensitivity to specific implementations and task architectures. With informed practices around diversity in testing and robust evaluation protocols, future modifications may see increased adoption and efficacy in diverse environments. This work provides a roadmap for future architectural innovations in Transformer models to achieve these ends.