- The paper presents a novel deep complex convolution recurrent network (DCCRN) that integrates complex-valued layers for accurate modeling of both magnitude and phase.
- It combines convolutional encoder-decoders with complex LSTM layers to effectively capture temporal dependencies and separate speech from noise, achieving high PESQ scores.
- The model uses a complex ratio mask approach with SI-SNR loss, demonstrating competitive performance and low computational complexity in real-world noisy conditions.
DCCRN: Deep Complex Convolution Recurrent Network for Phase-Aware Speech Enhancement
The paper "DCCRN: Deep Complex Convolution Recurrent Network for Phase-Aware Speech Enhancement" introduces the Deep Complex Convolution Recurrent Network (DCCRN), specifically designed for single-channel speech enhancement. DCCRN aims to improve the perceptual quality and intelligibility of speech by leveraging complex-valued operations in both convolutional and recurrence-based architectures.
Introduction to Speech Enhancement Challenges
Speech enhancement is crucial for improving the quality and intelligibility of speech signals, especially when they are corrupted by noise. This task is particularly significant for applications like automatic speech recognition (ASR), where noise can lead to performance degradation. Traditional time-frequency (TF) based methods focus on estimating TF-masks or speech spectrums but often neglect phase information, which can limit the effectiveness of the enhancement process.
DCCRN Architecture
The proposed DCCRN combines the strengths of convolutional encoder-decoders (CED) and long short-term memory (LSTM) networks to effectively process complex-valued spectrograms. This approach allows both the convolutional and recurrent layers to use complex-valued operations, which are crucial for handling phase information in speech signals.
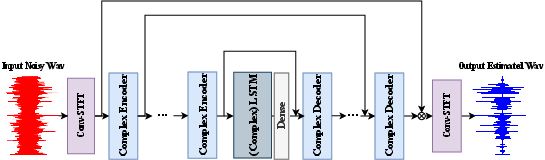
Figure 1: DCCRN network.
Complex Convolution and Recurrent Network
The DCCRN architecture employs complex convolutional layers as part of its encoder and decoder modules. These layers consist of complex-valued filters and use complex batch normalization, adhering to complex multiplication rules. This enables more accurate modeling of the correlation between the magnitude and phase of speech signals.
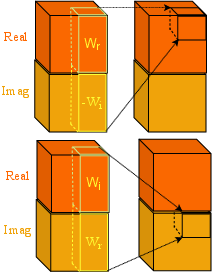
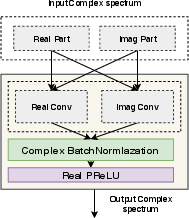
Figure 2: Complex module.
Integrating LSTM
Additionally, DCCRN utilizes complex LSTM layers to capture temporal dependencies, enhancing its capability to separate speech from noise efficiently. The integration of these complex-valued LSTMs is essential for improving the network's performance on both magnitude and phase components of speech.
Training Targets and Loss Function
DCCRN is trained using the complex ratio mask (CRM) approach, which reconstructs speech by enhancing real and imaginary components jointly. The network is optimized using a signal approximation (SA) loss, specifically the scale-invariant signal-to-noise ratio (SI-SNR), which has become a favored metric over traditional mean square error (MSE) due to its robustness in evaluating enhancement performance.
Experimental Results
The paper reports comprehensive experiments conducted on simulated datasets from WSJ0 and real-world data from the Interspeech 2020 DNS Challenge. The results demonstrate that DCCRN achieves higher Perceptual Evaluation of Speech Quality (PESQ) scores compared to baseline models, including LSTM and CRN.
On the DNS Challenge dataset, DCCRN models, with only 3.7 million parameters, showed competitive performance relative to other state-of-the-art networks, while maintaining lower computational complexity. Notably, the DCCRN model achieved the best Mean Opinion Score (MOS) in real-time track evaluations.
Conclusion
The DCCRN model represents a significant advancement in complex-valued speech enhancement networks. By efficiently integrating complex convolutional and recurrent layers, DCCRN addresses both magnitude and phase modeling, leading to improved performance. Future work may focus on deploying DCCRN in resource-constrained environments, enhancing speech quality in reverberant conditions, or further optimizing its structure for edge devices.