- The paper presents AdaHessian, a novel optimizer that adapts second-order Hessian estimation to overcome limitations of first-order methods.
- It employs Hutchinson's method, RMS exponential moving averages, and block diagonal averaging to stabilize curvature estimates with minimal overhead.
- Experimental results show improved performance in image classification, NLP BLEU scores, and recommendation systems compared to Adam and related optimizers.
AdaHessian: An Adaptive Second-Order Optimizer for Machine Learning
Introduction
The paper introduces AdaHessian, a novel second-order optimization algorithm designed specifically for machine learning tasks. The objective of AdaHessian is to overcome the limitations typically associated with first-order optimization methods such as SGD and Adam, which are commonly used in training NN models. The primary challenges these optimizers face include hyperparameter sensitivity and inefficiency due to ignorance of curvature information in the loss landscape. To address these issues, AdaHessian leverages adaptive Hessian-based preconditioning to normalize and optimize the learning process efficiently.
Approach and Methodology
The core innovation of AdaHessian lies in three computational strategies:
- Hessian Diagonal Approximation:
AdaHessian employs a Hutchinson-based method to approximate the curvature matrix, allowing the capture of essential second-order information without significant computational overhead. This approximation results in the Hessian being treated as a diagonal operator, which simplifies computation.
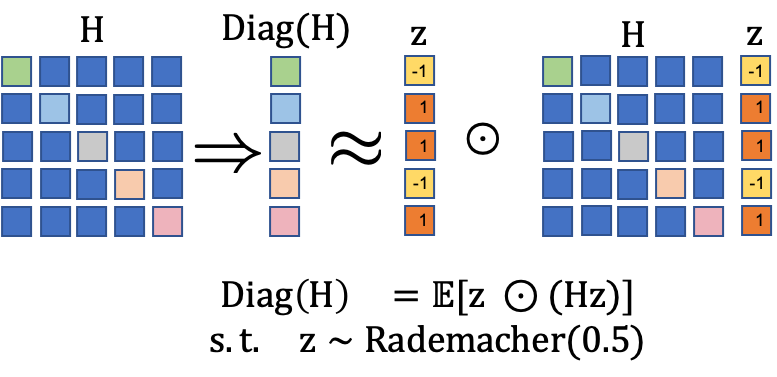
Figure 1: Illustration of the diagonal Hessian estimation with Hutchinson's method.
- Root-Mean-Square Exponential Moving Average:
To smooth out variations of the Hessian diagonal across different iterations, AdaHessian incorporates an RMS-based exponential moving average technique. This approach mitigates issues caused by noisy local curvature estimates, as illustrated by local versus global curvature analysis.
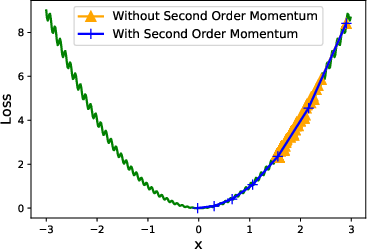
Figure 2: Local versus global curvature. Demonstrates local curvature's noise impact and the stabilizing effect of exponential moving averages.
- Block Diagonal Averaging:
Variance in the Hessian diagonal is further reduced through block diagonal averaging, a technique that averages selected blocks of parameters to provide more stable curvature estimates across spatial dimensions in NNs.
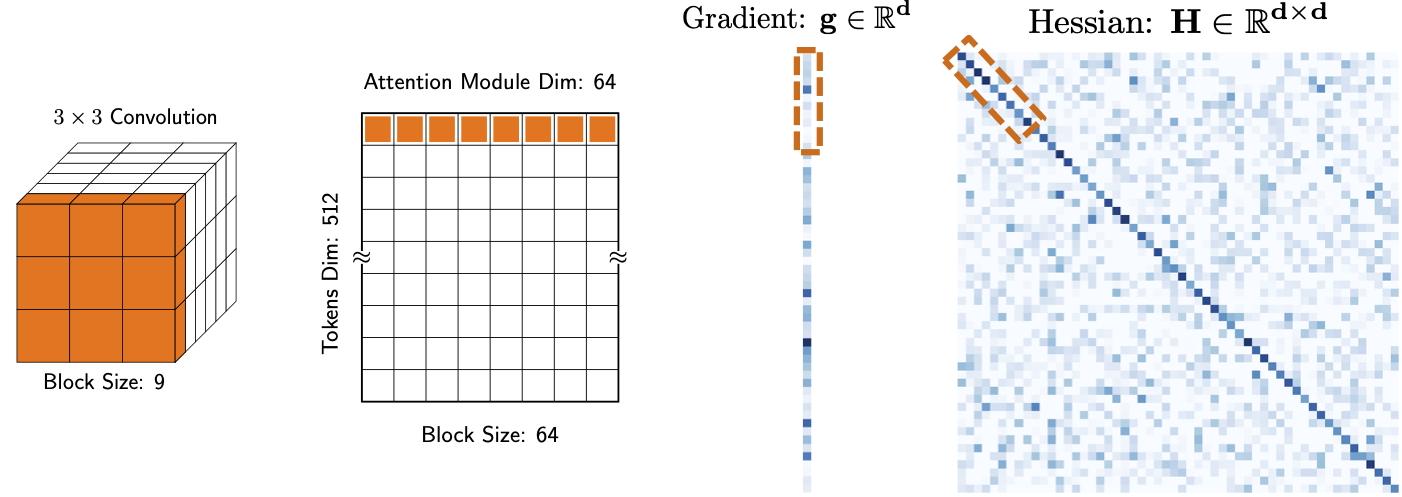
Figure 3: Block size averaging in AdaHessian reduces spatial variance in the Hessian diagonal.
Experimental Results
The efficacy of AdaHessian is demonstrated across a range of tasks including CV, NLP, and recommendation systems, outperforming existing optimization methods like Adam and AdamW:
- Image Classification:
- For Cifar10 and ImageNet datasets, AdaHessian achieves up to 1.80% higher accuracy on ResNets compared to Adam.
(Figure 4, Figure 5)
Figure 4: Gradient descent vs. AdaHessian on 2D function. Figure 5: Accuracy curves on Criteo dataset, indicating AdaHessian's performance advantage.
- Natural Language Processing:
- AdaHessian improves BLEU scores by margins of 0.13/0.33 on IWSLT14/WMT14 tasks.
- Recommendation Systems:
- Utilized in DLRM models on the Criteo Ad Kaggle dataset, AdaHessian improves accuracy by 0.032% over Adagrad, a notable enhancement in this field.
Implications and Future Work
The introduction of AdaHessian signifies a promising advancement in optimizing NN training efficiency and accuracy. The inclusion of second-order adaptations adjusts traditional learning paradigms, offering a robust alternative to prevalent methods with justifiable computational costs.
Technologically, the results suggest broad applicability and suggest further exploration into adaptive approaches that can leverage second-order insights without substantial computational trade-offs. Future developments could refine the existing model and further reduce overhead, increasing feasibility in industrial scale applications.
Conclusion
AdaHessian represents a significant contribution to the optimization landscape, effectively bridging gaps left by first-order methods through adaptive second-order techniques. Its robustness and efficiency across varied tasks underline the potential for broader adoption in ML, encouraging continued research into similar methodologies. The public availability of the AdaHessian code supports its integration within existing ML workflows, fostering innovation and exploration in complex optimization contexts.